目录
1 添加文档的细节
1.1 注册观察者 - watcher
Solr单机服务中, 与Solr内部进行交互的类是
HttpSolrServer.
SolrCloud集群中, 与Solr内部进行交互的类是CloudSolrServer.
这里以SolrCloud集群为例讲解添加文档的相关细节.
当Solr客户端向CloudSolrServer发送add/update请求时, CloudSolrServer会从ZooKeeper获取当前SolrCloud的集群状态,并在ZooKeeper管理的配置文件/clusterstate.json和/live_nodes中注册观察者watcher, 便于监视ZooKeeper和SolrCloud.
注册观察者的好处是:
①
CloudSolrServer获得SolrCloud的状态后, 就能直接把要添加/修改的document发往Solr集群的leader, 从而降低网络转发上的消耗;
② 注册watcher有利于添加索引时的负载均衡: 如果有个节点的leader下线了,CloudSolrServer就能立刻感知到, 它就会停止往已下线的leader发送请求.
1.2 文档的路由 - document route
CloudSolrServer添加document时, 需要确定该document发往哪个Shard. SolrCloud集群中, 每个Shard都有一个Hash区间, 添加时, SolrCloud会计算该文档的Hash值, 然后根据它的Hash值, 把它发送到对应Hash区间的Shard.
―― 上述过程称为文档的分发, 由Solr的document route(文档路由)组件来完成.
1.2.1 路由算法
SolrCloud提供了两种路由算法, 创建Collection(集合, 类似于MySQL中的表)时, 需要通过router.name来指定路由策略.
① compositeId - 默认的路由算法:
- 该策略是一致性哈希路由, Shards的哈希范围是
80000000~7fffffff;- 创建Collection的时候必须指定numShards, 这个路由算法将根据Shard的个数, 计算出每个Shard的哈希范围;
- 索引数据会均匀分布在每个Shard上;
- 这个路由策略不支持扩展Shard, 否则会导致一些已经索引到Solr中的文档无法被检索.
② implicit - 绝对路由策略:
- 该路由策略是直接指定索引文档落到具体的某个Shard上;
- 索引数据并不会均匀分布到每个Shard上;
- 使用implicit路由策略的Collection才支持 创建/扩展 Shard.
1.2.2 Solr路由的实现类
Solr中路由的基类是DocRouter, 它有2个子类: CompositeIdRouter(默认使用的), 和ImplicitDocRouter.
我们可以通过继承DocRouter类来定制自己的document route组件.
1.2.3 implicit路由算法的使用
通过SolrJ创建文档索引时, 使用implicit策略指定文档的所属Shard:
代码如下:
doc.addField("route", "shard_X");同时, 要在schema.xml约束文件中添加字段:
<field name="_route_" type="string"/>利用URL创建implicit路由方式的Collection:
http://ip:port/solr/admin/collections?action=CREATE&name=coll&router.name=implicit&shards=shard1,shard2,shard3
1.2.4 Solr获取文档Hash值的要求
① Hash值的计算速度必须很快, 这是分布式创建索引的第一步;
② Hash值必须能均匀地分布到每一个Shard上. 如果某个Shard中document数量远多于其他Shard, 那么在查询等操作中, 文档数量多的Shard所花的时间就会大于其他Shard, 而SolrCloud的查询是 先分给各个Shard查询, 然后汇总返回 的过程, 也就是说SolrCloud的查询速度是由最慢的Shard决定的.
基于以上两点, Solr的底层引擎Lucene使用了MurmurHash算法, 用来提高Hash值的计算速度和均匀分布.
关于MurmurHash哈希算法, 可参考文末的相关链接.
2 添加索引的过程
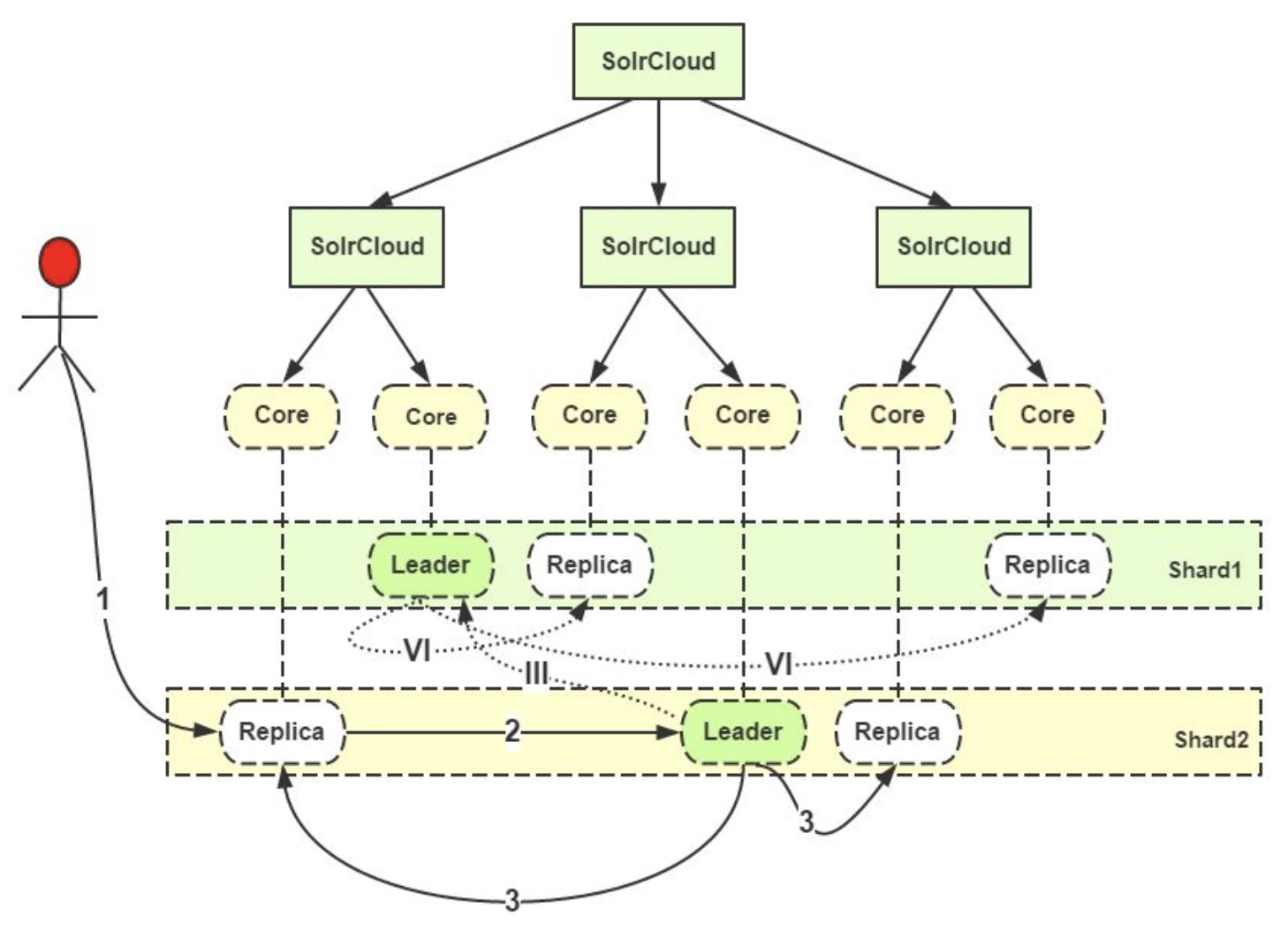
参照上图, 解析添加索引的过程:
(1) 用户把要添加的文档提交给任意一个Replica(副本, 可以是主副本, 也可以是从副本);
(2) 如果接收到请求的Replica不是Leader, 它会把请求转给同Shard中的Leader;
(3) Leader把文档路由给本Shard的其他所有Replica;
(III) 如果根据路由规则, 当前文档并不属于当前的Shard, 这个Leader就会把它转交给对应Shard的Leader;
(VI) 对应的Leader会把文档路由给本Shard的每个Replica, 从而完成添加操作.
注意:
添加索引时, 单个document的路由非常简单.
但是SolrCloud支持批量添加索引, 也就是说对多个document同时进行路由, 这时SolrCloud会根据document路由的去向分开存放document, 然后并发传送到相应的Shard, 这就需要SolrCloud具有较高的并发能力.
3 更新索引的过程
(1) Leader接受到update请求后, 先将需要修改的文档存放到本地的update log, 同时Leader还会对这个文档分配新的version(版本信息), 对于已经存在的文档, 如果新版本值大于旧版本值, 就会抛弃旧版本;
(2) 一旦document经过验证并修改了version后, 就会被并行转发到所有上线的Replica;
SolrCloud并不关注那些已经下线的Replica, 因为当它们上线之后就会有Recovery恢复进程对它们进行恢复. 如果Replica处于recovering(恢复中)的状态, 那这个Replica就会把update放入update transaction日志, 等待恢复完成后再做同步.
(3) 当Leader接受到所有的Replica的成功反馈后, 它才会向客户端反馈操作成功的信息;
Shard中就算只有一个Replica是active的, Solr都会继续接受update请求 ―― 这个策略牺牲了一致性, 换取了写入的有效性.
有一个很重要的参数:
leaderVoteWait: 只有一个Replica的时候, 这个Replica进入re