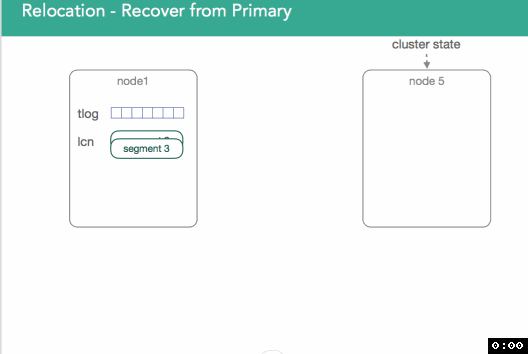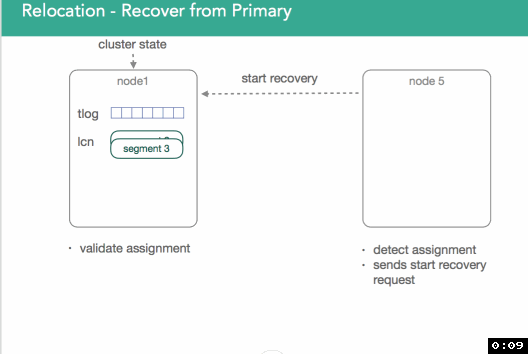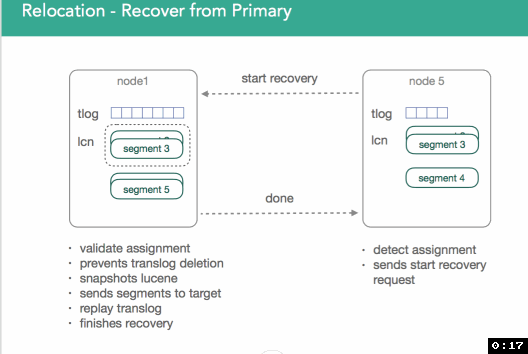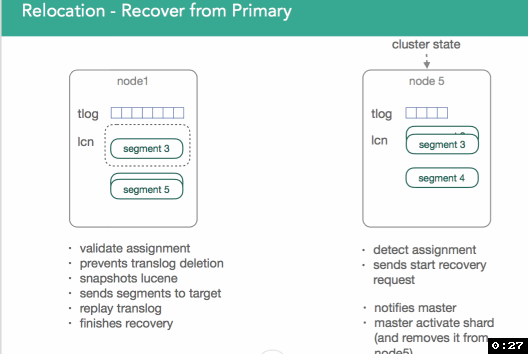
nsaction log以防止其被删除并捕获索引的segment快照,确保我们捕获了shard中的所有数据
node1将segment数据发送到node5上的目标文件
在node5重放node1的transaction log,这会确保数据复制期间新索引进来的文档也能复制进入到node5上的目标文件
node1发送“数据恢复已完成”给node5
node5告知master“node5上的shard已经就绪”
master发送modified ClusterState到node5,激活shard,将shard状态标注为”started”。同时,master删除掉node1上的源shard
上面这一切都在后台发生,因此整个过程中你依然可以向primary shard中索引数据。在这个过程中,如果确实又向primary shard中索引了新的数据,那么,这些新的数据并不包含在步骤5所捕获快照中,但这没有关系,因为通过步骤7重放node1的transaction log就可以确保这些新的数据也被复制进入了新的shard
现在问题来了,何时才能停下?复制过程中可能依然有新索引的文档进入primary shard,这意味着transaction log是一直增长的。在1.x中,我们的措施是锁定transaction log,从锁定点开始,所有再进来的请求都被阻塞,直到重放transaction log完成
在2.x/5.x中,我们作的更好。一旦我们开始重新安置(relocation),primary shard会把所有的索引操作发送到新的primary shard(位于node5上)。因为我们知道我们何时捕获的lucene快照,我们也知道shard是何时被初始化的,于是我们就确切的知道需要重放transaction log中的哪些数据
一旦恢复完成,目标节点(target node)给master发送通知,告知master“shard都已就绪”。master处理请求,复制剩余的primary shard(译注:因为一个索引可能存储多个primary shard),并激活shard。然后,源shard可以被移除了,这个过程一直重复,直到重新平衡(rebalancing)完成
场景三、 重启整个集群
我们要考察的下一个场景是重启整个集群。在这个场景中,我们并不处理激活的segment,而是在每个节点上找到本地数据。重启整个集群可能会发生在 维护周期,升级以及与计划中维护相关的任何事情
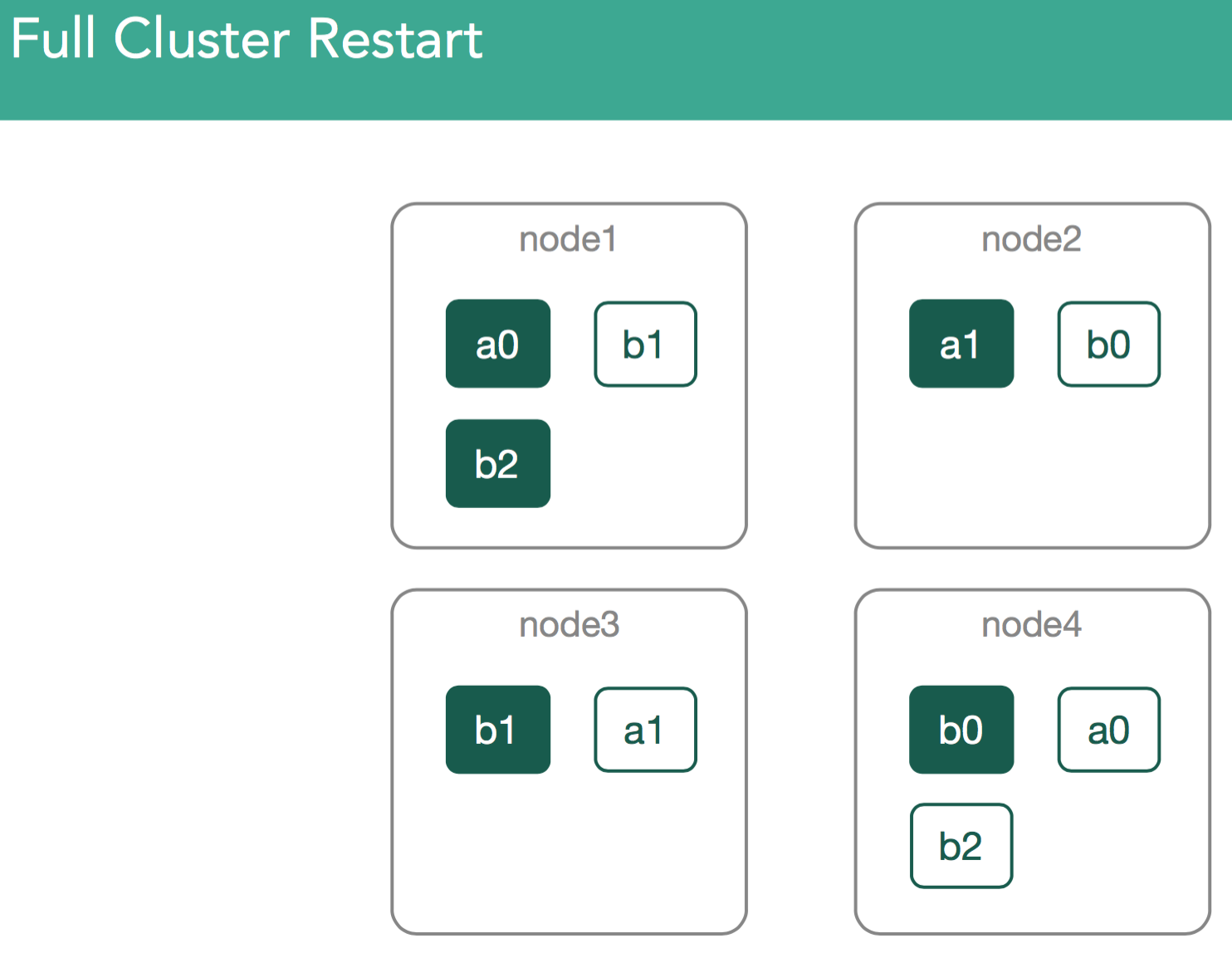
这里,master被选举出来,然后会新建一个ClusterState或者从磁盘恢复一个ClusterState。现在我们有了一个待分配的shard的列表,这些shard第一次被分配时,分配决定器可以把它们分配到任何一个节点上,但,现在不能再随便分配了。这意味着,我们需要找到这些数据,并确保我们能打开这些我们之前创建的lucene索引。如下图所示

为了做到这点(找到数据并打开之前创建的索引),master在集群中每一个节点上分配一个primary shard,且要求此primary shard返回磁盘上的所有内容。这意味着,我们物理上打开segment,然后通过确认一个shard副本来响应master。这时,master决定哪个节点将得到primary shard。在5.x中,我们会优先选择之前的primary shard(这是一个优化)。如下图所示
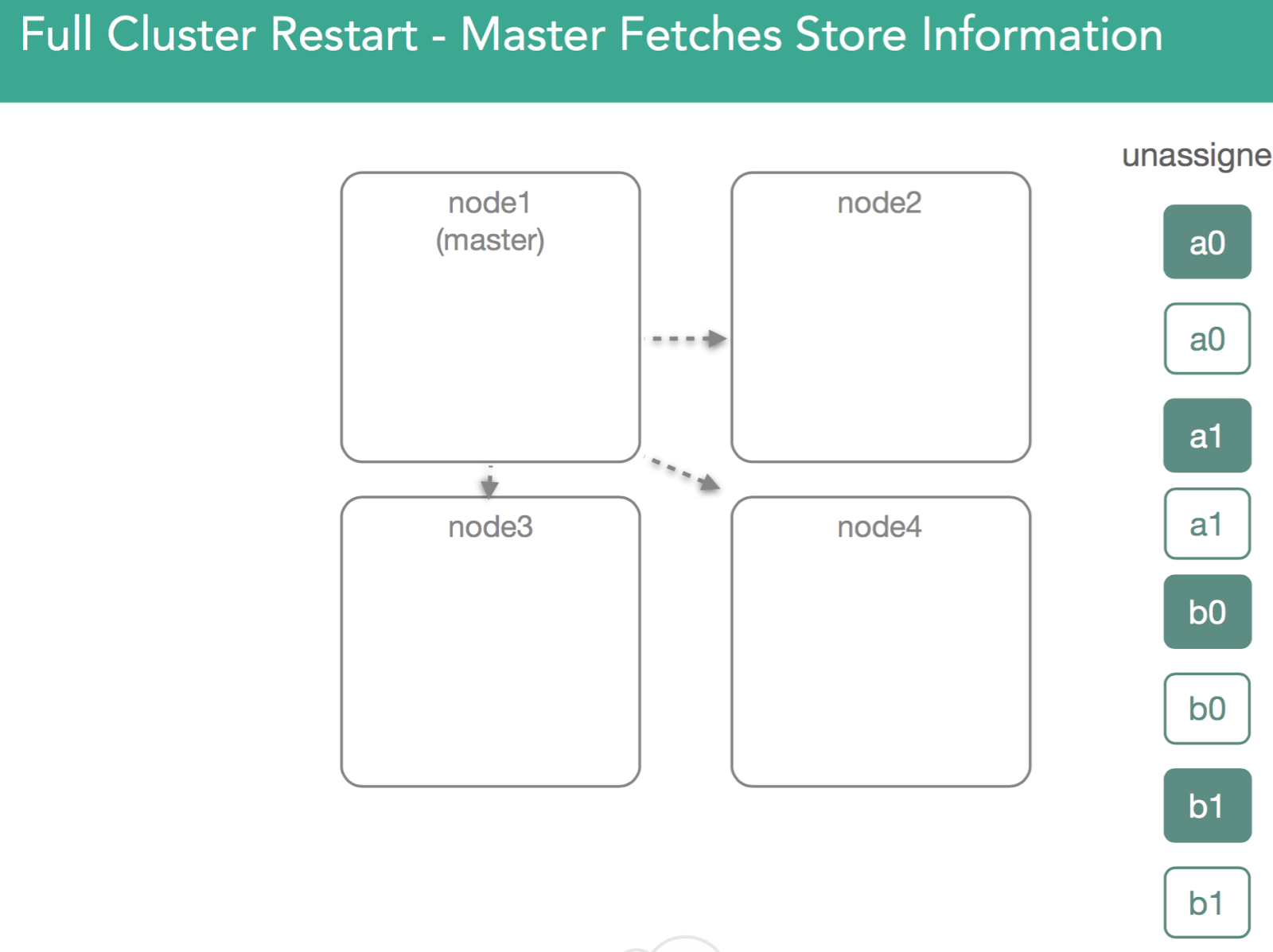
在下面的例子中,我们可以看到,node1上的a0之前是primary shard,但,其他任何副本都可能变成primary shard。在这个例子中,node4上的shard被标注为”initializing”,但,不同之处在于,这一次我们要使用已经存在的数据,并且可以检查节点上的lucene索引来验证lucene索引有效且可以打开。master会收到“shard已经就绪”、“shard已被分配”的通知,然后,master把这些shard的分配结果加入到集群状态中。如下面动图所示
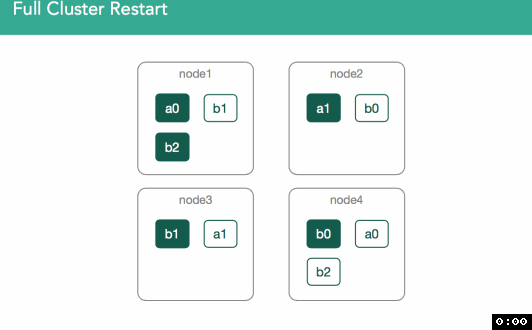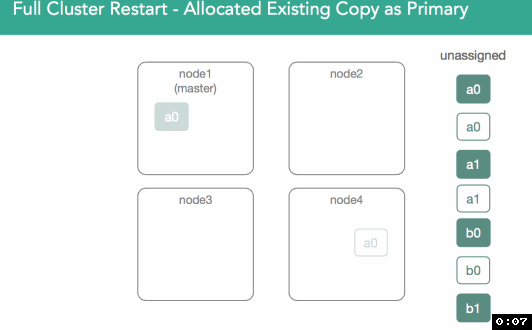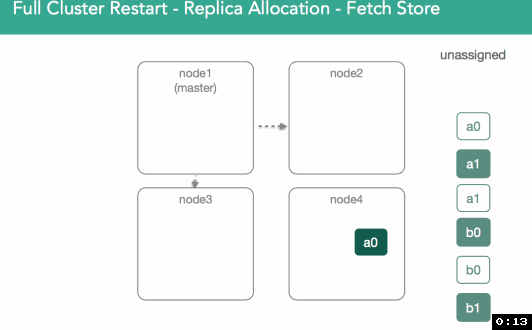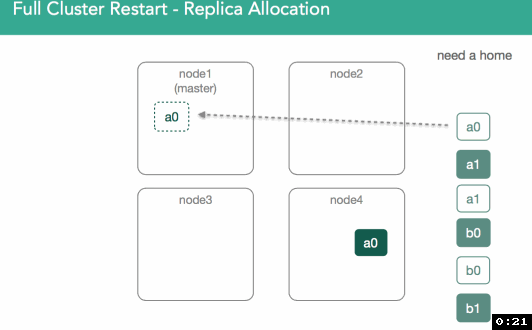
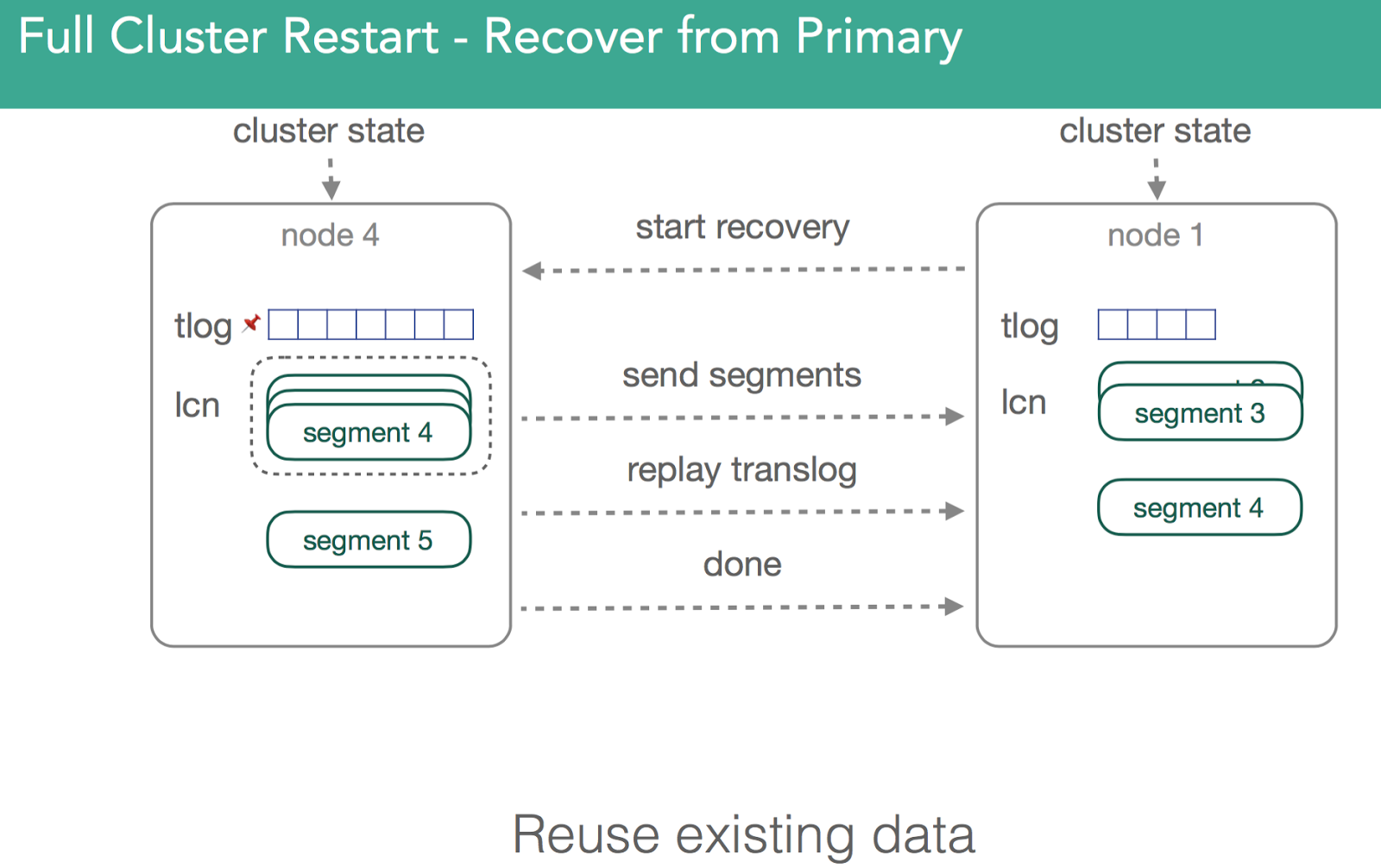
为了验证两个shard上数据是一样的,我们会有一个复制过程,这个过程和重新安置非常类似,不同之处在于因为所有shard副本都是从磁盘恢复得来的,这些shard可能已经是匹配的了,因此可能无需传输shard。此链接详细描述了这个过程。如下图所示
因为segment就是独立的lucene索引,大量索引文档之后,非常可能磁盘上的segment和其他节点上相同的segment并不一致。有些segment用了更多资源,有些segment拥有烦人的邻居(nosy neighbors)。如下图所示
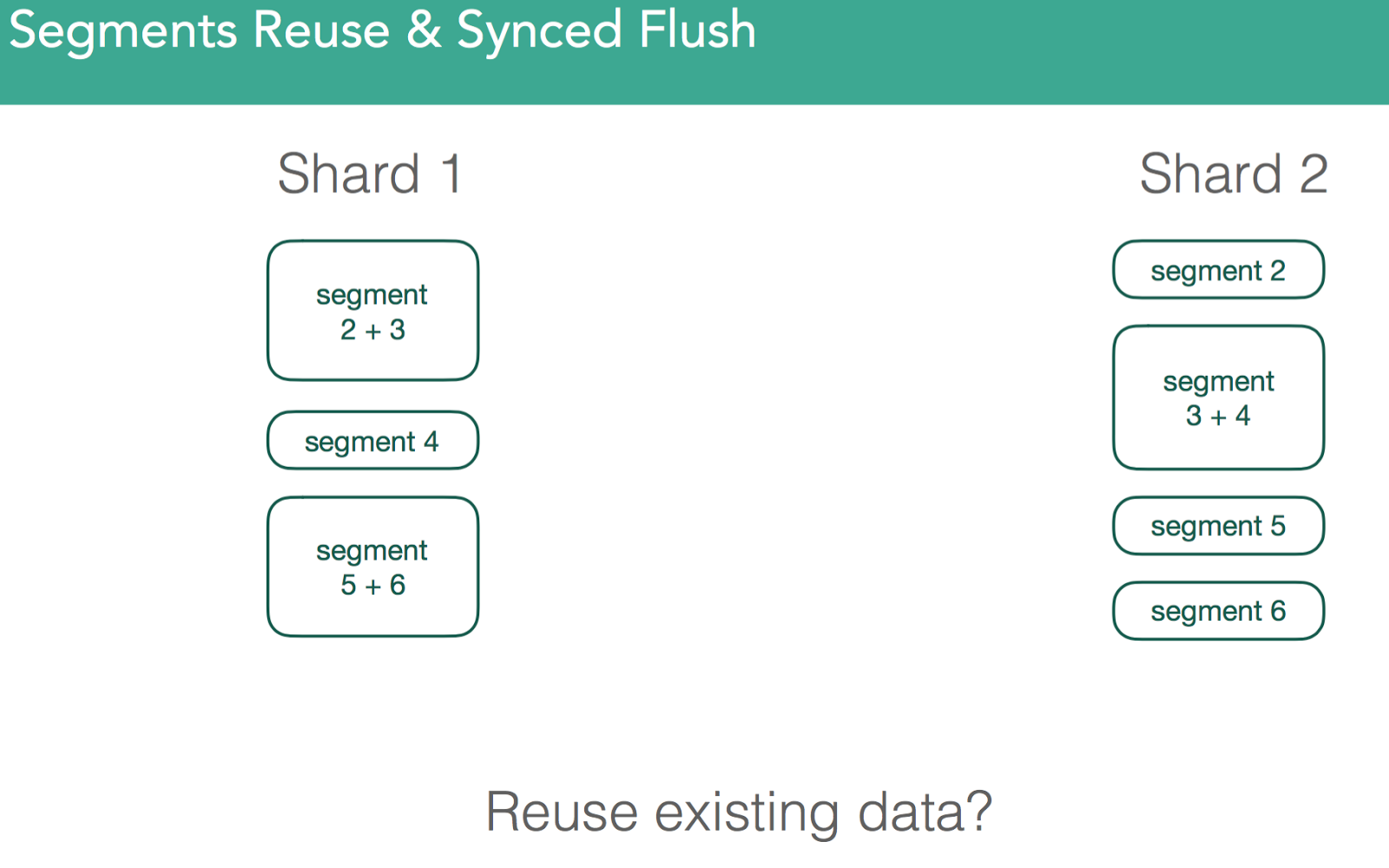
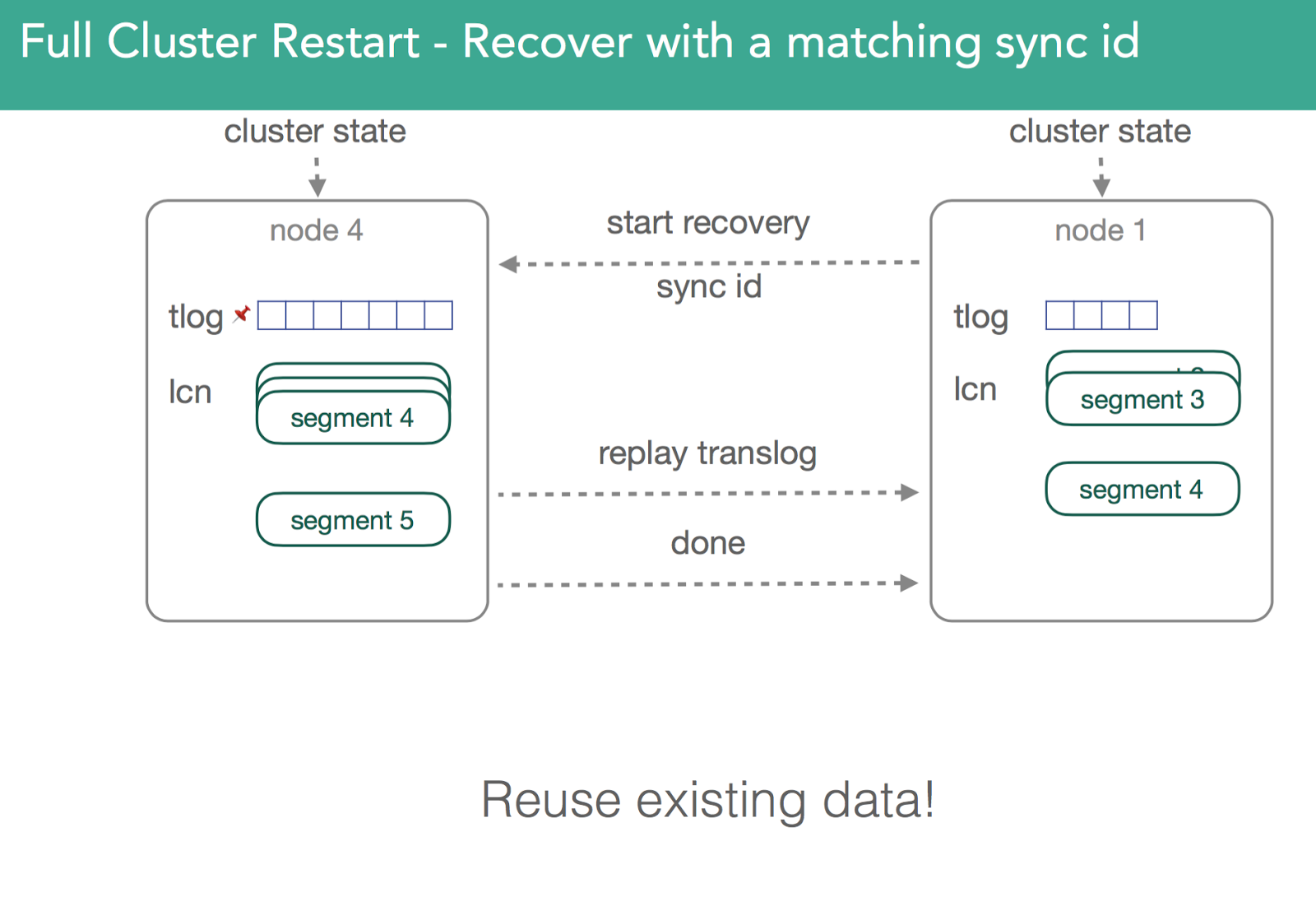
在v1.6之前,必须得复制所有segment。正是由于这些,v1.6之前的恢复是很慢的。我们必须得同步primary shard和replic shard,却又不能使用本地数据。为了解决这个问题,我们添加了sync_flush和sync_id。取不发生索引文档的某个时刻,使用一个唯一标识符来表示捕获的信息,确保同一个shard的各个副本是完全一致的。因此,当我们进行恢复时,我们发送sync_id标识符,如果标识符一致,则无需复制文件了,就可以重用老的副本。因为lucene中的segment是不可变的,这只对非激活的shard有效。注意:下图展示的是不同节点上的同一个shard,复制的数字就是发生的变化

场景四、 单个节点丢失(node3丢失)
在下图中,node3从集群中被移除了,node3上存储有b1的primary shard。此时,首先立即采取的步骤是master把当前位于node1上的b1的replica shard提升为primary shard。b1所在索引的健康状态以及集群的健康状态变成黄色,因为存在某个shard备份并没有全部被分配(shard所有备份的数量是用户在定义索引时指定的)。因此,master要尝试在剩下的某个节点上再分配一个新的b1的replica shard。如果node3是由于暂时的网络故障(或JVM GC引起的长时间STW)所导致,且,在网络故障恢复和节点再回到集群前,并未向shard中索引任何文档,则在node3缺席的这段时间内,在某个剩下的节点上重新复制一个新的b1的replica shard就纯属是浪费资源。如下面动图所示
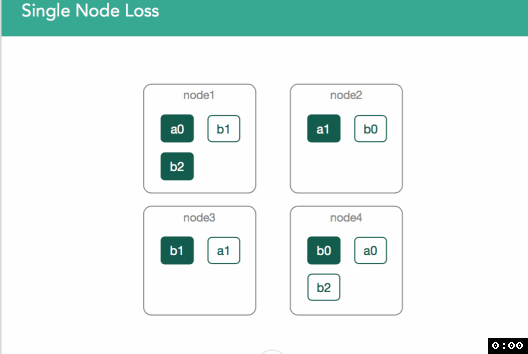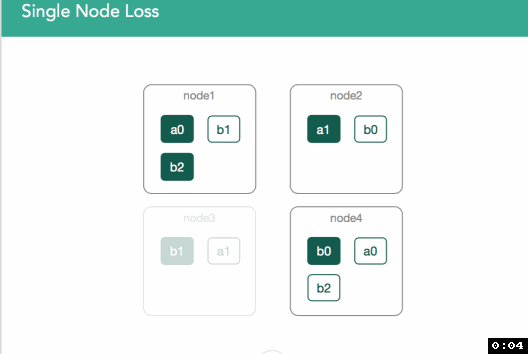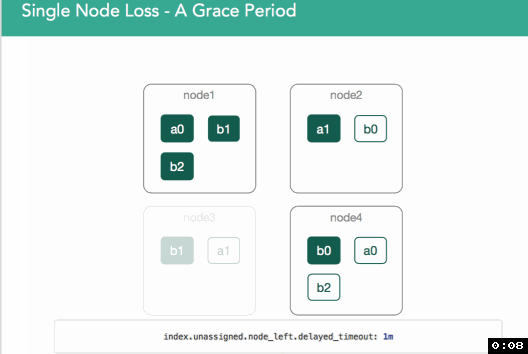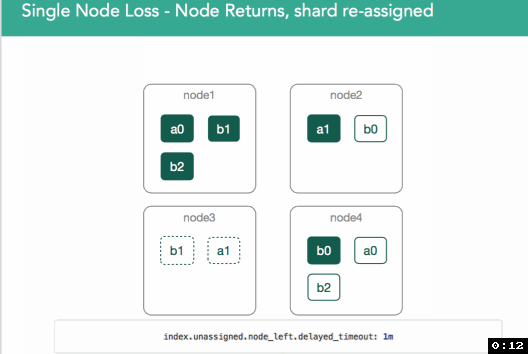
在v1.6中,引入了基于index(per-index)设置来解决这个问题(index.unassigned.node_left.delayed_timeout,默认1分钟)。当node3离开时,会先延迟此处指定的时长再进行重新分配shard。如果在此时长之前node3回来了,则考察primary shard较node3上的shard是否发生了变化,若在此期间,primary shard并未有任何变化,则node3上的shard就被指定为replica shard;若primary shard发生了变化,则丢弃node3上的shard,并且重新从primary shard复制shard到node3
在v2.0中,引入了一个改进,如果node3在延迟超时之后才回来,对于位于node3上且依然匹配primary shard的任何shard(使用sync_id标识符来决定匹配与否),即使重新复制已经开始了,这些重新复制过程也会