一、HDFS运行机制
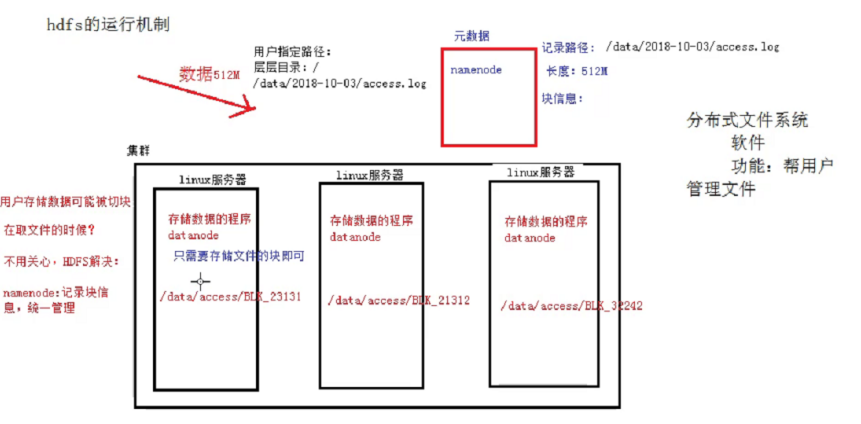
概述:用户的文件会被切块后存储在多台datanode节点中,并且每个文件在整个集群中存放多个副本,副本的数量可以通过修改配置自己设定。
HDFS:Hadoop Distributed file system,分布式文件系统。
HDFS的机制:
HDFS集群中,有两种节点,分别为Namenode,Datanode;
Namenode它的作用时记录元数据信息,记录块信息和对节点进行统一管理。比如用户要存储一个很大的文件,HDFS系统会对这个文件进行切分,然后存储在多台Namenode节点当中,那么每个切的大小,存储的路径信息,文件的副本数等元数据信息会存储在元数据当中,由Namenode进行管理和记录。
Datanode节点的作用是存储数据,Namenode将数据切块后的分配给多个Datanode节点,Datanode对数据块进行存储,Datanode它默认的块大小在hadoop1.x的版本中是64M,而hadoop2.x之后的版本默认块大小为128M。
HDFS还有一个副本机制,它会默认给存在Datanode当中的每块文件进行备份,默认的副本数量(republication)为3,这样保证了数据的安全性。
大致如图:
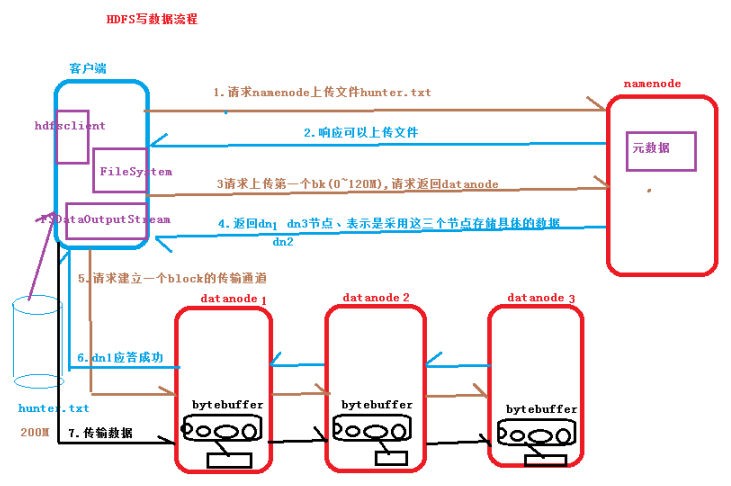
二、HDFS写数据流程
1.客户端向Namenode请求上传文件数据Hunter.txt(大小:200M);
2.Namenode响应可以上传文件;
3.客户端向Namenode请求上传第一个block(0~128M),请求返回Datanode节点;
4.Namenode返回三个Datanode节点(副本数默认为3),采用这三个节点存储数据;
5.客户端向Datanode请求建立一个block的传输通道;
6.Datanode应答通道建立成功;
7.客户端向Datanode传输数据,数据写入到HDFS文件系统当中。
三、hdfs读数据流程
1.客户端向Namenode请求下载文件hunter.txt(200M);
2.Namenode返回目标文件的元数据信息(block所在的datanode);
3.客户端向Datanode请求读取数据文件;
4.Datanode以FSDataInputStream流的形式向客户端传输数据;
5.客户端生成hunter.txt文件。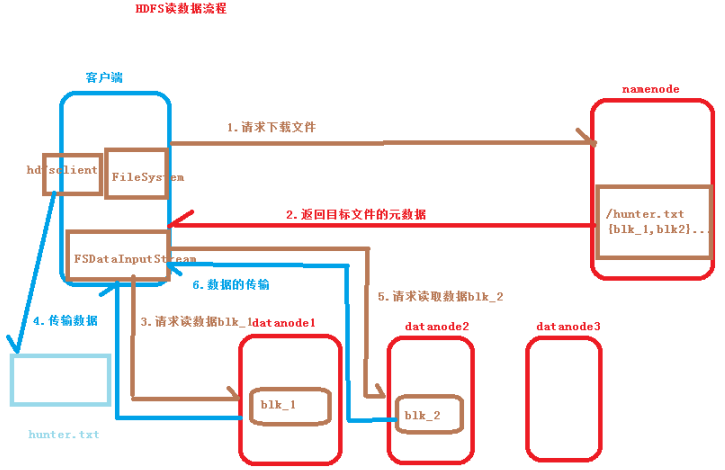
四、Namenode运行机制
首先去到主节点namenode的元数据信息dfs目录中,可以看到很多种文件,如下:
edits:存放HDFS系统所有的更新操作的日志文件
fsimage:HDFS元数据的永久性的检查点,其中包含了hdfs系统所有的目录和文件
seen_txid:最有一个edits文件的数字,即edits文件个数
VERSION:记录了很多的id,如下:
namespaceID:每个节点的id,每个节点都不同
ClusterID:一个集群统一的id,是唯一的,一个集群中所有节点的ClusterID都相同
CTime:Namenode存储系统的使用时间的时间戳
storageType:节点类型
blockpoolID:跨集群的全局唯一
layoutVersion:版本号
Namenode的运行机制:
1.首先启动集群,会启动Namenode和SecondaryNamenode,两个节点的内存会加载日志文件和镜像文件(edits、fsimage文件);
2.当客户端对HDFS集群进行增删改查等操作时,日志文件会更新滚动;
3.当eidts文件数量达到默认阈值,或checkpoint时间到达默认触发时间时;
(dfs.namenode.checkpoint.period :多久checkpoint一次、
dfs.namenode.checkpoint.check.period:多久检查一次操作的次数、
dfs.namenode.checkpoint.txns:多少次操作后chechpoint一次)
4.Namenode将edits文件拷贝到SecondarNamenode;
5.SecondarNamenode的内存会加载拷贝的edits文件并合并;
6.SecondarNamenode会生成新的镜像文件fsimage.checkpoint;
7.SecondarNamenode将新生产的镜像文件拷贝到Namenode;
8.Namenode将收到的镜像文件重命名为fsimage;
9.Namenode将新的fsimage镜像文件发送到SecondarNamenode
这样两个节点的元数据信息就相同了!!!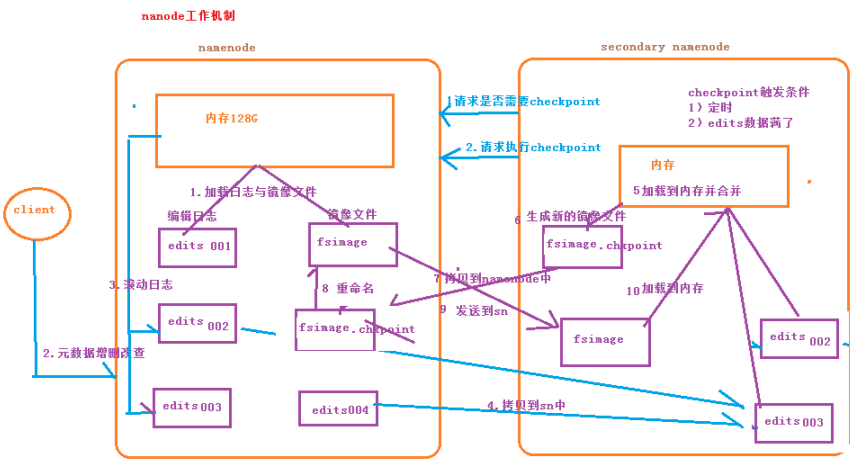
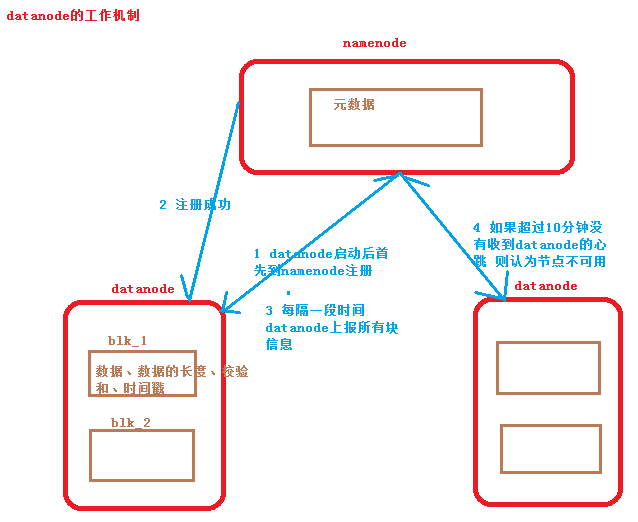
五、Datanode运行机制
1.HDFS集群启动后,Datanode现象Namenode发送注册信息;
2.Namenode返回注册成功;
3.每隔一段时间Datanode会上传所有的块信息到Namenode;
(块信息:数据、数据长度、校验和、时间戳等)
4.默认如果超过10分钟Namenode没有收到Datanode的信息信息,则认为节点不可用