1.1 Hadoop
概念:hadoop是一个由Apache基金会所开发的分布式系统基础架构。是根据google发表的GFS(Google File System)论文产生过来的。
优点:
1. 它是一个能够对大量数据进行分布式处理的软件框架。以一种可靠、高效、可伸缩的方式进行数据处理。
2. 高可靠性,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
3. 高效性,因为它以并行的方式工作,通过并行处理加快处理速度。
4. 可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop组成:主要由两部分组成,一个是HDFS,一个是MapReduce。
1) 什么是HDFS(分布式文件系统)?
HDFS 即 Hadoop Distributed File System。首先他是一个开源系统,同时他是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统。是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
它分为两个部分:Name Node和Date Node,Name Node相当于一个领导,它管理集群内的Data Node,当客户发送请求过来后,Name Node会根据情况指定存储到哪些 Data Node上,而其本身自己并不存储真实的数据。那Name Node怎么知道集群内Data Node的信息呢?Data Node发送心跳信息给Name Node。(一会详见原理图)
2) HDFS 设计基础与目标
HDFS是基于流数据模式访问和处理超大文件的需求而开发的,可以运行与廉价的商业服务器上。
特点:
1. 通过流式数据访问;
2. 程序采用“数据就近”原则分配节点执行;
3. 对文件采用一次性写多次读的逻辑设计--文件一经写入、关闭,就再也不能修改;
4. 数据以快形式分布式存储在集群中不同的物理机中。
1.2 HDFS体系结构
1) 存储块
块(Block):操作系统中的文件块。文件是以块的形式存储在磁盘中,块的大小代表系统读、写可操作的最小文件大小。也就是说,文件系统每次只能操作磁盘块大小的整数倍数据。通常来说,一个文件系统块大小为几千字节,而磁盘块大小为512 字节。
HDFS中的块是一个抽象的概念,比操作系统中的块要大得多。在配置hadoop系统时会看到,它的默认大小是128MB。HDFS使用抽象的块的好处:可以存储任意大的文件而又不会受到网络中任一单个节点磁盘大小的限制;
使用抽象块作为操作的单元可以简化存储子系统。
2) 模块任务
1. Name node功能:
1) 承担master 管理集群中的执行调度;
2) 管理文件系统的命名空间,维护整个文件系统目录树以及这些文件的索引目录;
3) 不永久保存文件快信息,在系统启动时重加块信息;
4) 命名空间镜像(namespace)和编辑日志(Edit log)
2. Data node 功能:承担worker具体任务的执行节点
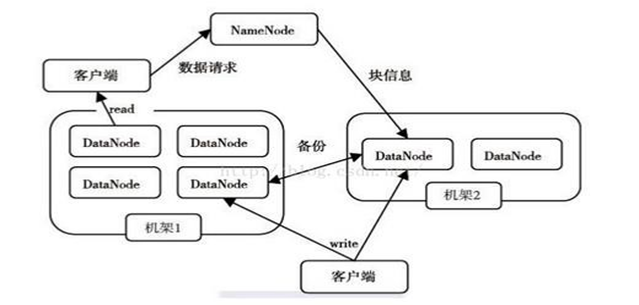
3) 集群管理
HDFS采用Master/Slave架构对文件系统进行管理。一个HDFS集群是由一个Name Node和一定数目的Data Node组成的。Name Node是一个中心服务器,负责管理文件系统的命名空间(Namespace)以及客户端对文件的访问。集群的Date Node一般是由一个节点运行一个Data Node进程,负责管理它所在节点上的存储。
从内部看,一个文件其实被分成了一个或多个数据块,这些块存储在一组Data Node上。Name Node执行文件系统的名字空间操作,比如打开,关闭,重命名文件或目录。它负责确定数据块到具体Data Node节点的映射。Data Node 负责处理文件系统客户端的读/写请求。在Name Node的统一调度下进行数据块的创建,删除和复制。
4) 读取策略
1)副本存放和读取策略
副本的存放是HDFS可靠性和性能的关键,优化的副本存放策略也正是HDFS区分于其他大部分分布式文件系统的重要特征。HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性,可用性和网络带宽的利用率上。在读取数据时,为了减少整体带宽消耗和降低整体的带宽延时,HDFS会尽量让读取程序读取离客户端最近的副本。
2)安全模式
Name Node启动后会进入一个称为安全模式的状态。处于安全模式的Name Node不会进行数据块的复制。Name Node从所有的Data Node接收心跳信号和块状态报告。
3)文件安全
Hadoop采用了两种方法来确保文件安全。第一种方法:将Name Node中的元数据转储到远程的NFS文件系统上;第二种方法:系统中同步运行一个Secondary Name Node。
这个节点的主要作用是周期性的合并日志中的命名空间镜像,以避免编辑日志过大。
HDFS安全模式有三种:
1. hdfs dfsa