MapReduce是什么
MapReduce是一种分布式计算编程框架,是Hadoop主要组成部分之一,可以让用户专注于编写核心逻辑代码,最后以高可靠、高容错的方式在大型集群上并行处理大量数据。
MapReduce的存储
MapReduce的数据是存储在HDFS上的,HDFS也是Hadoop的主要组成部分之一。下边是MapReduce在HDFS上的存储的图解
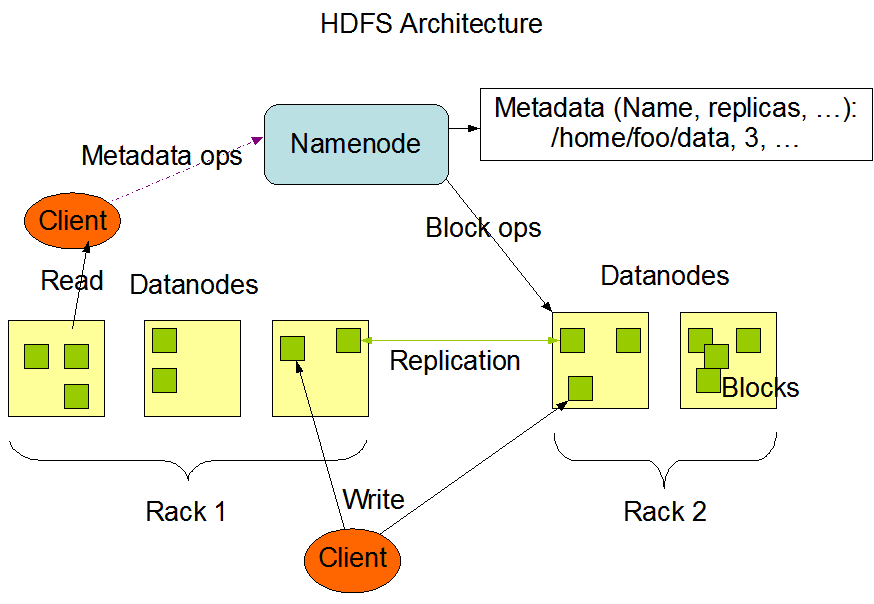
HDFS主要有Namenode和Datanode两部分组成,整个集群有一个Namenode和多个DataNode,通常每一个节点一个DataNode,Namenode的主要功能是用来管理客户端client对数据文件的操作请求和储存数据文件的地址。DataNode主要是用来储存和管理本节点的数据文件。节点内部数据文件被分为一个或多个block块(block默认大小原来是64MB,后来变为128MB),然后这些块储存在一组DataNode中。(这里不对HDFS做过多的介绍,后续会写一篇详细的HDFS笔记)
MapReduce的运行流程


1、首先把需要处理的数据文件上传到HDFS上,然后这些数据会被分为好多个小的分片,然后每个分片对应一个map任务,推荐情况下分片的大小等于block块的大小。然后map的计算结果会暂存到一个内存缓冲区内,该缓冲区默认为100M,等缓存的数据达到一个阈值的时候,默认情况下是80%,然后会在磁盘创建一个文件,开始向文件里边写入数据。
2、map任务的输入数据的格式是<key,value>对的形式,我们也可以自定义自己的<key,value>类型。然后map在往内存缓冲区里写入数据的时候会根据key进行排序,同样溢写到磁盘的文件里的数据也是排好序的,最后map任务结束的时候可能会产生多个数据文件,然后把这些数据文件再根据归并排序合并成一个大的文件。
3、然后每个分片都会经过map任务后产生一个排好序的文件,同样文件的格式也是<key,value>对的形式,然后通过对key进行hash的方式把数据分配到不同的reduce里边去,这样对每个分片的数据进行hash,再把每个分片分配过来的数据进行合并,合并过程中也是不断进行排序的。最后数据经过reduce任务的处理就产生了最后的输出。
4、在我们开发中只需要对中间map和reduce的逻辑进行开发就可以了,中间分片,排序,合并,分配都有MapReduce框架帮我完成了。
MapReduce的资源调度系统
最后我们来看一下MapReduce的资源调度系统Yarn。
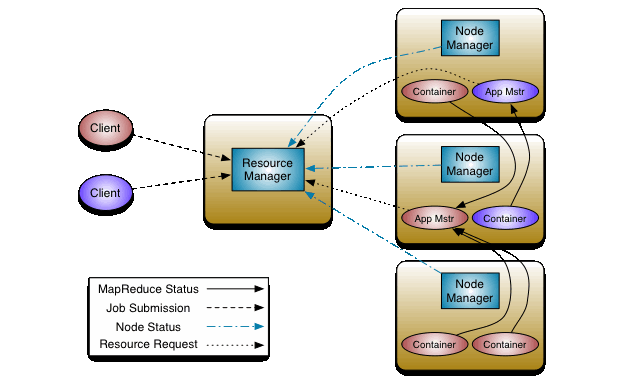
Yarn的基本思想是将资源管理和作业调度/监视的功能分解为单独的守护进程。全局唯一的ResourceManager是负责所有应用程序之间的资源的调度和分配,每个程序有一个ApplicationMaster,ApplicationMaster实际上是一个特定于框架的库,其任务是协调来自ResourceManager的资源,并与NodeManager一起执行和监视任务。NodeManager是每台机器框架代理,监视其资源使用情况(CPU,内存,磁盘,网络)并将其报告给ResourceManager。
WordConut代码
- python实现
map.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print('%s\t%s' % (word, 1))reduce.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
current_word = None
sum = 0
for line in sys.stdin:
word, count = line.strip().split(' ')
if current_word == None:
current_word = word
if word != current_word:
print('%s\t%s' % (current_word, sum))
current_word = word
sum = 0
sum += int(count)
print('%s\t%s' % (current_word, sum))我们先把输入文件上传到HDFS上去
hadoop fs -put /input.txt /? 然后在Linux下运行,为了方便我们把命令写成了shell文件
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar"
INPUT_FILE_PATH="/input.txt"
OUTPUT_FILE_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrush $OUTPUT_FILE_PATH
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_FILE_PATH \
-mapper "python map.py" \
-reducer "python reduce.py" \
-file "./map.py" \
-file "./reduce.py"
- java实现
MyMap.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text text = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word: words){
text.set(word);
context.write(text,one);
}
}
}
MyReduc