供了统一的数据发送方法,输入配置解析,日志记录框架等功能。
开源社区已经贡献了许多的beats种类。
因为Beats是使用Golang编写的,效率上很不错。
Splunk使用Farwarder和Add-ons来进行数据的消化和获取。
Splunk内置了对文件,syslog,网络端口等input的处理。当配置某个节点为Forwarder的时候,Splunk Forwarder可以作为一个数据通道把数据发送到配置好的indexer去。这时候,它就类似logstash。这里一个主要的区别就是对数据字段的抽取,Elastic必须在logstash中通过filter配置或者扩展来做,也就是我们所说的Index time抽取,抽取后不能改变。Splunk支持Index time的抽取,但是更多时候,Splunk 在index time并不抽取而是等到搜索是在决定如何抽取字段。
对于特定领域的数据获取,Splunk是用Add-on的形式。Splunk 的App市场上有超过600个不同种类的Add-on。

用户可以通过特定的Add-on或者自己开发Add-on来获取特定的数据。
对于大数据的数据采集,大家也可以参考我的另一篇博客。
数据管理和存储
ElasticSearch的数据存贮模型来自于Lucene,基本原理是实用了倒排表。大家可以参考这篇文章。
Splunk的核心同样是倒排表,推荐大家看这篇去年Splunk Conf上的介绍,Behind the Magnifying Glass: How Search Works
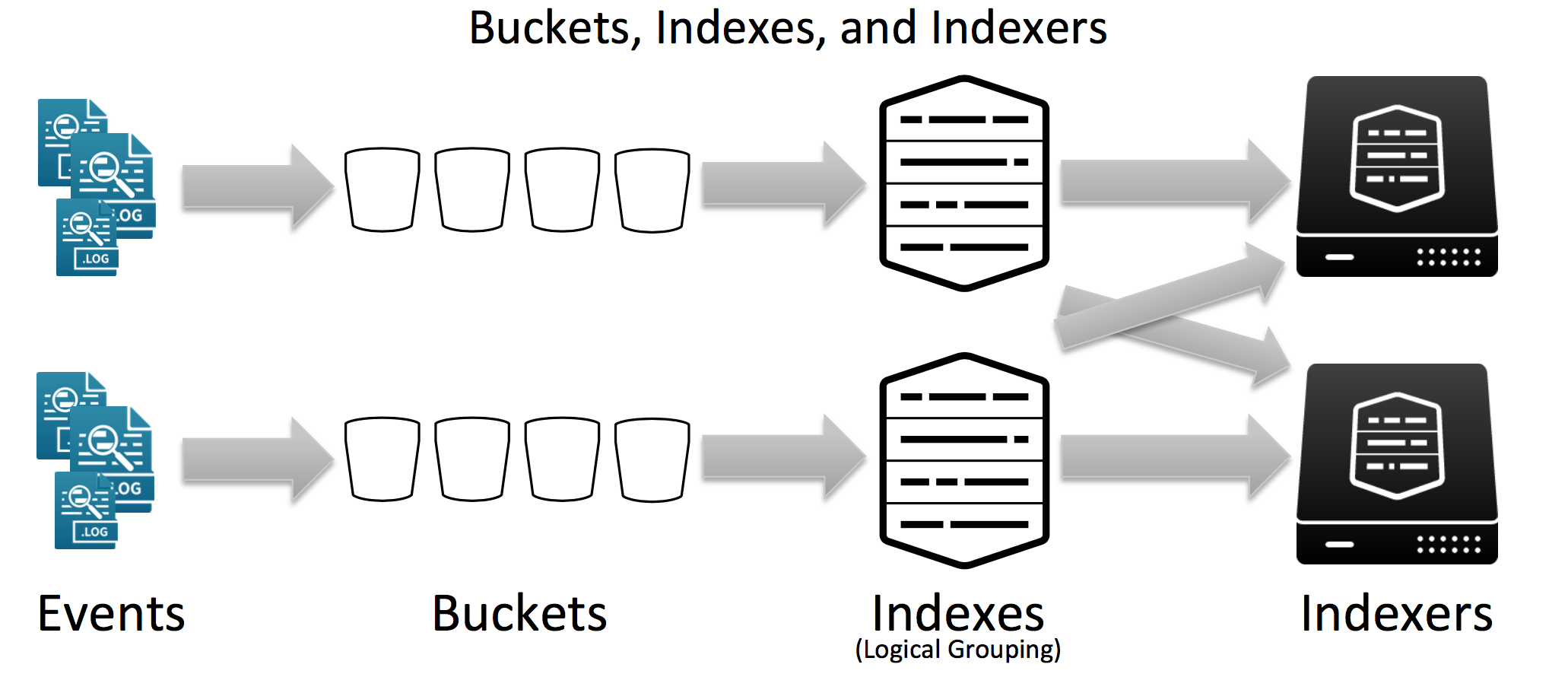
Splunk的Event存在许多Buckets中,多个Buckets构成逻辑分组的索引分布在Indexer上。

每个Bucket中都是倒排表的结构存储数据,原始数据通过gzip压缩。
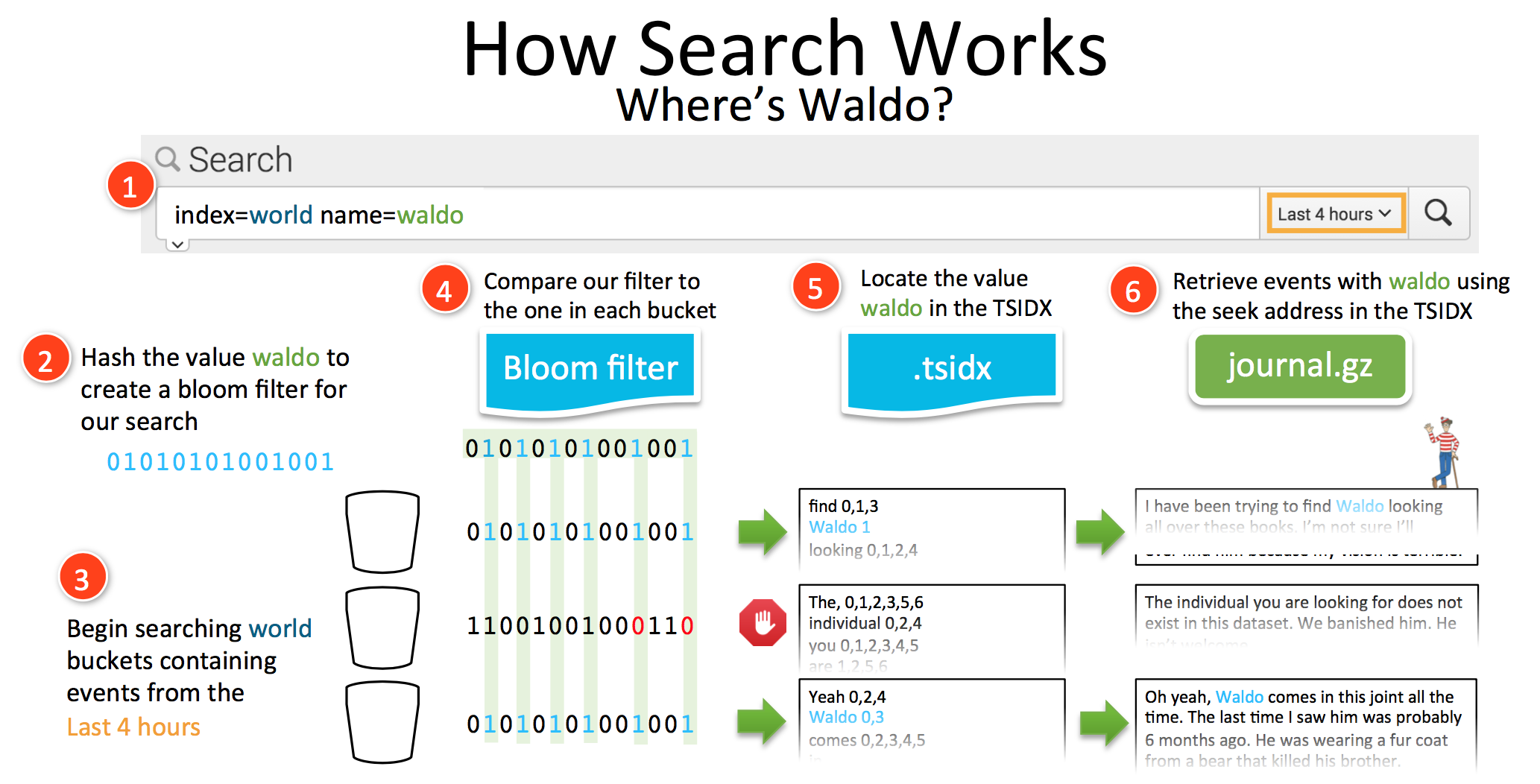
搜索时,利用Bloom filter定位数据所在的bucket。
在对数据的存储管理上,Elastic 和Splunk都是利用了倒排表。Splunk对数据进行压缩,所以存储空间的占用要少很多,尤其考虑到大部分数据是文本,压缩比很高的,当然这会损失一部分性能用于数据的解压。
数据分析和处理
对数据的处理分析,ElasticSearch主要使用 Search API来实现。而Splunk则提供了非常强大的SPL,相比起ES的Search API,Splunk的SPL要好用很多,可以说SPL就是非结构化数据的SQL。无论是利用SPL来开发分析应用,还是直接在Splunk UI上用SPL来处理数据,SPL都非常易用。开源社区也在试图为Elastic增加类似SPL的DSL来改善数据处理的易用性。例如:
从这篇反馈可以看出,ES的search还有许多的不足。
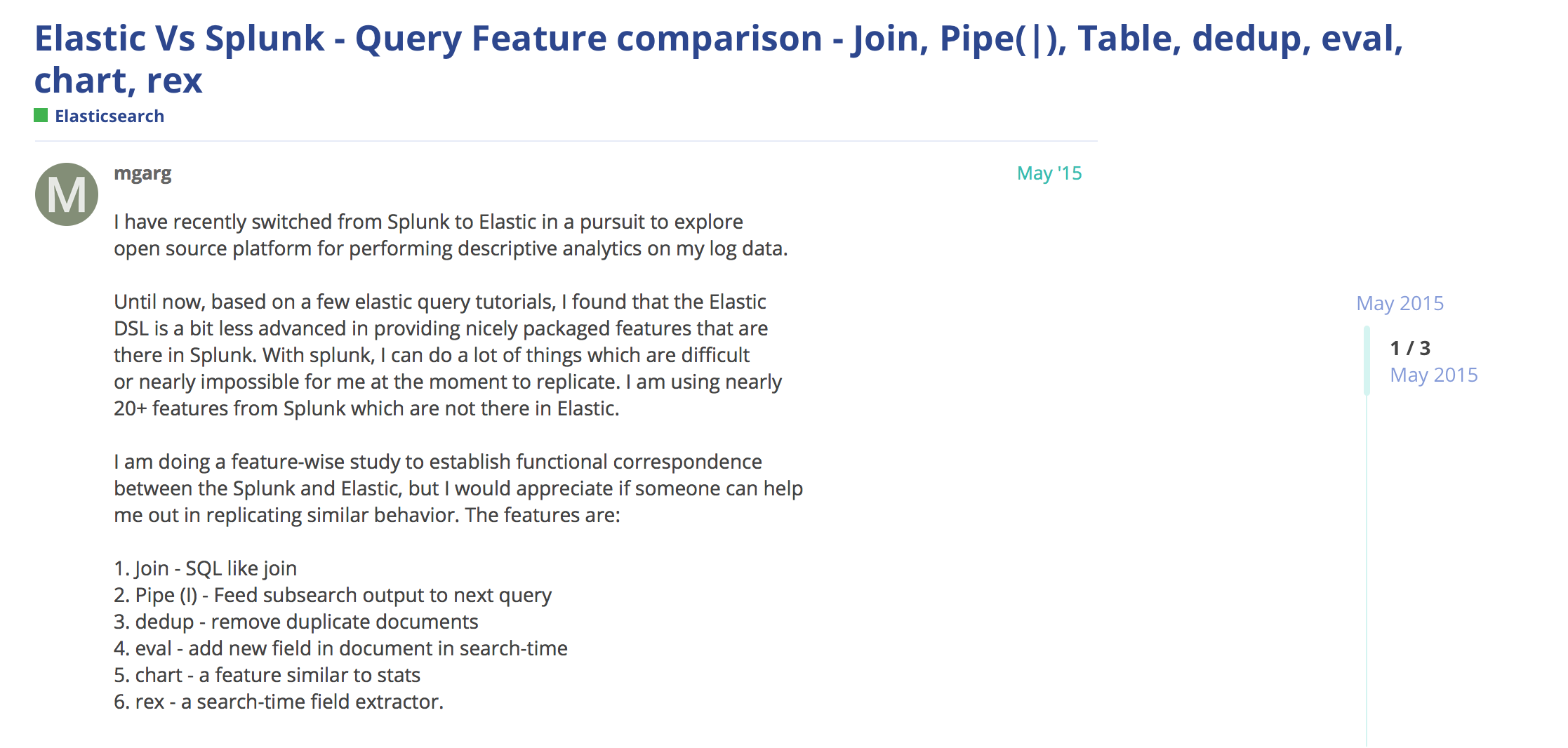
作为对此的响应,Elastic推出了painless script,该功能还处于实验阶段。
数据展现和可视化
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
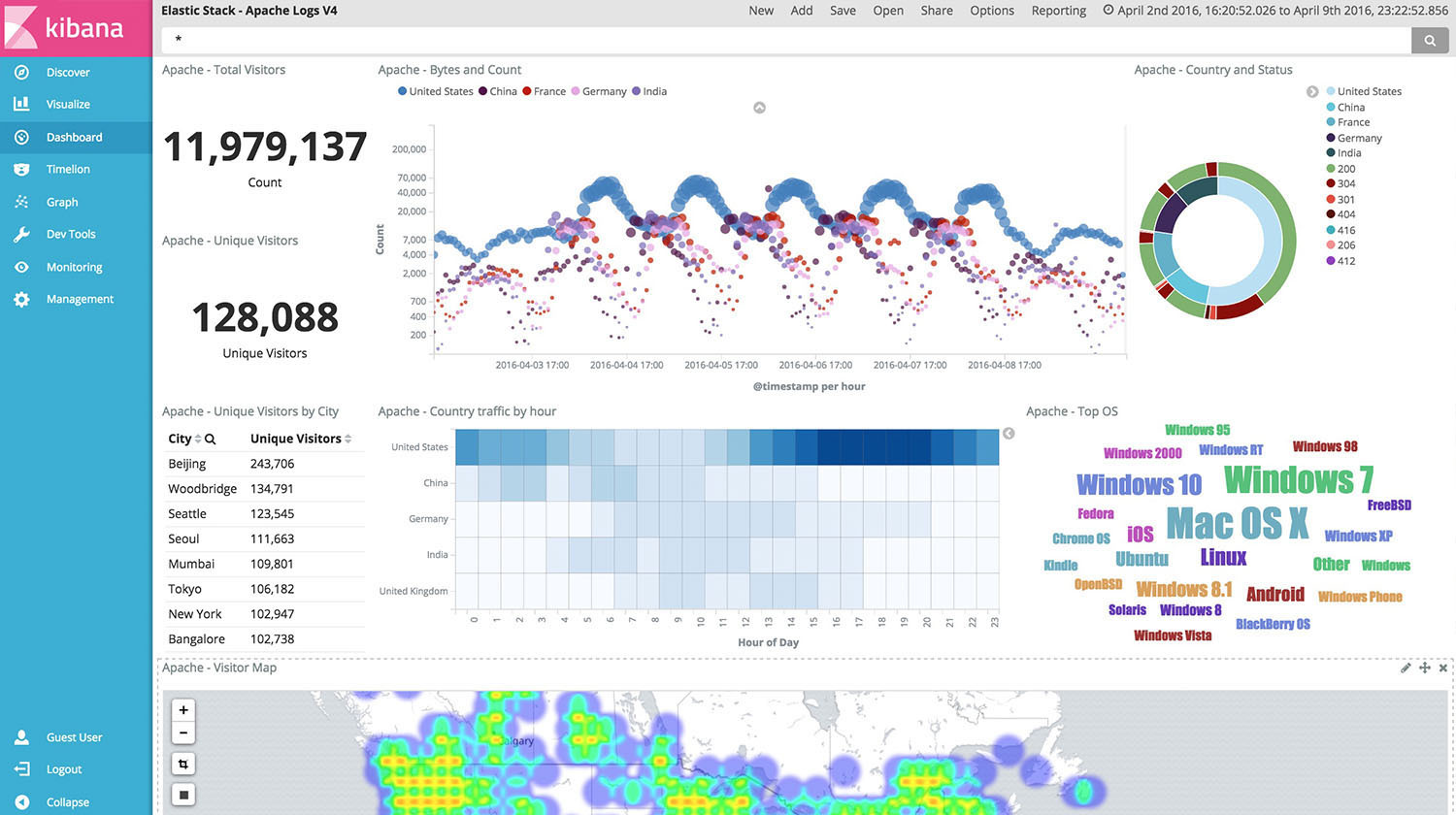
Splunk集成了非常方便的数据可视化和仪表盘功能,对于SPL的结果,可以非常方便的通过UI的简单设置进行可视化的分析,导出到仪表盘。
下图的比较来自https://www.itcentralstation.com/products/comparisons/kibana_vs_splunk
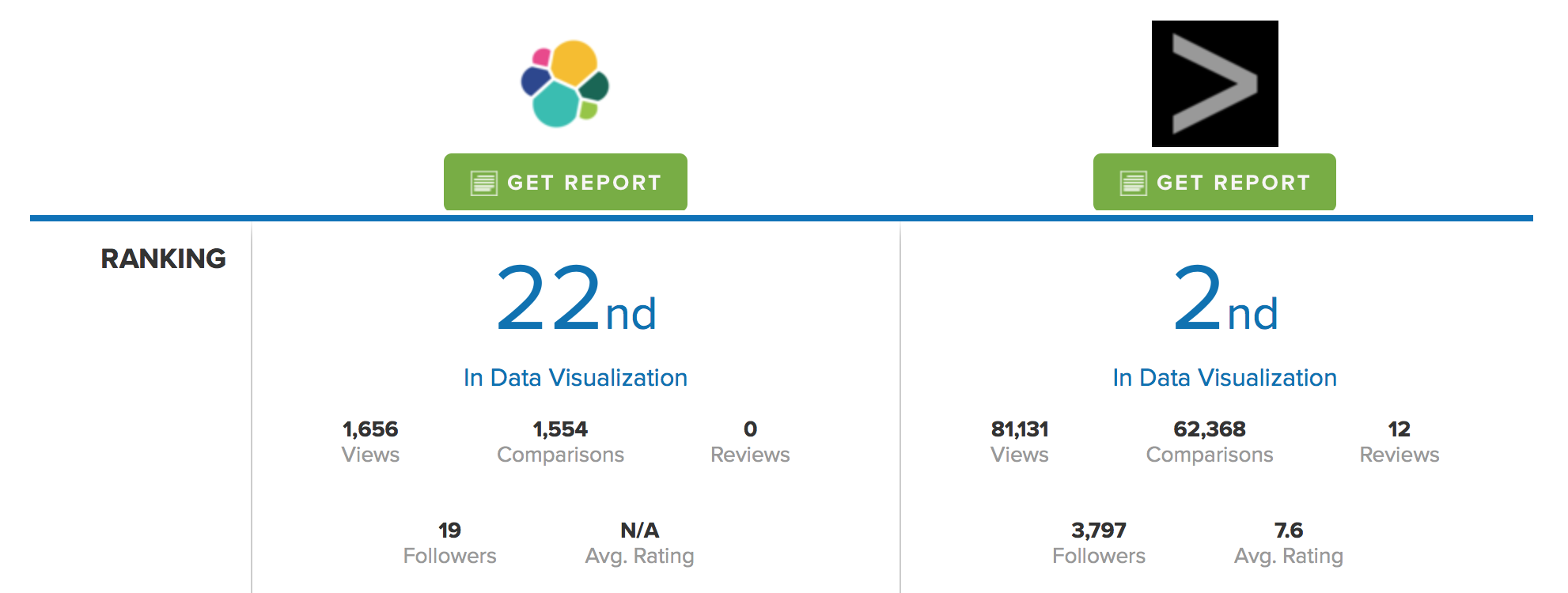
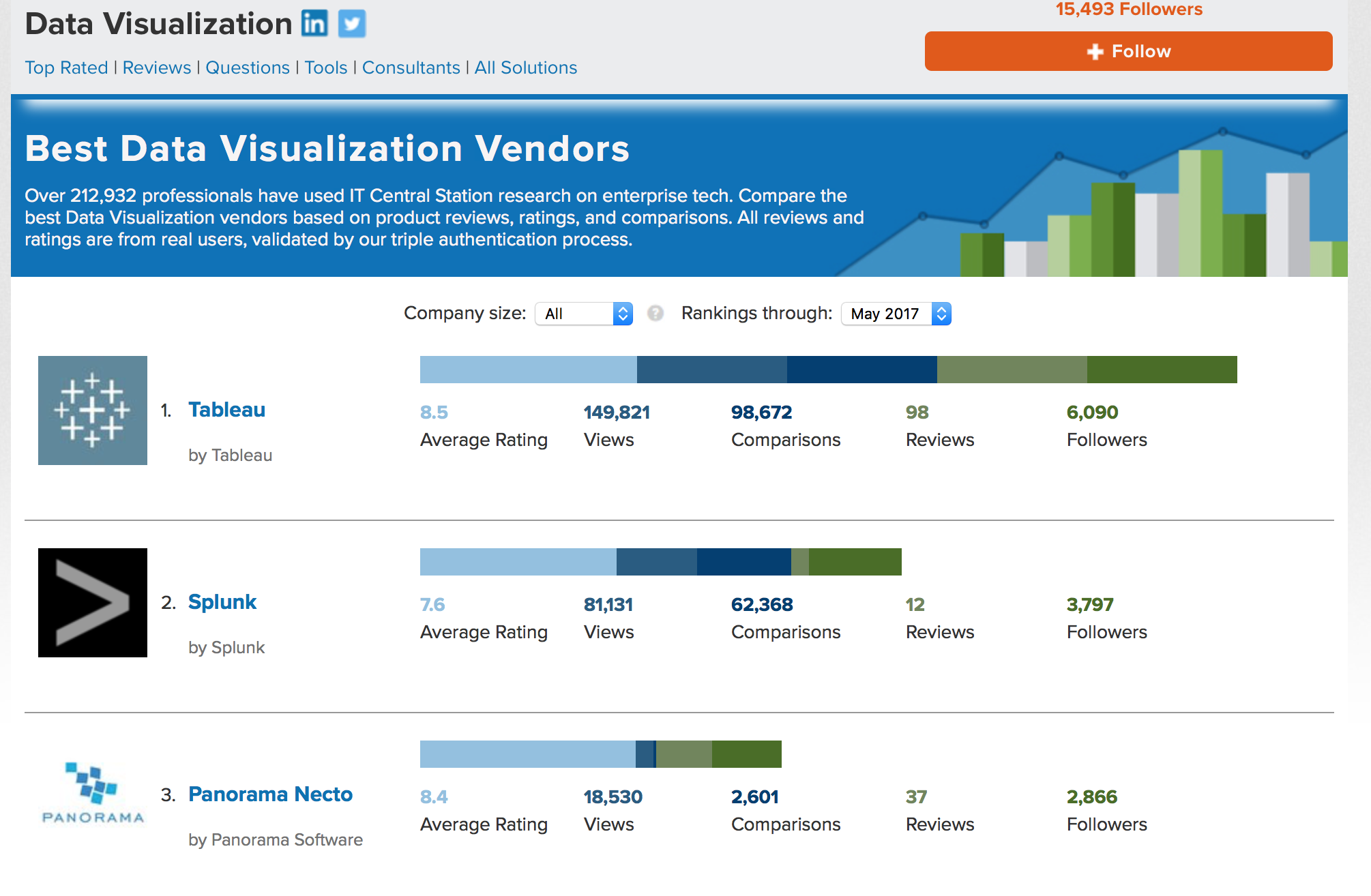
在数据可视化的领域的排名,Splunk仅仅落后于Tableau而已
扩展性
从扩展性的角度来看,两个平台都拥有非常好的扩展性。
Elastic栈作为一个开源栈,很容易通过Plugin的方式扩展。包括:
Splunk提供一系列的扩展点支持应用和Add-on的开发, 在http://dev.splunk.com/可以找到更多的信息和文档。包括:
比起Elastic的Plugin,Splunk的扩展概念上比较复杂,开发一个App或者Add-on的门槛都要相对高一些。做为一个数据平台,Splunk应该在扩展性上有所改进,使得扩展变的更为容易和简单。
架构
Elastic Stack
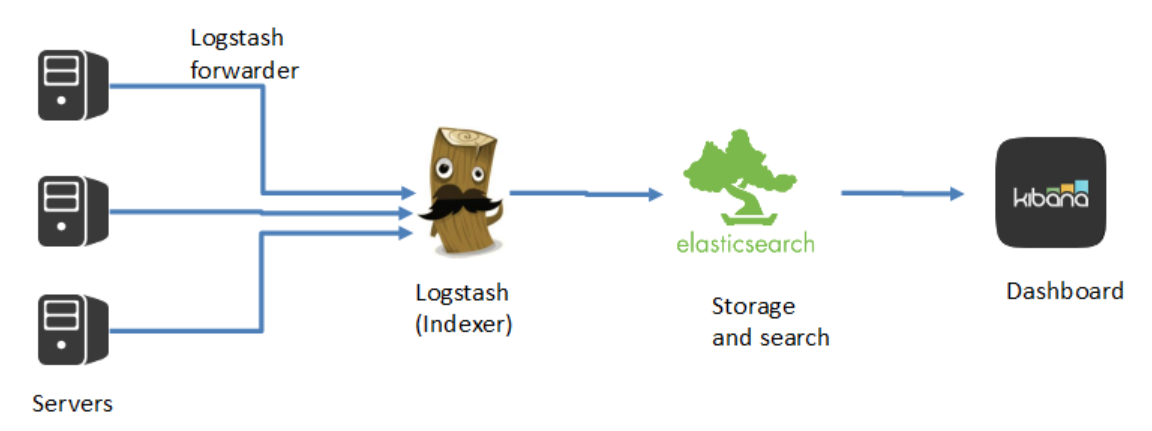
如上图所示,ELK是一套栈,Logstash提供数据的消化和获取,Elasticsearch对数据进行存储,索引和搜索,而Kibana提供数据可视化和报表的功能。
Splunk
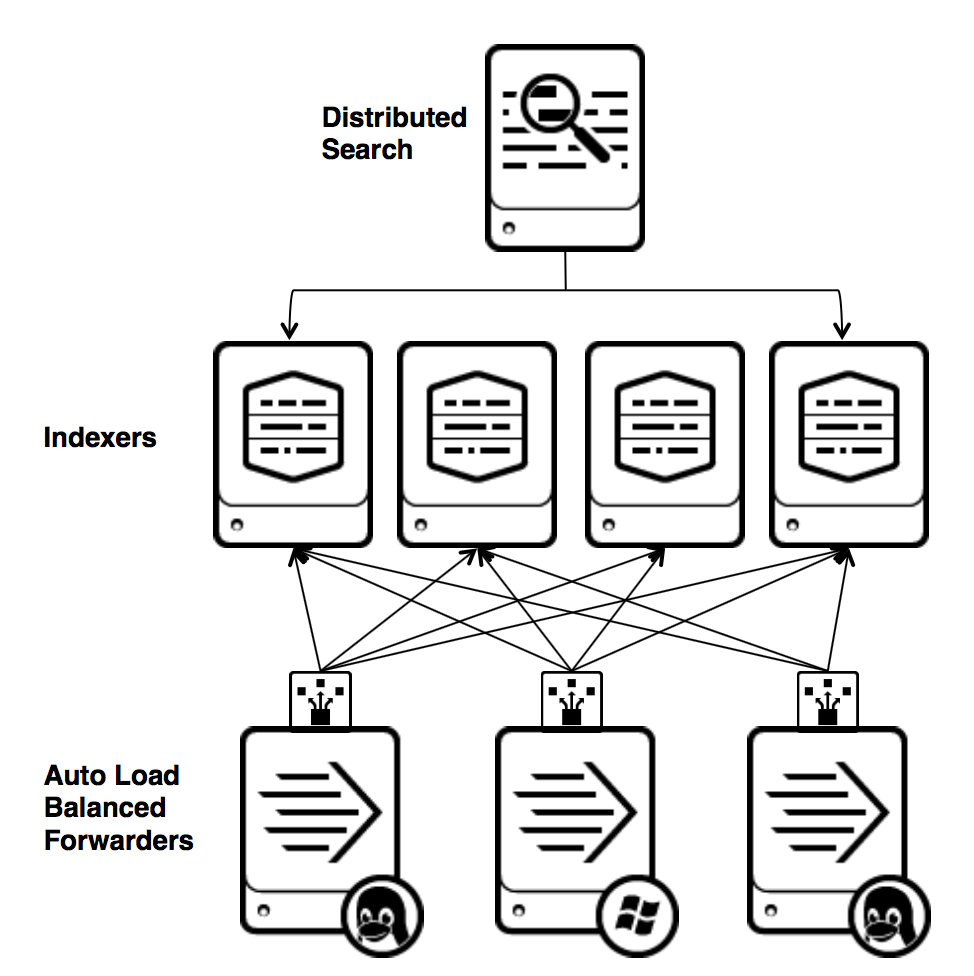
Splunk的架构主要有三个角色:
- Indexer
Indexer提供数据的存储,索引,类似Elasticsearch的作用
- Search Head
Search Head负责搜素,客户接入,从功能上看,一部分是Kibana,因为Splunk的UI是运行在Search Head上的,提供所有的客户端和可视化的功能,还有一部分,是提供分布式的搜索功能,包含对搜索的分发到Indexer和搜索结果的合并,这一部分功能对应在Elasticsearch上。
- Forwarder
Splunk的Forwarder负责数据接入,类似Logstash
除了以上的三个主要的角色,Splunk的架构中还有:Deployment Server,License Server,Master Cluster Node,Deployer等。
Splunk和ELK的基本架构非常类似,但是ELK的架构更为简单和清楚,Logstash负责数据接入,Kibana负责数据展现,所有的复杂性在Elasticsearch中。Splunk的架构更为复杂一些,角色的类型也更多一些。
如果装单机版本,Splunk更容易,因为所有的功能一次性就装好了,而ELK则必须分别安装E/L/K,从这一点上来看,Splunk有一定的优势。
分布集群和扩展性
ElasticSearch
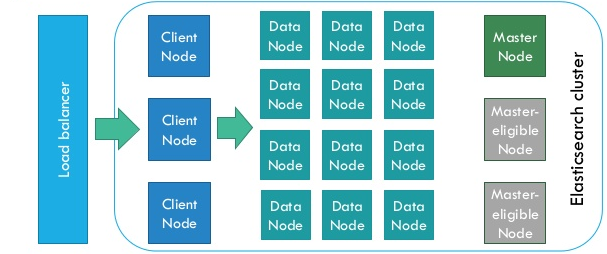
ElasticSearch是为分布式设计的,有很好的扩展性,在一个典型的分布式配置中,每一个节点(node)可以配制成不同的角色,如上图所示:
- Client Node,负责API和数据的访问的节点,不存储/处理数据
- Data Node,负责数据的存储和索引
- Master Node, 管理节点,负责Cluster中的节点的协调,不存储数据。
每一种角色可以通过ElasticSearch的配置文件或者环境变量来配置。每一种角色都可以很方便的Scale,因为Elastic采用了对等性的设计,也就是所有的角色是平等的,(Master Node会进行Leader Election,其中有一个是领导者)这样的设计使得在集群环境的伸缩性非常好,尤其是在容器环境,例如Docker Swarm或者Kubernetes中使用。
参考:
Splunk
Splunk