- ͨąýÔ´ÂëżÉŇÔż´łöŁ¬µ÷ÓĂ
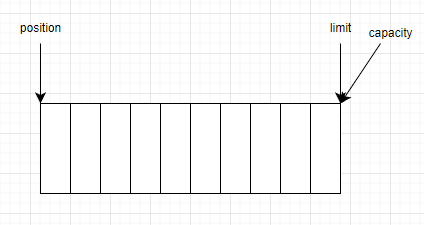
ByteBuffer.allocate(10)µÄʱşňŁ¬ÎŇĂÇłőĘĽ»ŻÁËŇ»¸öHeapByteBuffer¶ÔĎ󣬲˘˝«ĆäcapacityşÍlimitľůÉčÖĂÎŞ10Ł¬position±»ÉčÖĂÎŞ0ˇŁ
µă»÷˛éż´´úÂë
// ByteBuffer.java
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
// HeapByteBuffer.javaŁ¬µ÷ÓõÄHeapByteBufferÖеĹąÔě·˝·¨
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
}
- µ±µ÷ÓĂ
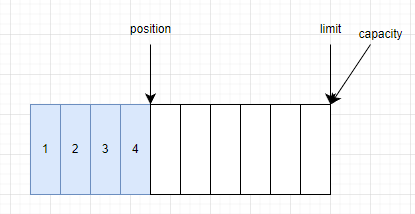
channel.read(buf)ĎňBufferÖĐĐ´ČëĘýľÝʱŁ¬¸ůľÝÔ´Âë·ÖÎöŁ¬Ćä×îÖŐ»áµ÷ČëByteBufferµÄput()·˝·¨ÖĐŁ¬HeapByteBuffer¶ÔĆäµÄʵĎÖČçĎÂŁ¬nextPutIndex()·˝·¨Ľě˛éµ±Ç°positionĘÇ·ń´óÓÚµČÓÚlimitŁ¬ČçąűСÓÚlimitŁ¬Ôň˝«Ôposition·µ»ŘŁ¬˛˘˝«ÔpositionĽÓ1ˇŁ
µă»÷˛éż´´úÂë
// HeapByteBuffer.java
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
- µ±Đ´ČëÍęłÉşóŁ¬ÎŇĂǵ÷ÓĂ
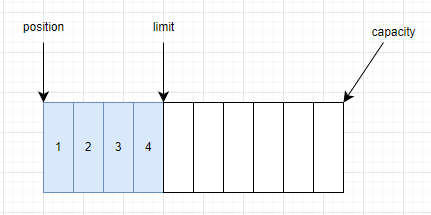
flip()·˝·¨Ł¬Ëůν˝«BufferÇĐ»»Î޶ÁÄŁĘ˝Ł¬ĆäʵԴÂëÖĐľÍĘÇ˝«positionşÍlimitµÄλÖĂÖŘиłÖµˇŁČç´Ë˛Ů×÷şóŁ¬positionľÍĘÇÎŇĂǶÁȡĘýľÝµÄĆđµăŁ¬limitľÍĘÇÎŇĂǶÁȡĘýľÝµÄÖյ㡣
µă»÷˛éż´´úÂë
// Buffer.java
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
- ÇĐ»»¶ÁÄŁĘ˝şóŁ¬ľÍżÉŇÔµ÷ÓĂ
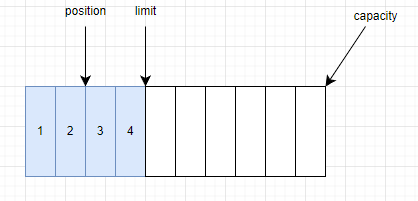
buffer.get()·˝·¨Ŕ´»ńȡһ¸ö×Ö˝ÚŁ¬Í¨ąýÔ´ÂëżÉŇÔż´łöŁ¬nextGetIndex()·˝·¨Ľě˛éµ±Ç°positionĘÇ·ń´óÓÚµČÓÚlimitŁ¬ČçąűСÓÚlimitŁ¬Ôň˝«ÔλÖĂ·µ»ŘŁ¬˛˘˝«ÔλÖĂĽÓ1ˇŁ
µă»÷˛éż´´úÂë
// HeapByteBuffer.java
public byte get() {
return hb[ix(nextGetIndex())];
}
-
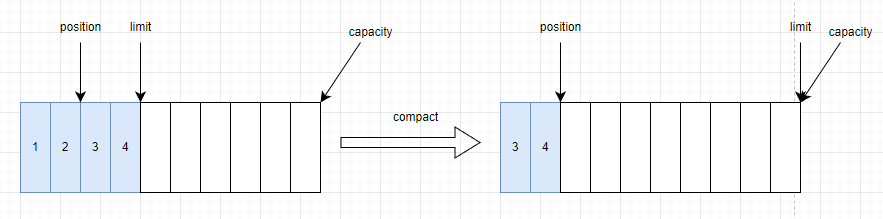
µ±¶ÁȡËůÓĐĘýľÝşóŁ¬żÉŇÔµ÷ÓĂbuffer.clear()·˝·¨»ňbuffer.compact()·˝·¨˝«BufferÇĐ»»ÎŞĐ´ÄŁĘ˝ˇŁ
clear(): Ö±˝Ó˝«BufferÖŘÖĂÎŞłőʼ״̬Ł¬şöÂÔ»ąĂ»ÓжÁÍęµÄĘýľÝˇŁcompact()Łş˝«»ąĂ»¶ÁÍęµÄĘýľÝ¸´ÖƵ˝»şłĺÇřÍ·˛żŁ¬Č»şó´ÓĂ»¶ÁÍęµÄĘýľÝşóżÉŇÔżŞĘĽĐ´ČëеÄĘýľÝ
µă»÷˛éż´´úÂë
// Buffer.java
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
// HeapByteBuffer.java
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining()); // ˝«»ąĂ»¶ÁÍęµÄĘýľÝż˝±´µ˝Ęý×éÍ·˛ż
position(remaining()); // ˝«positionÖŘÖĂÎŞĘŁÓŕ´ý¶ÁĘýľÝÖ®şó
limit(capacity()); // ˝«limitÖŘÖĂÎŞcapacity
discardMark();
return this;
}
markşÍreset
markĘÇBufferÖеÄÁíŇ»¸öĘôĐÔŁ¬ËüµÄÖ÷ŇŞÓĂÍľĘÇĽÇÂĽŇ»¸öpositionµÄλÖĂŁ¬şóĐřµ÷ÓĂreset()·˝·¨şó»á˝«positionÖŘÖõ˝markµÄλÖáŁmarkżÉŇÔ˛»±»¶¨Ň壬µ«ČçąűÉčÖĂÁËmarkµÄÖµŁ¬ÔňËü˛»ÄÜÎŞ¸şÖµÇҲ»ÄÜ´óÓÚpositionµÄÖµˇŁ
Őł°üşÍ°ë°ü
±ČČçÎŇĂÇĎëŇŞ·˘ËÍČýĐĐĘýľÝ
Hello world.\n
It is my life.\n
I love you.\n
ÎŞÁËĚá¸ß·˘ËÍЧÂĘŁ¬Í¨łŁÎŇĂǻὫŐâČýĐĐ×Ö·ű´®şĎ˛˘µ˝Ň»¸öBufferÖĐ˝řĐĐ·˘Ë͡ŁÁíŇ»¶ËÔÚ˝ÓĘŐµ˝ĎűϢʱŁ¬ÓÉÓÚĐŇ鲢˛»Ŕí˝âĎűϢµÄÄÚČÝŁ¬Ňň´ËÓĂ»§ÔÚ¶ÁȡĘýľÝʱŁ¬ÓĐżÉÄܶÁȡłöŔ´ČçĎÂÁ˝¸ö°üˇŁ
Hello world.\nIt is my life.\nI Lo
ve you.\n
ŐâŔďµÚŇ»¸ö°üłöĎÖÁËÔŔ´µÄÁ˝ĚőĘýľÝÔÚŇ»¸ö°üÖеÄÇéżöŁ¬ŐâľÍ˝Đ×öŐł°üˇŁµÚŇ»ĐĐ×îşóµÄĘýľÝ˝«ÔŔ´µÄŇ»ĚőĘýľÝ˝Ř¶ĎÁËŁ¬ŐâľÍ˝Đ×ö°ë°üˇŁ
ÎŇĂÇżÉŇÔͨąýČçĎ·˝Ę˝´¦ŔíŐł°üşÍ°ë°üµÄÎĘĚ⡣
µă»÷˛éż´´úÂë
public class TestStickyAndHalfPackage {
public static void main(String[] args) {
ByteBuffer p1 = ByteBuffer.allocate(64);
p1.put("Hello world.\nIt is my life.\nI lo".getBytes());
split(p1);
p1.put("ve you.\n".getBytes());
split(p1);
}
private static void split(ByteBuffer buffer) {
buffer.flip();
for (int i = 0; i < buffer.limit(); ++i) {
if (buffer.get(i) == '\n') {
int len = i + 1 - buffer.position();
ByteBuffer line = ByteBuffer.allocate(len);
for (int j = 0; j < len; ++j) {
line.put(buffer.get());
}
line.flip();
System.out.print(StandardCharsets.UTF_8.decode(line));
}
}
buffer.compact(); // ˝«Ă»ÓжÁÍęµÄĘýľÝŇƶŻµ˝bufferÍ·˛żŁ¬ŐâŔďĘÇ´¦Ŕí°ë°üşÍŐł°üµÄąŘĽü
}
}
SelectorŁ¨ŃˇÔńĆ÷Ł©
¸ĹÄîĽĚłĐÓÚ˛Ů×÷ϵͳIOÄŁĐÍÖжŕ·¸´ÓĂIOÄŁĐÍÖеÄselectorŁ¬ĆäÖ÷ŇŞ×÷ÓĂĘÇŁ¬ÓĂ»§żÉŇÔ°ŃËůÓжÁĐ´Channel¶Ľ×˘˛áÔÚÄł¸öSelectorÉĎŁ¬Selector»á˛»¶ĎµÄÂÖѯע˛áÔÚÉĎĂćµÄËůÓĐchannelŁ¬ČçąűÄł¸öchannelÎŞ¶ÁĐ´µČĘÂĽţ×öşĂ׼±¸Ł¬ÄÇĂ´ľÍ´¦ÓÚľÍĐ÷״̬Ł¬Í¨ąýSelectorżÉŇÔ˛»¶ĎÂÖŃŻ·˘ĎÖłöľÍĐ÷µÄchannelŁ¬˝řĐĐşóĐřµÄIO˛Ů×÷ˇŁÎŞşÎŇŞ×öŐâÖÖÉčĽĆÄŘŁż
Čçąűÿһ¸öChannel¶ĽĐčŇŞŇ»¸öĎßłĚŔ´ÎŞĆäIOąýłĚĚáą©·ţÎńŁ¬Ôň»áŐĽÓĂ´óÁżµÄÄڴ棬CPUĐčŇŞÔںܶŕĎ̼߳ä˝řĐĐÇĐ»»Ł¬ÓĐĚ«¶ŕ¶îÍ⿪ĎúŁ¬¶řÇŇËć×ĹÁ¬˝ÓĘýÁżÔöĽÓŁ¬ĎßłĚĘýÁż»á´ďµ˝ÉĎĎŢŁ¬ÎŢ·¨Ö§łÖ´óÁ¬˝ÓĘýˇŁ
ÓĐŇ»ÖÖ˝âľö·˝°¸ĘÇĘąÓĂÓй̶¨ĎßłĚĘýÁżµÄĎ̳߳ŘŔ´´¦ŔíËůÓĐÁ¬˝ÓÇëÇ󣬵«Ď̳߳ŘÖеÄĎßłĚŇ»µ©±»ŐĽÓĂŁ¬ľÍŇŞ×čČűµČ´ýIOÍęłÉ˛ĹÄܱ»ĆäËűÁ¬˝ÓĘąÓĂŁ¬ČçąűIOÇëÇ󻨷ŃʱĽäşÜł¤Ł¬ÄǻᵼÖÂşóĐřµÄ´óÁżIOÇëÇóĐčŇŞĹŶӵȴýˇŁŐâÖÖ