基于关系代数理论:
缺点:表结构不直观,实现复杂,速度慢
优点:健壮性高、社区庞大,在一些情况下人们发现健壮性,并不是要求那么高,因而产生了十分流行的非关系型数据库,如Redis,Memcached等。
2.数据库表关系
下面以Product表和Category进行举例,Category表的主键为Product的外键,Category被称为主键表,Product被成为外键表,在关系型数据库中,有外键后数据的健壮性会提高。
使用数据库:MySQL5.5
Category表:

Product表:
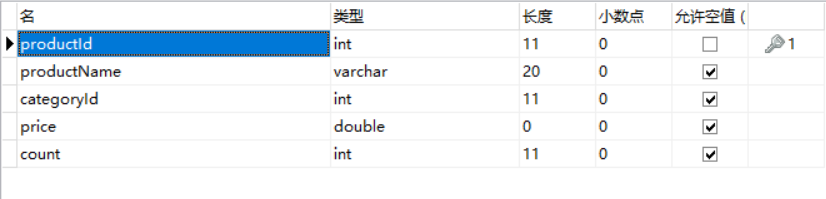
Product表数据:
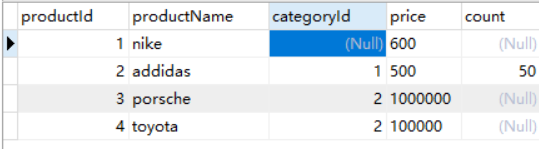
Category表数据:
3.join和group by
3.1 使用join
1 select * from product JOIN category 2 select * from product,category 3 --以上两种写法没有区别都会做笛卡尔积
执行结果:
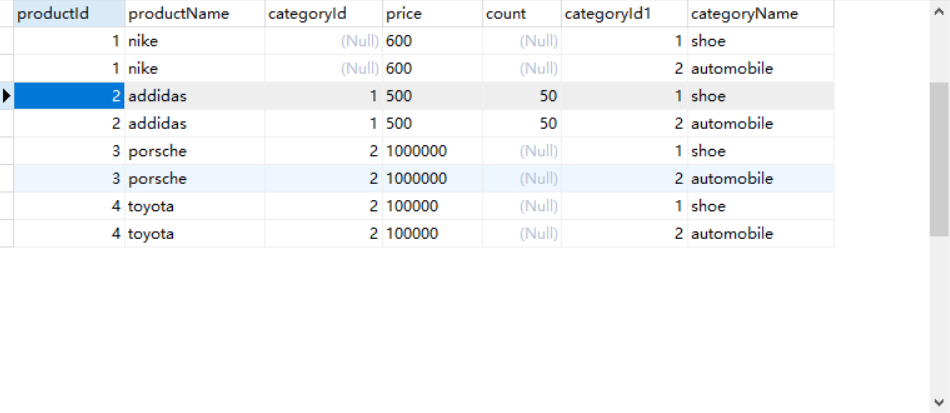

总共查出8条数据,实际上相当于做了一个笛卡尔积,product表四条记录,category表两条记录,最后结果就是8条记录。
3.2 使用join on(内连接)
使用join on就可以加上条件只把相等的记录展示出来。
1 SELECT * from product p JOIN category c ON p.categoryId = c.categoryId
执行结果:


使用内连接,数据库不会去做笛卡尔积再去选择,这样效率是非常低下的,比如阿迪达斯那条记录,数据库会去category表中去找到id等于1的记录,我们可以看到nike是没有categoryId,所以没有被显示出来,如果想要被显示出来,我们就要用外连接,left join(左外连接)
3.3 使用left join(左连接,以左表为主)
1 SELECT * from product p LEFT JOIN category c ON p.categoryId = c.categoryId
我们可以看到结果,nike位置上的categoryId为空,数据库就会放两个null进来,而内连接并不会显示null。
执行结果:


3.4 使用group by
查询每个类别下面有几个产品:
1 SELECT c.categoryId, COUNT(*) FROM category c LEFT JOIN product p on p.categoryId = c.categoryId 2 GROUP BY categoryId
使用group by方法之后,只能select分组这个字段和一些聚合函数,有一些工具不会报错,有一一些工具如果select其他字段就会报错。
执行结果:


对categoryId和categoryName进行分类
可以同时查出categoryId和categoryName.将nike的categoryId,对于两个表共同拥有的字段(categoryId)一定要标注出是哪个表的字段。
1 SELECT c.categoryId,c.categoryName, COUNT(*) FROM category c LEFT JOIN product p on p.categoryId = c.categoryId 2 GROUP BY c.categoryId, c.categoryName
运行结果:

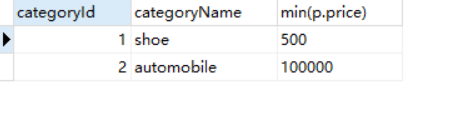
找出每个分类下最便宜商品的价格:
1 SELECT c.categoryId, c.categoryName, min(p.price) FROM category c join product p on c.categoryId = p.categoryId 2 GROUP BY c.categoryId, c.categoryName
运行结果:最便宜的鞋子是500,最便宜的车是100000

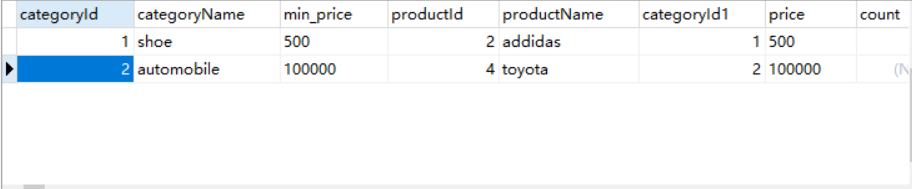
查询每个分类最便宜商品的价格以及商品名称:
这里需要做子查询,对这个sql进行分析,首先我们上一步已经查询出,每个分类下面最便宜的商品的价格,我们将product表和这个结果进行左连接,之后我们在根据商品中的价格与最便宜的价格是否相等,就能筛选出每个分类中最便宜的商品信息。
1 SELECT * FROM (SELECT c.categoryId, c.categoryName, MIN(p.price) min_price FROM category c join product p on c.categoryId = p.categoryId 2 GROUP BY c.categoryId, c.categoryName) as cat_min, product p WHERE cat_min.min_price = p.price
运行结果:

4.事务
ACID
Atomicity(原子性)
Consistency(一致性)
Isolation(隔离性)
Durability(持久性)
5.事务的隔离级别
Read uncommitted (未提交读)
读未提交,即能够读取到没有被提交的数据,所以很明显这个级别的隔离机制无法解决脏读、不可重复读、幻读中的任何一种,因此很少使用
Read_Committed(提交读)
读已提交,即能够读到那些已经提交的数据,自然能够防止脏读,但是无法限制不可重复读和幻读,可以使用for update,让其他事务不可以去读这个表,就可以防止其他事务去修改count的值。
REPEATABLE_READ(可重复读,mysql默认事务隔离级别)
重复读取,repeatable解决的只是在单个事务中重复读取数据的一致,其他事务可以更改该事务select之后的数据,这样就解决了脏读、不可重复读的问题,但是幻读的问题还是无法解决
SERLALIZABLE(串行化)
串行化,最高的事务隔离级别,不管多少事务,挨个运行完一个事务的所有子事务之后才可以执行另外一个事务里面的所有子事务,这样就解决了脏读、不可重复读和幻读的问题了
6. 并发下事务会产生的问题
1、脏读
所谓脏读,就是指事务A读到了事务B还没有提交的数据,比如银行取钱,事务A开启事务,此时切换到事务B,事务B开启事务-->取走100元,此时切换回事务A,事务A读取的肯定是数据库里面的原始数据,因为事务B取走了100块钱,并没有提交,数据库里面的账务余额肯定还是原始余额,这就是脏读。
2、不可重复读
所谓不可重复读,就是指在一个事务里面读取了两次某个数据,读出来的数据不一致。还是以银行取钱为例,事务A开启事务-->查出银行卡余额为1000元,此时切换到事务B事务B开启事务-->事务B取走100元-->提交,数据库里面余额变为900元,此时切换回事务A,事务A再查一次查出账户余额为900元,这样对事务A而言,在同一个事务内两次读取账户余额数据不一致,这