本来这一节想写Hadoop的分布式高可用环境的搭建,写到一半,发现还是有必要先介绍一下ZooKeeper这个东西。
ZooKeeper理念介绍
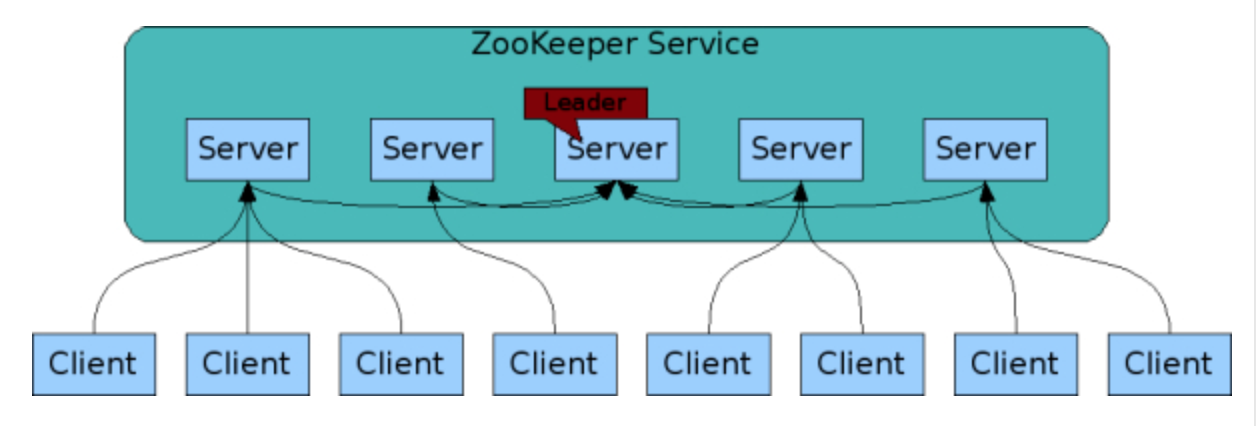
ZooKeeper是为分布式应用来提供协同服务的,而且ZooKeeper本身也是分布式的,由分布在至少三台机器上,这几台机器形成一个Quorum,就想一个剧团一样。这个团里有个团长,就是leader的角色,其他的是follower。这个剧团里的每个人脑子里都记住同样的东西(ZooKeeper是基于内存的),并且及时和leader保持同步,所有client可连接任何一个server即可。剧团里的每个人都有一个编号myid。如果剧团里的leader挂断后,剩下的几个要重新选举出新的leader来确保服务正常运行。
1. ZooKeepe的安装
ZooKeeper的安装挺简单,就是解压,设置环境变量就可以了
[root@hadoop100 bin]# tar -zxvf /opt/software/zookeeper-3.4.10.tar.gz -C /opt/modules/
打开/ect/profile 编辑环境变量,加上下面的内容:
#JAVA_HOME export JAVA_HOME=/opt/modules/jdk1.8.0_121 export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/opt/modules/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #ZOOKEEPER export ZOOKEEPER_HOME=/opt/modules/zookeeper-3.4.10 export PATH=$PATH:ZOOKEEPER_HOME/bin
然后 source /ect/profile 让更改生效。记得用xsync 和xcall超级脚本,把更改同步到整个集群。
[root@hadoop100 bin]# xsync /etc/profile
[root@hadoop100 bin]# xcall source /etc/profile
2. ZooKeeper的配置
1. Zookeeper 需要一个data目录,用于存储zookeeper内存数据库的镜像和日志。然后更改zoo.cfg文件。ZooKeeper解压后提供了一个/opt/modules/zookeeper-3.4.10/conf/zoo_sample.cfg文件,把这个复制一下或者改个名字叫zoo.cfg, 修改一下里面的dataDir的指向。
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/modules/zookeeper-3.4.10/zkData # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 ~
要搭建ZooKeeper的机器环境,zookeeper服务器的数量应该是奇数台。最少要3台。
# 连接到leader 服务器的tick数,超过这个tick数 这台服务器还没有连接上leader,那这台机 器就被认为是死掉了 initLimit = 5 # 在和leader同步过程中所允许落后的最大tick数,如果超过这个,那就是掉队了 syncLimit = 2 server.100=hadoop100:2888:3888 server.101=hadoop101:2888:3888 server.102=hadoop102:2888:3888 server.103=hadoop103:2888:3888 server.104=hadoop104:2888:3888
机器的参数配置的格式是这样的:
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
注意更改完毕后别忘了分发到集群中。zookeeper本身是也分布式的。先把相关文件分发到集群中的其他机器上。
[root@hadoop100 modules]# xsync zookeeper-3.4.10/
然后为每台机器做上独特的标记,在data目录里创建myId文件,内容就是上面配置文件中的数字
[root@hadoop100 zookeeper-3.4.10]# cd zkData/ [root@hadoop100 zkData]# echo 100 > myid
在集群的其他几台机器上修改myid文件的内容,让myid的内容和配置文件中的编号一致。这时候只能麻烦点,依次登录到每台机器上创建 data目录下的myid文件了。
[root@hadoop100 zkData]# ssh hadoop101
Last login: Thu Sep 19 14:10:35 2019 from gateway [root@hadoop101 ~]# echo 101 > /opt/modules/zookeeper-