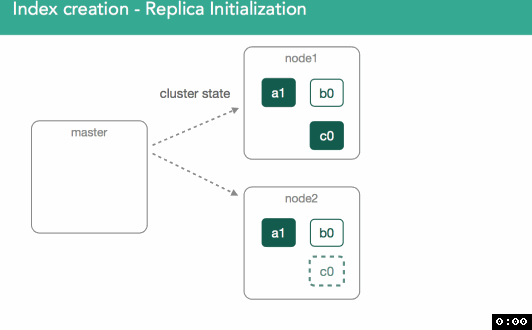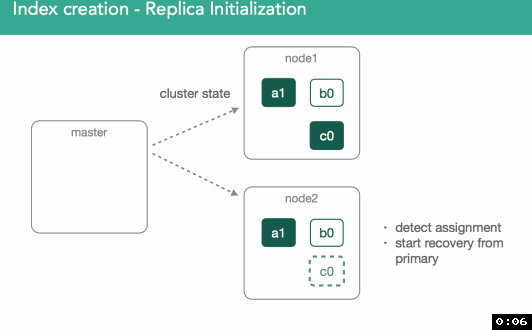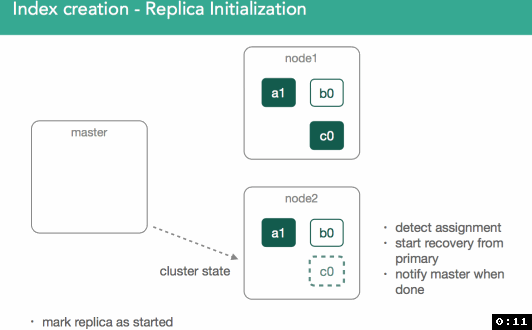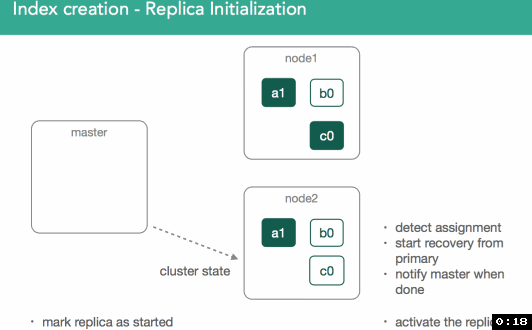
replica shard�����к�primary shardͬ�������ݡ�����������ͼ��ʾ����һ����master����Ҫ��ʼ��replica shard c0��ClusterState�㲥��������Ⱥ���ڶ�����node2̽��Լ���������һ���µ�shard
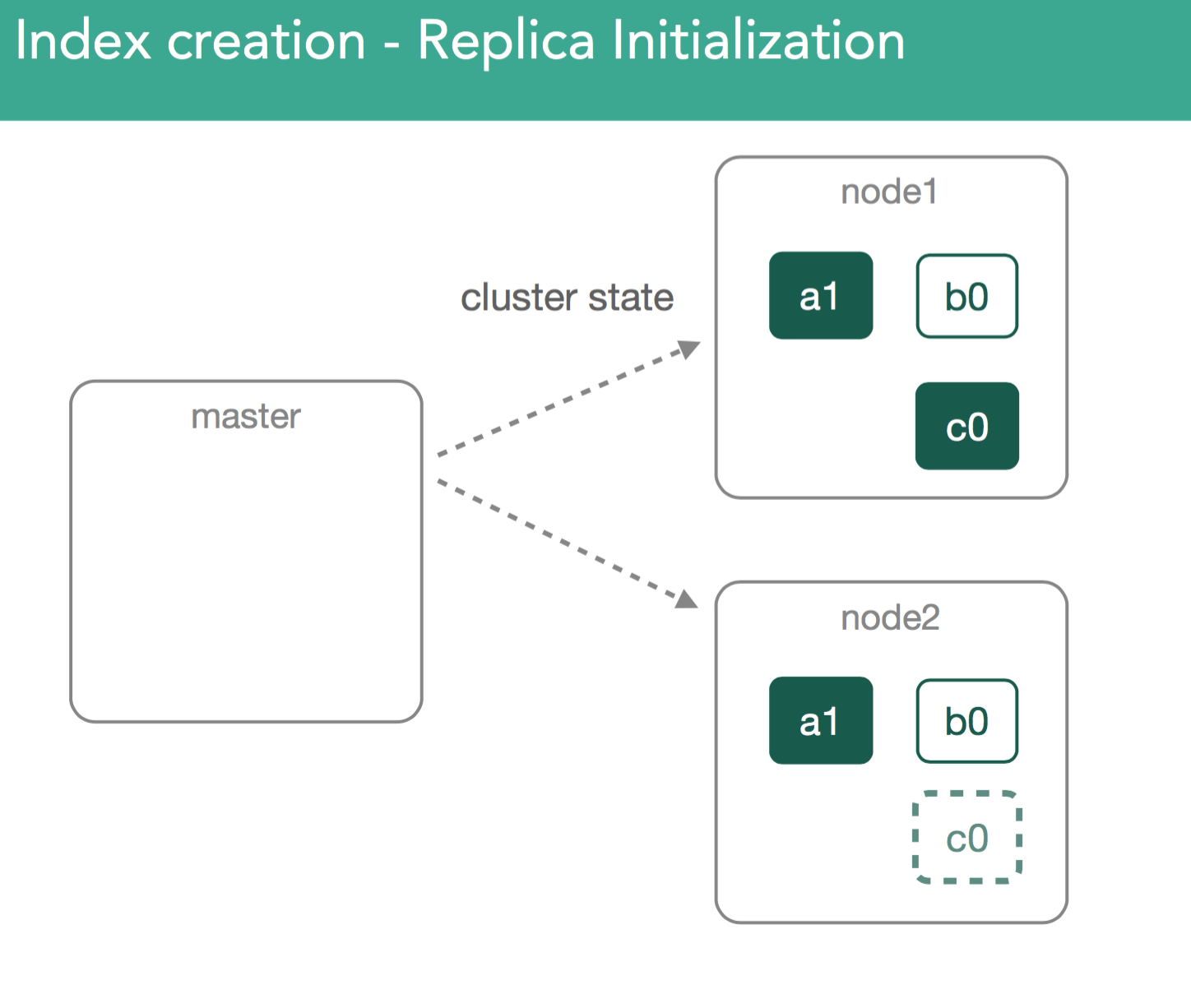
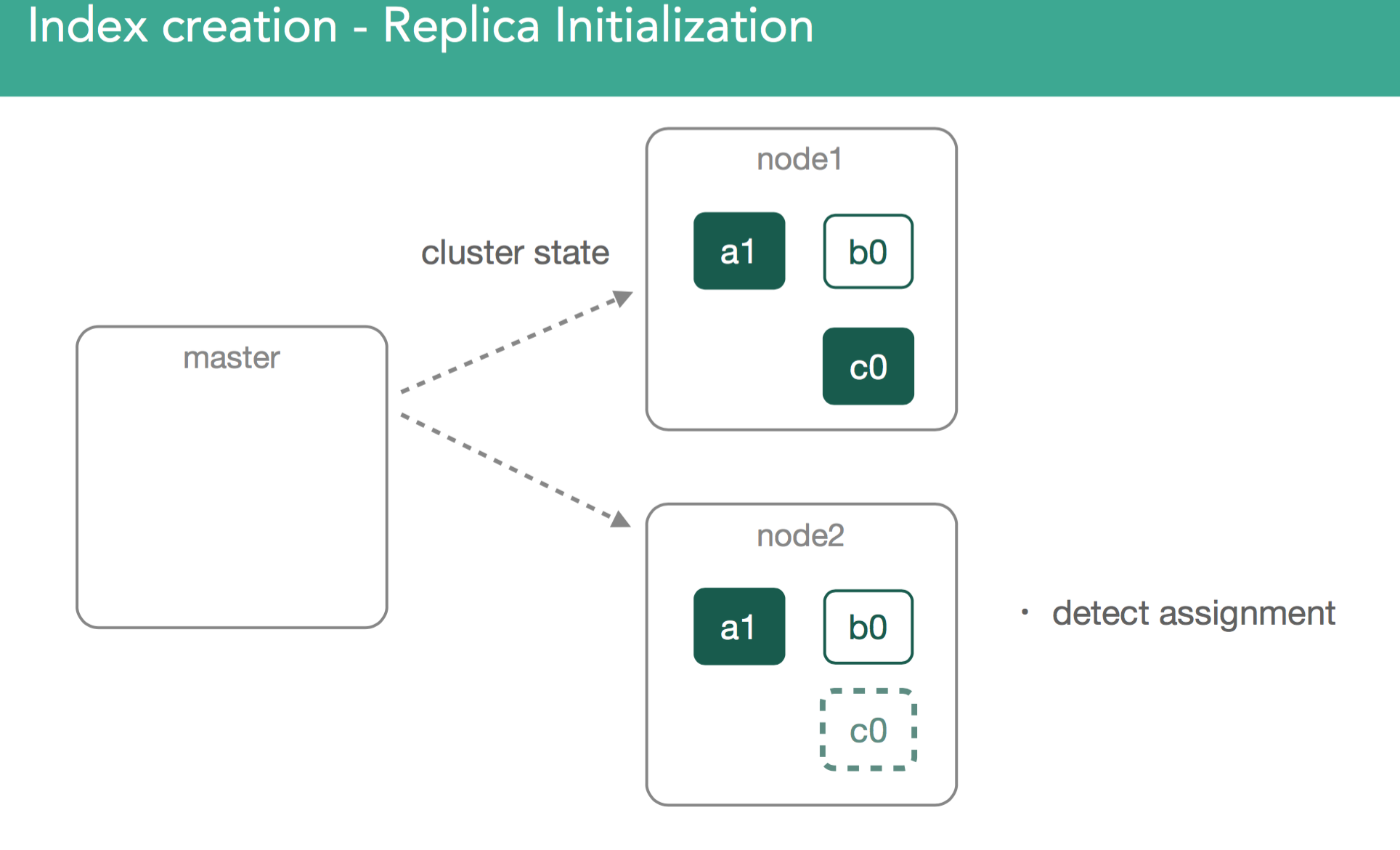
��replica shard������ɺ���Ҫ����ĺ���Ҫ��һ���ǣ����ǻ��primary shard��������ȱʧ�����ݵ�replica shard�����ݸ�����ɺ�master�Ż��replica shard��״̬��עΪ��started����������Ⱥ�й㲥һ���µ�ClusterState�������涯ͼ��ʾ
�������� ��ʱ���ƶ�shard��
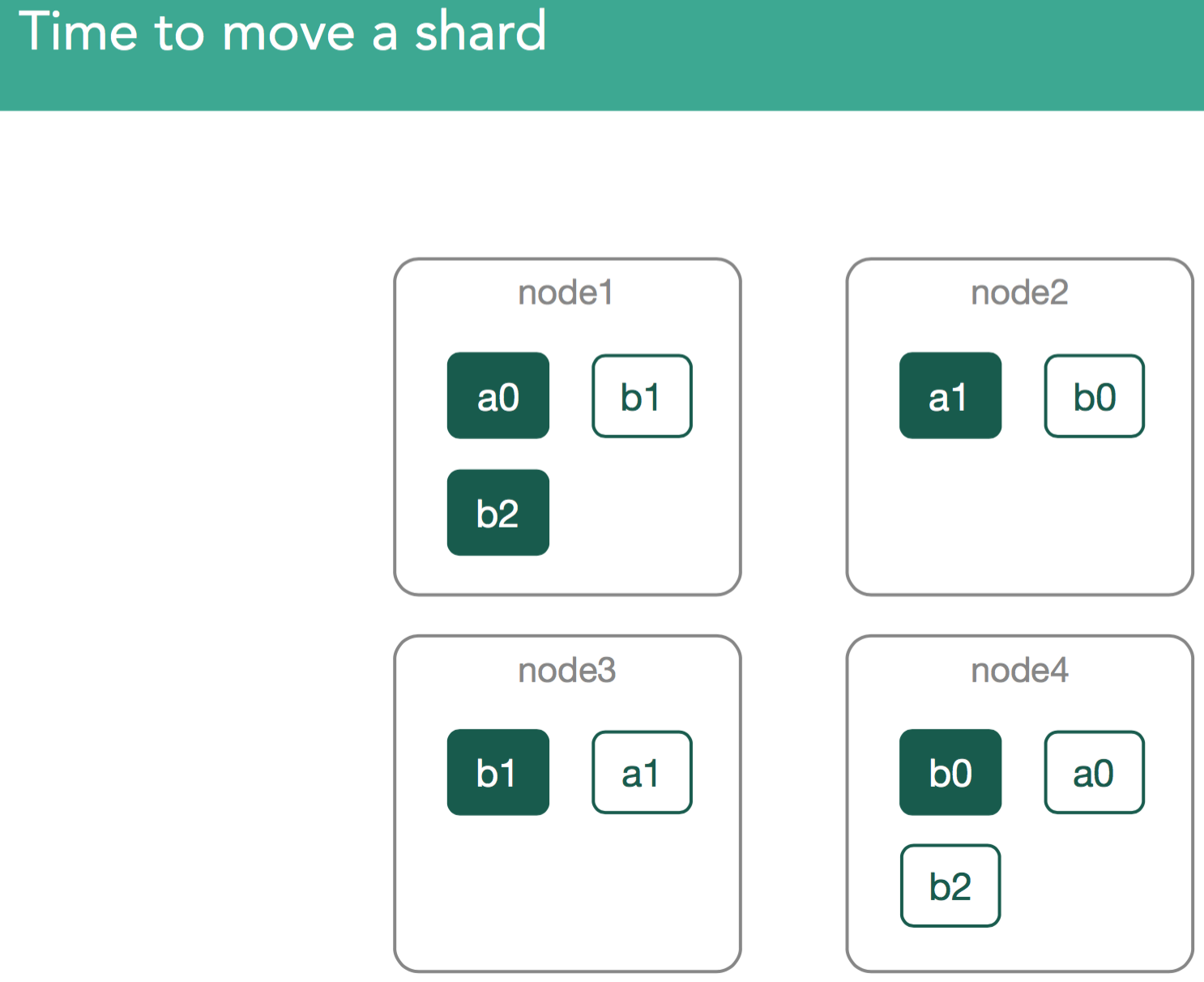
��ʱ��ļ�Ⱥ������Ҫ�ڼ�Ⱥ�ڲ��ƶ��Ѿ����ڵ�shard������ܻ��кܶ�ԭ��
1. �û�����
�ⷽ�������һ�����Ӿ���Hot/Warm���ã��������ϻ�ʱ�������Hot/Warm���ð������ƶ��������ٶȽ����Ĵ����ϡ�����ͼ��ʾ

2. �û�ʹ��������ʽ�ƶ�shard
�û�ͨ��cluster re-route������ʹ��elasticsearch��shard��һ���ط��Ƶ���һ���ط�
3. ������ص�����
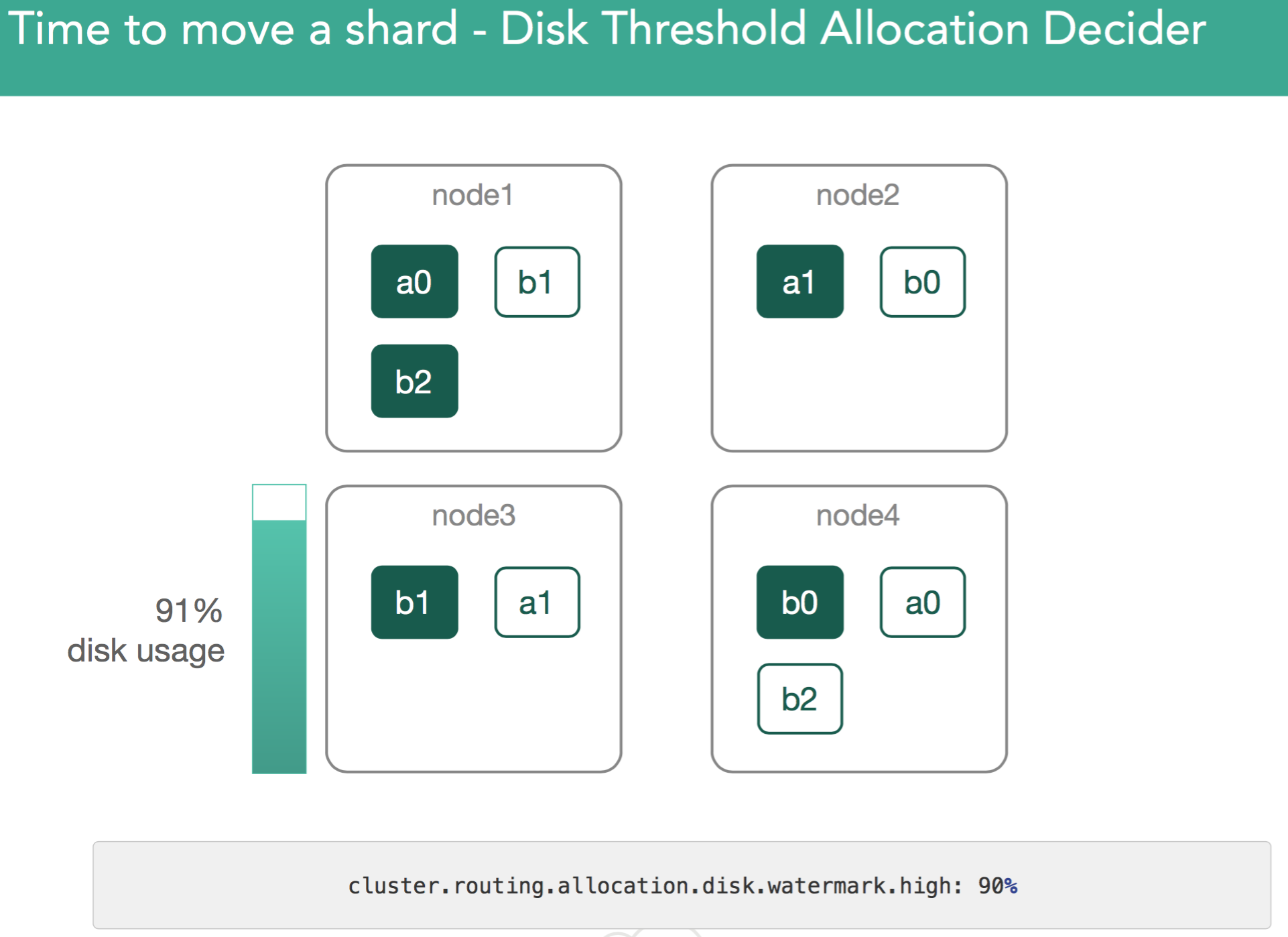
���������ʹ�ÿռ���ص������������ã�����������������Щ���õ���ֵ���ƶ�shard
- cluster.routing.allocation.disk.watermark.low
- cluster.routing.allocation.disk.watermark.high
������ˮλ��ֵʱ��elasticsearch����ֹ����д���µ�shard��ͬ����������ˮλ��ֵʱ��elasticsearch��Ѵ˽ڵ���shard���·��䵽�����ڵ��ϣ�ֱ����ǰ�ڵ�Ĵ���ռ�õ��ڸ�ˮλ��ֵ������ͼ��ʾ
4. ��Ⱥ���ӽڵ�
������ļ�Ⱥ�Ѿ��ﵽ���������������������һ���µĽڵ㣬��ʱelasticsearch������ƽ�⣨rebalance��������Ⱥ������ͼ��ʾ
Shard���ܻ�����ܶ�G�����ݣ���ˣ��ڼ�Ⱥ���ƶ����ǿ��ܲ������������Ӱ�졣Ϊʹ������̶��û������ƶ�shard�����ں�̨���С�Ҳ���Ǿ����ܵĽ����ƶ�shard��elasticsearch���������Ӱ�졣Ϊ�ˣ�������һ�����Ʋ�����indices.recovery.max_bytes_per_sec/cluster.routing.allocation.node_concurrent_recoveries) �����Ա�֤�ƶ�shard�ڼ���Ȼ���Լ�������Щshard�������ݡ�����ͼ��ʾ
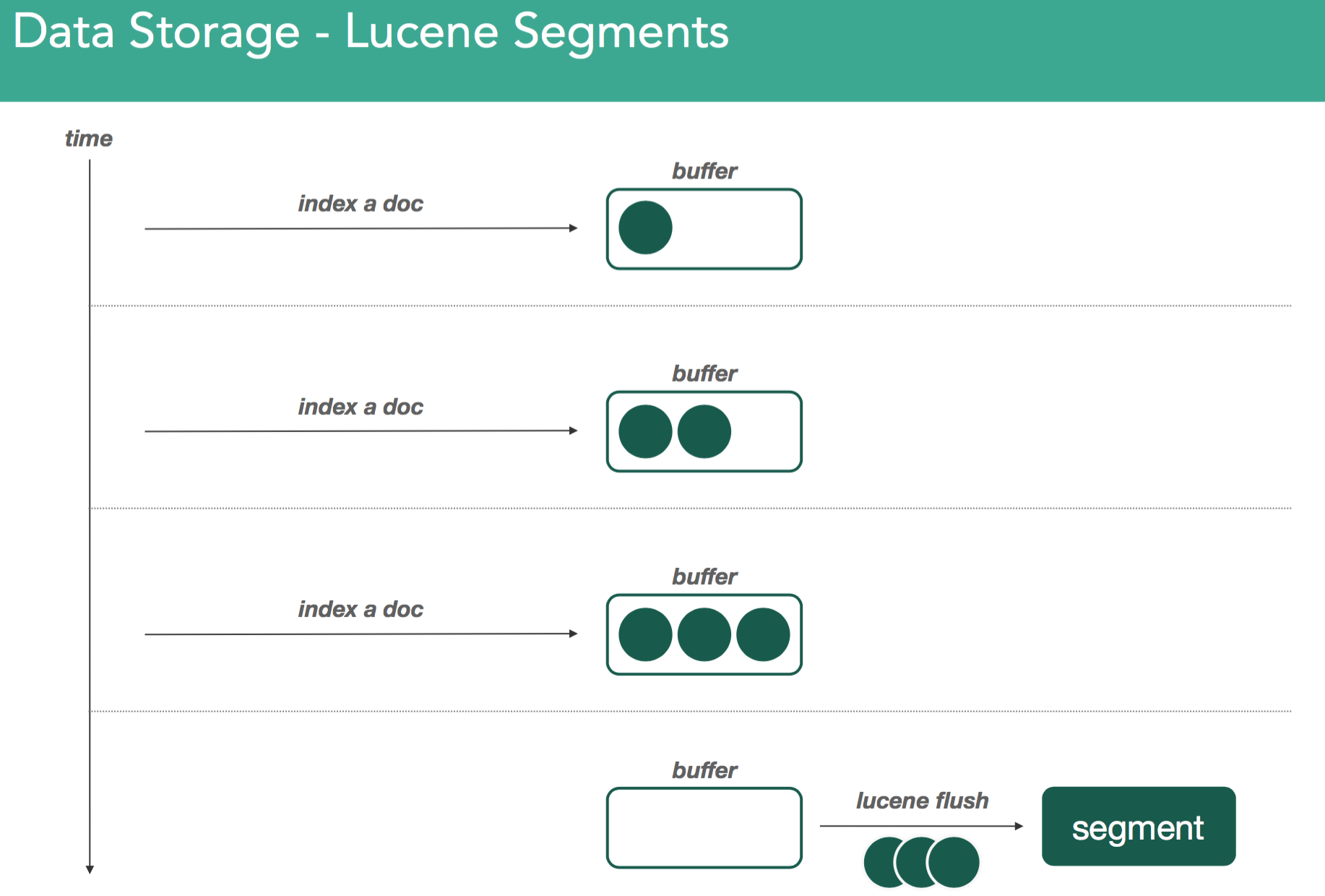
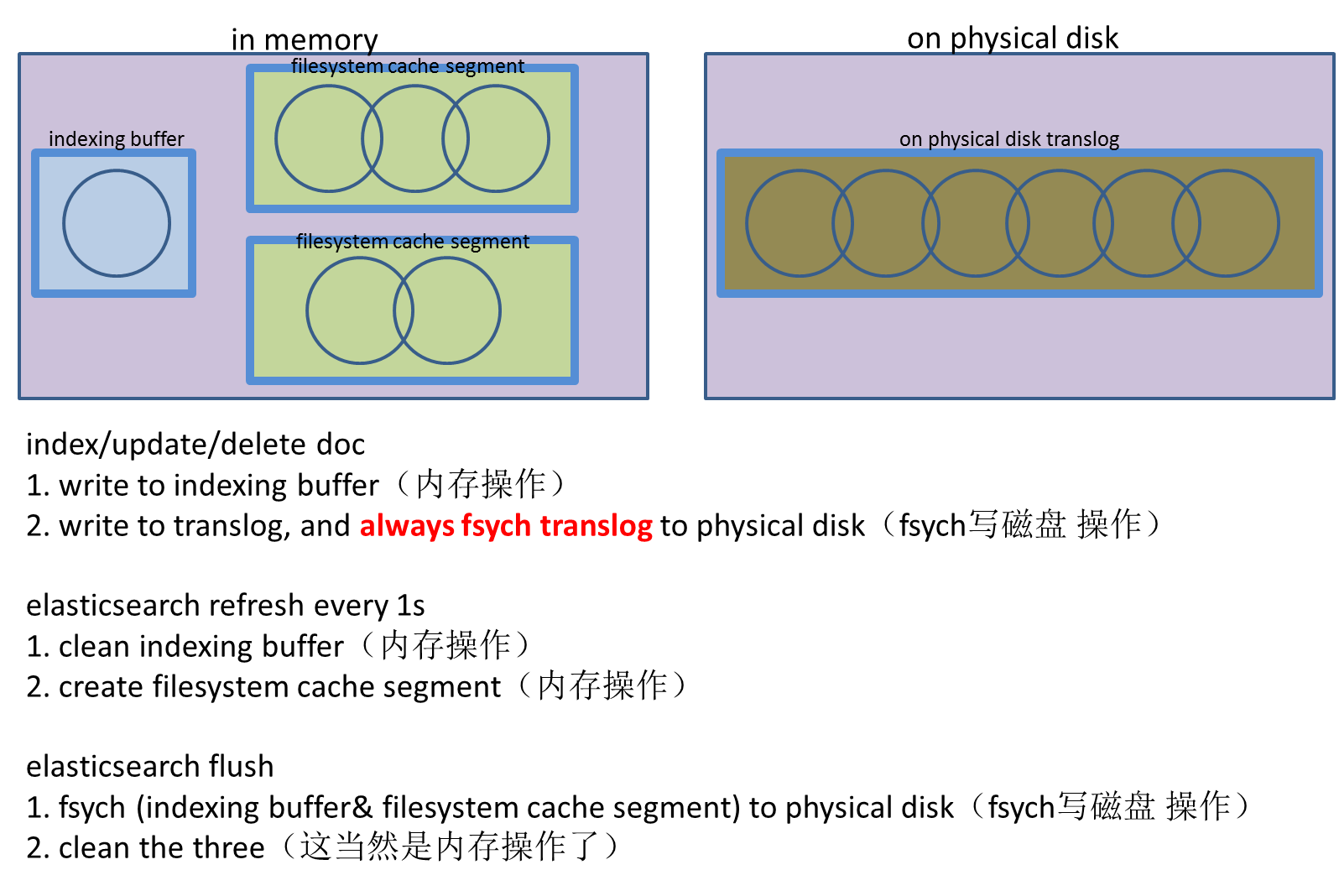
��ס��elasticsearch���������ݶ���ͨ��Lucene�洢�ġ�Luceneʹ�ñ���Ϊsegment��һ���ļ����洢һ�鵹��������������tokens/wordsʱ�����������ṹ���Է���ĸ�������Щtokens/words��������Щ�ĵ��У��������ĵ��е�ʲôλ�á���Lucene�����ĵ�ʱ���ĵ��ݴ����ڴ��е�indexing buffer����indexing buffer����elasticsearch����refresh�������Ӷ�����lucene flush��ʱ��indexing buffer�е����ݾͱ�ǿ��д�뱻��Ϊsegment�ĵ��������С�����ͼ��ʾ
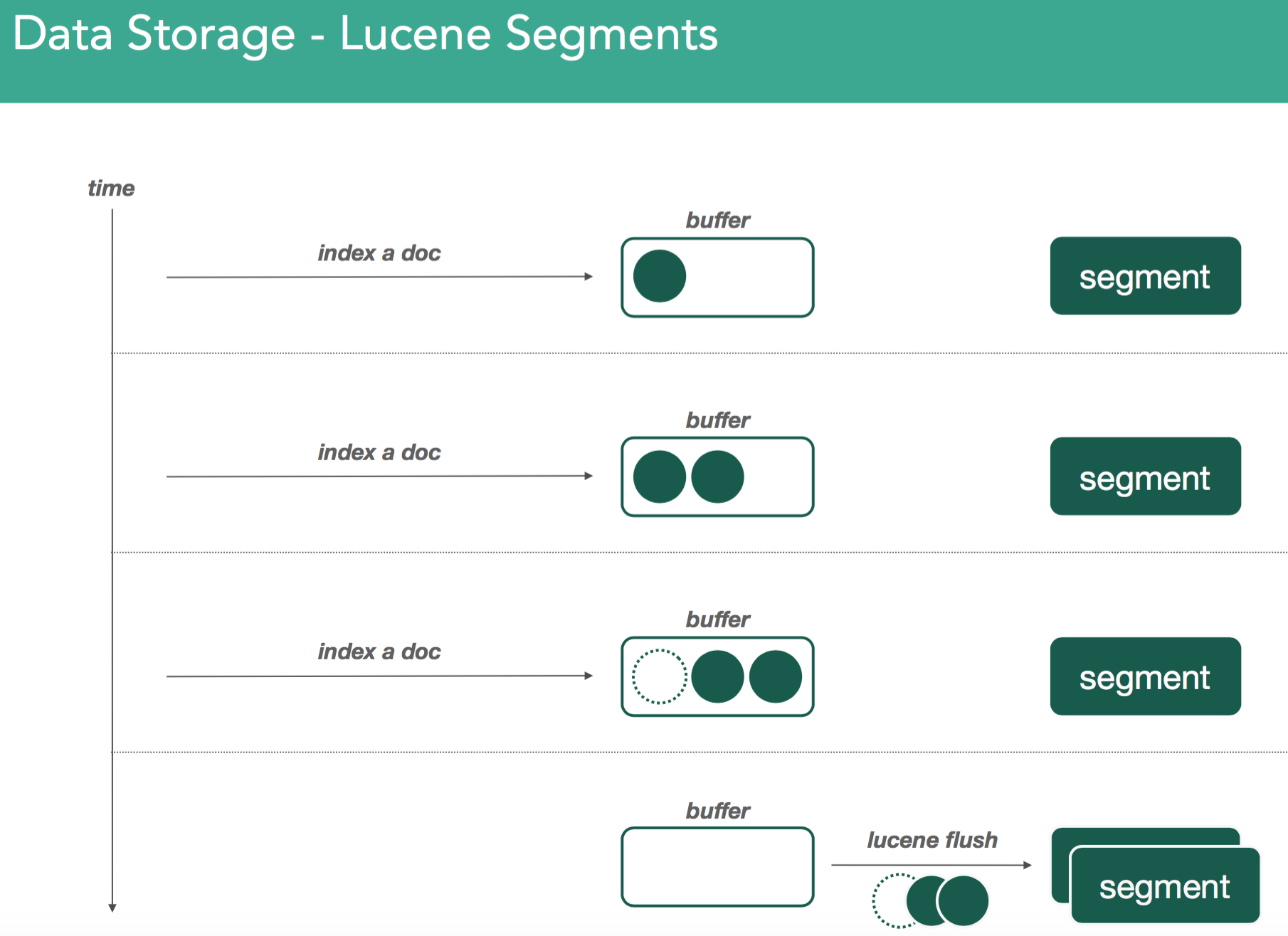
�������Ǽ��������ĵ������ǻ���ͬ���ķ�ʽ�����µ�segment������segment��һ����Ҫ���������segment�Dz��ɱ�ģ�immutable��������ζ�ţ�һ��д��һ��segment�����segment����Զ����ı��ˡ�����㷢��ɾ�����κθı䣬��Щ�������������µ�segment�ϣ����µ�segment��ͬ�������ϲ����̡�����ͼ��ʾ
��Ȼ�����Ǵ洢���ڴ�ģ��������������ύ��segment�ļ�֮ǰ����ע����ʹ��д��segmentҲ���ܻᶪʧ����Ϊsegmentд��filesystemʱ��ֻ��д�����ڴ漴filesystem cache��ֻ�е���filesystem��fsync�����ݲ�����д���˴��̡����������ܿ��ǣ�filesystem�������Զ�����ʵʱ�ĵ���fsync�ģ����������п��ܶ�ʧ�ġ�elasticsearchʹ��transaction log���������������ÿ���ĵ�������Luceneʱ���ĵ�Ҳ�ᱻд��transaction log������ͼ��ʾ
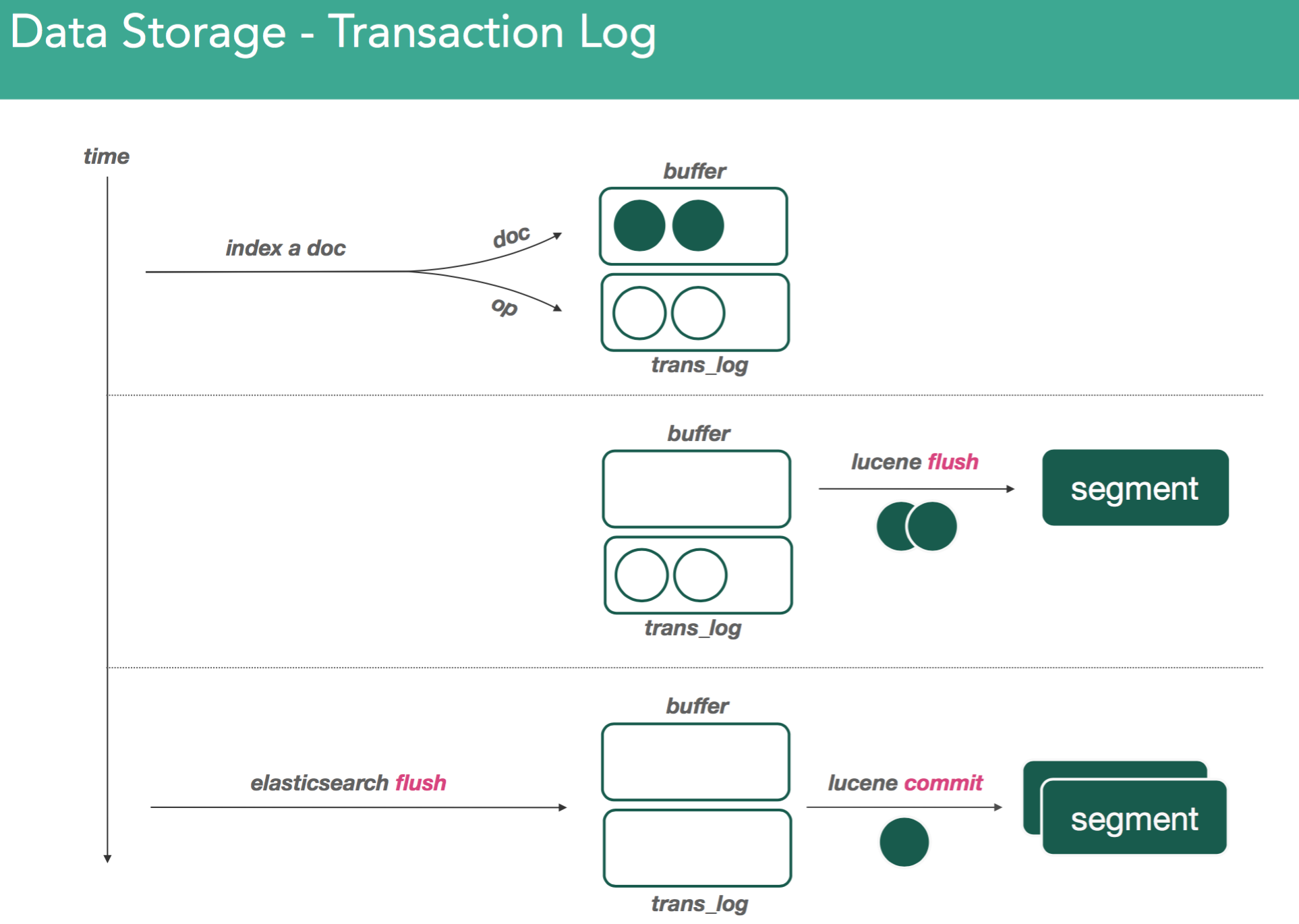
Transaction log��˳��д��ģ����һ������λ���ļ���ĩβ������transaction log�����ǾͿ��Իָ���δд��Lucene�е��ĵ���elasticsearch�ij־û�ģ������ͼ��ʾ
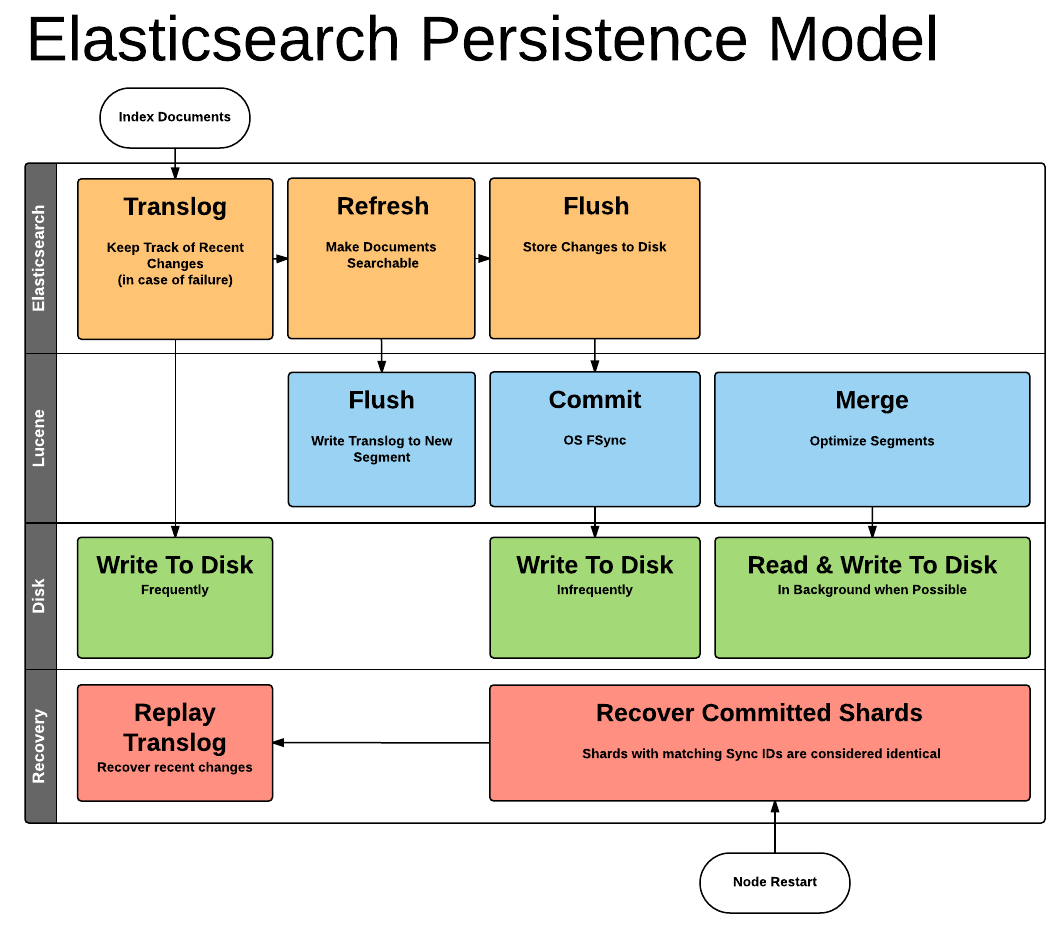
����segmentʱ���ܲ�δִ��fsync����ʱsegment���ݴ���filesystem cache�ڴ��У�OS���ݻ�ˢ�����ݵ����̡���ô���dz�������ԭ����ˣ�����Ҫ��filesystem cache�ڴ��е�segmentд�뵽���̣�ͬʱ���transaction log�����������ͨ��elasticsearch flush����ɵ�
������elasticsearch flush���Ӷ�����lucene commit������ʱ��������������
- ��indexing buffer�е�����д����̣��Ӷ�����һ���µ�segment
- �������е�segment�ļ�������filesystemʹ��fsync������segmentд�����
ִ��elasticsearch flush�Ͱ��ڴ����������ݣ���indexing buffer�е������Լ�filesystem cache�ڴ��е�segment����ͳͳд���˴��̣����������transaction log����ȷ�����Dz��ᶪʧ�κ����ݡ��������°��ã�relocation��shard��������Dz�����һ�������segment�������ǵõ�һ��ʱ���һ�������ݲ��ɱ�����ݿ���
��ע���ο�Elasticsearch: Ȩ��ָ�ϨC>�־û�����˽��ĵ�д����̡������ܽ�����ͼ��ʾ
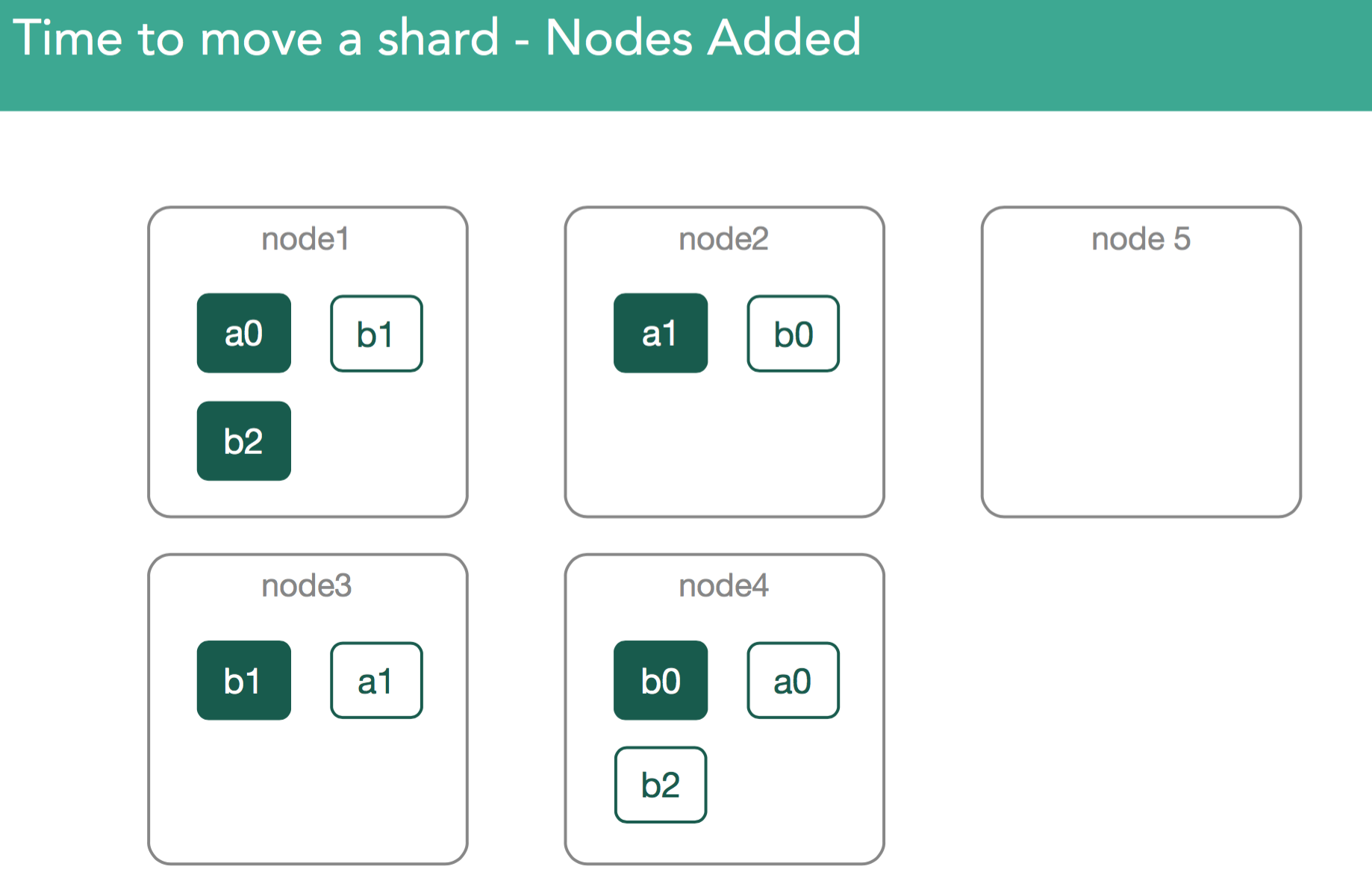
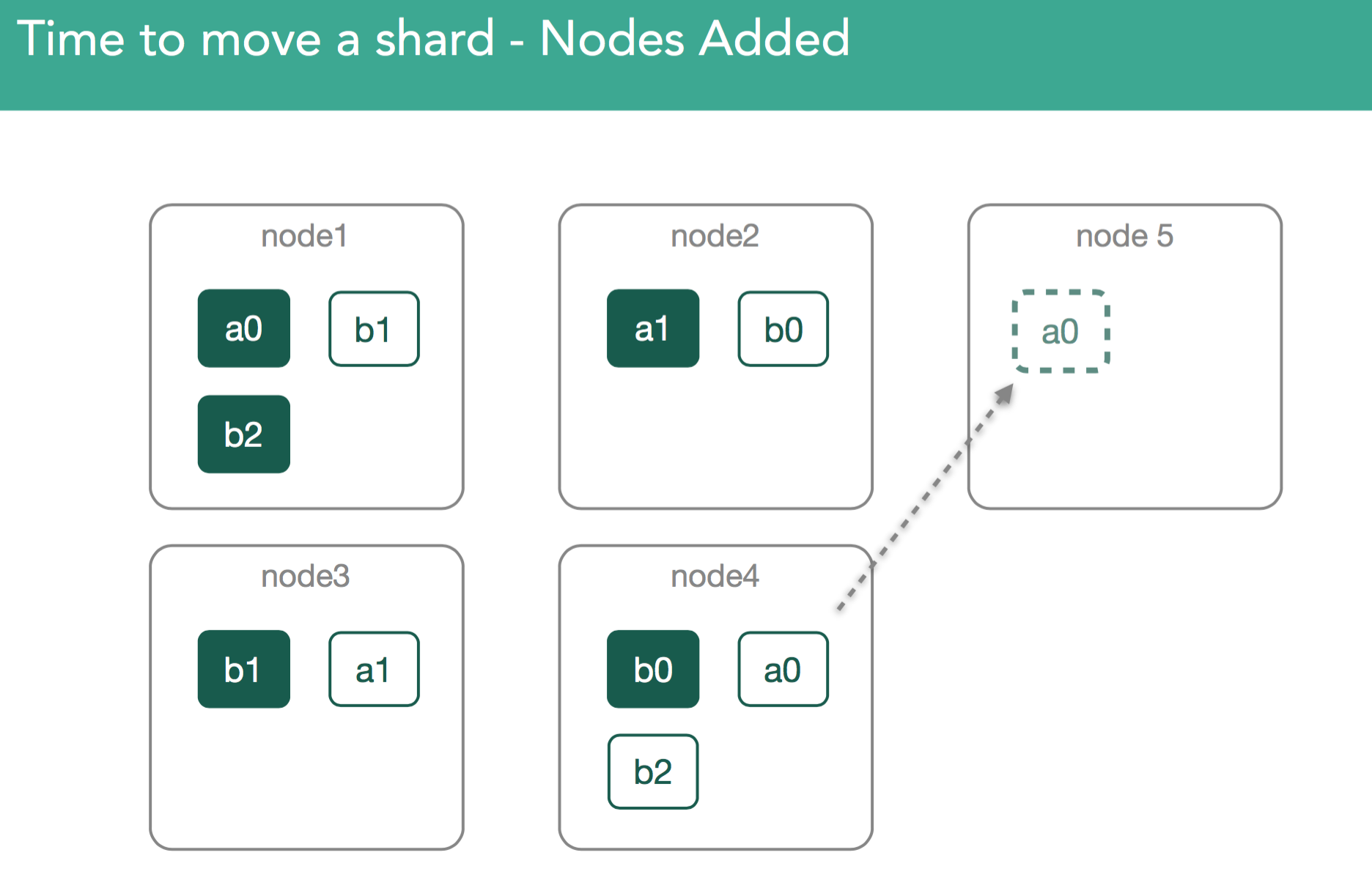
�����涯ͼΪ������Ⱥ��Ҫ��node4�ϵ�a0�ƶ���node5������master��עa0Ϊ���ڴ�node4���°��õ�node5��node5�յ��������node5�ϳ�ʼ��һ��shard���������Ϊ����һ���dz���Ҫ��������Ҫע�⣬����������ƽ��ʱ��������replica shard���ڴ�node4�ƶ���node5������ʵ�ϣ����°���shardʱ���Ǵ�primary shard�������ݵģ�����node1�ϵ�a0��

�����涯ͼΪ������������ʾ����node1�ϵ�primary shard���°��õ�node5������ס����ǰ����˵���������ݴ洢���ƣ�transaction log��lucene segment
������node5�ǿսڵ㣬node1����primary shard��ȫ����������
- master��node5������һ��modified ClusterState��masterҪ��node5��ʼ��һ���µ�shard
- node5̽��Լ���������һ���µ�shard
- node5��node1��node1����primary shard��������������ʼ�ָ�����
- node1�յ�node5������Ȼ��node1��֤���Լ�֪��node5���͵�����
- node1��֤ͨ����������node1�ϣ�elasticsearch�̶�tra