���Ľ�ѡ�������鼮�������ܹ���ƣ�������վ�����ܹ���ҵ��ܹ��ں�֮������
�����Ź��ںţ��ܹ�֮�����������ںŵײ��˵�������Ⱥ���Լ��룬�����ߺ��������߽����������ۡ�Ҳ�����ھ�������è�Ϲ���ֽ���鼮��6.7 Binlog�����Ӹ���
6.7.1 Binlog��Redo Log����Ҫ����
��MySQL�У�Redo Log��¼����ִ�е���־��BinlogҲ��¼��־���������зdz���IJ�����ȣ�MySQL��һ����֧�ֶ��ִ洢��������ݿ⣬InnoDBֻ������һ�֣���Ȼ��Ҳ������Ҫ��һ�֣���Redo Log��Undo Log��InnoDB��������Ĺ��ߣ���Binlog��MySQL����Ķ�����
��ͬ��Redo Log��Undo Log����ʵ������Binlog����Ҫ�����������Ӹ��ƣ�����ǵ�����ģ�û�����Ӹ��ƣ�Ҳ���Բ�дBinlog����Ȼ���ڻ�����Ӧ���У�Binlog���˵ڶ�����;��һ��Ӧ�ý��̰��Լ�αװ��Slave������Master��Binlog��Ȼ������ݿ�ı������Ϣ����ʽ�׳�����ҵ��ϵͳ����������Ϣ��ִ�ж�Ӧ��ҵ����������������»��档���ͻ�������˾�����ⷽ����м�������簢�↑Դ��Canal������Ҳ�м��ֿ�Դ�ģ�����Databus��
ͬRedo Logһ����BinlogҲ����һ��ˢ�̲������⣬�ɲ���sync_binlog���ƣ��ò���������ȡֵ��
0�������ύ֮������ˢ�̣���������ϵͳ������ˢ�̻��ƿ��ܻᶪʧ���ݡ�
1��ÿ�ύһ������ˢһ�δ��̡�
n: ÿ�ύn������ˢһ�δ��̡�
��Ȼ��0��n������ȫ��Ϊ�˲���ʧ���ݣ�һ�㶼����˫1��֤����sync_binlog��innodb_flush_log_at_trx_commit��ֵ��ȡΪ1��
֪��Binlog�ĸſ��������Binlog ��Redo Log��һ����ϸ�ĶԱȣ����6-17 ��ʾ��
��6-17 Binlog��Redo Log����ϸ�Ա�
�ӱ��п��Կ�����BinlogҪ��Redo Log�ö࣬�ڲ�����崻�������£�δ�ύ�����ع�����������־���������Binlog������Binlogд��һ��ʱ崻��ij��������������ۣ���
ͬʱ���������־��Binlog�����������еģ��ȵ������ύ�ġ�һɲ�ǡ����Ѹ������������־��д�̡��������л����һ�����⣺Binlogȫ��ֻ��һ�ݣ�ÿ������Ҫ���е�д�룬����ζ��ÿ��������дBinlog֮ǰҪ��һ��ȫ�ֵ��������ܱ�֤ÿ�������Binlog������д��ģ�����Ч���ϴ��ںܴ����⡣��ˣ���MySQL 5.6��Group Commit����֮ǰ�����ֵ��������Ż��������⡣Group Commit��˼��Ҳ�ܼ�����pipeline��HTTP 1.1��ͬ����˼·��Kafka�����Ӹ���Ҳ��ͬ����˼·�����潲�߲���ʱ��������ר�����۸����⣩����ȻBinlogֻ�ܴ��е�д�룬������Ҫ�ύһ������ˢһ�δ��̣����ǰ�������ύ��ˢ�̷ŵ���ͬ���߳��ˢ��ʱ���ԶԶ���ύ������ͬʱˢ�̣���Ȼ���Ǵ��У������������ˡ�
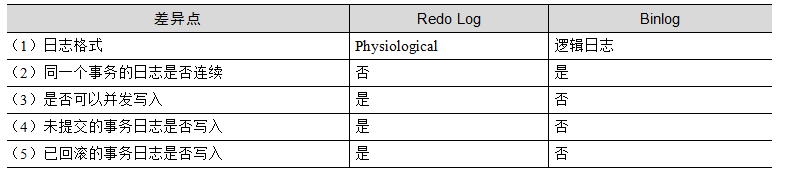
6.7.2 �ڲ�XA �C Binlog��Redo Logһ��������
һ��������ύ��ҪдBinlog��ҲҪдRedo Log����α�֤������־���ݵ�ԭ���ԣ�һ��д�ɹ���д����һ����ʱ����崻���������δ�����
�������������֮ǰ����˵һ��Binlog����д���ԭ�������⣺Binlogˢ�̵�һ�룬����崻�����������ǰ�潲Redo Log��д��ԭ������ͬ�������⣬ͨ��������Checksum�İ취����Binlog���н�����ǣ����жϳ����Dz��ֵġ���������Binlog�������һ�νص������ڿͻ�����˵����ʱ崻�������϶���û�гɹ��ύ�ģ����Խص�Ҳû�����⡣
�����������ʵ��Binlog��Redo Log������һ���ԣ����ڲ�XA�����߽��ڲ��ķֲ�ʽ�������⡣�ⲿ�ֲ�ʽ����������ϵͳ�����������ݿ�֮��ģ�����ں��������һ�����л�ר���������ڲ��ֲ�ʽ������Binlog��Redo Log֮�������ʹ�õ��Ǿ����2���ύ������2PC��2 Phase Commit����
ͼ6-19չʾ��һ�������2���ύ���̣�������ϸ���������ύ���̡�
��1��InnoDB��Prepare�����ڰ������ύ֮ǰ����Ӧ��Redo Log��Undo Logȫ����д���ˡ�BinlogҲ�Ѿ�д�뵽�ڴ棬ֻ��ˢ�̡�
ͼ6-19 �ڲ�XA�������2���ύ���̣�
��2���յ��ͻ��˵�Commitָ���ˢ��Binlog��Ȼ����InnoDBִ��Commit��
2PC��һ�������ص��ǣ��ڽ�1�Ͱ�90%���ϵĹ���ȫ�������ˣ��͵Ƚ�2����β�������ڽ�2�յ��ͻ��˵�Commitָ���ֻҪ��崻���������ܳɹ��ύ�����������崻�����λָ���
���ȣ�����������Binlog��ˢ�����ж�һ�������Ƿɹ��ύ������BinlogΪ����Redo Log��Binlog�����롱�������Ϊ���漸�ֳ�����
������1�����ڽ�1崻�����ʱBinlogȫ���ڴ��У�崻���ʧ��Redo Log��¼��δ�ύ����־������Ҫ����Binlog��Redo Log�Լ����Իع�δ�ύ����־�����ǰ���ѽ��ܹ���
������2������2崻���Binlogд��һ�룬InnoDB Commit��δִ�С���Binlog���ضϣ���Redo log���ع������������볡����1��һ����
������3����Binlogд��ɹ���InnoDBδ�ύ����ʱ����Binlog��Binlog�д��ڡ�InnoDB�в����ڵ�������Commit������
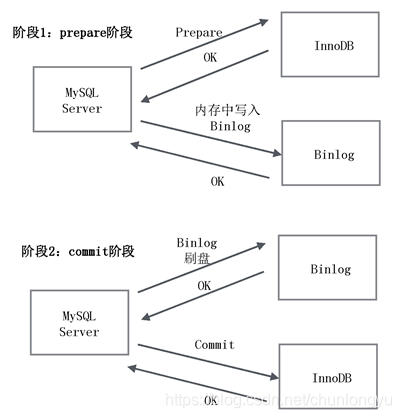
6.7.3 �������Ӹ��Ʒ�ʽ
��6-18 �о���MySQL���������Ӹ��Ʒ�ʽ�������첽���ƣ����ܻᶪ���ݣ�Master崻��ˣ��л���Slave����ʱSlave��û�����µ����ݡ����Ժܶ�ʱ�����õ��ǰ�ͬ�����ơ�
���ǰ�ͬ�����ƾͲ��ᶪ�����أ����ǵġ���ͬ�����ƿ����˻�Ϊ�첽���ơ���ΪMaster�����������ڵص�Slave��������ij��ʱ�䣬Slave��û�лظ�ACKʱ��Master�ͻ��л�Ϊ�첽����ģʽ��
���⣬����һ������rpl_semi_sync_master_wait_slave_count�����������ڰ�ͬ������ģʽ�£���Ҫ�ȴ�����Slave��ACK������Ϊ�����ύ�ɹ���Ĭ����1�������Slave��ֻҪ������һ�������ˣ�Master�ͻ���ͻ��˷��������ύ�ɹ���
��6-18 MySQL���������Ӹ��Ʒ�ʽ
������Ľ��ܿ��Կ����������첽���ƣ����ǰ��첽���ƣ������˻�Ϊ�첽���ƣ����������������л���ʱ�����ݡ�ҵ��һ�������������һ��������ȡ�߿����ԣ�����Master崻����л���Slave���������������ݶ�ʧ���������˹�����
��������Ӹ��Ƶ��ӳ�̫���л���Slave����ʧ����̫�࣬Ҳ���Խ��ܡ�Ϊ�˽������Ӹ��Ƶ��ӳ٣�ҵ���ǰ�������˺ܶ�İ취�����������Ҫ���IJ��и��ƣ��ڿ����������£������Ҫ��
6.7.4 �����
ͼ6-20չʾ��ԭ����MySQL���Ӹ��Ƶ�ԭ������Ϊ�����Σ�
��1����Master�е�Binlog���˵�Slave���棬�γ�RelayLog����������˹����У�Master��Slave���߸���һ���̣߳�Master����Ľ�dump thread��Slave����Ľ�I/O thread��
��2��Slave��RelayLog�طŵ����ݿ⣬ͨ��һ������SQL thread���߳�ִ�С�
ͼ6-20
