disruptor经过几年的发展,似乎已经成为性能优化的大杀器,几乎每个想优化性能的项目宣称自己用上了disruptor,性能都会呈现质的跃进。毕竟,最好的例子就是LMAX自己的架构设计,支撑了600w/s的吞吐。
本文试图从代码层面将关键问题做些解答。
基本概念
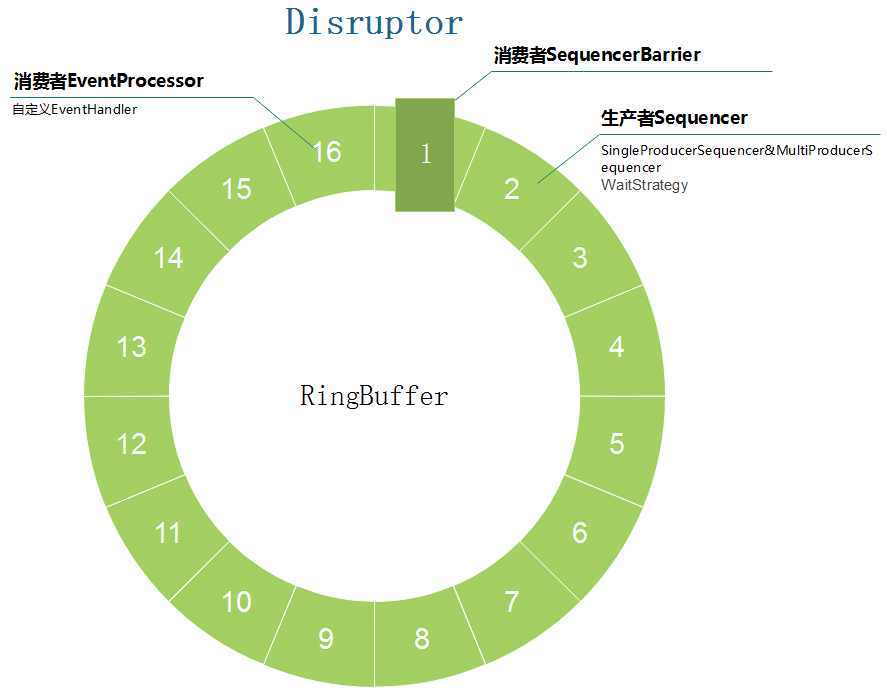
Disruptor: 实际上就是整个基于ringBuffer实现的生产者消费者模式的容器。
RingBuffer: 著名的环形队列,可以类比为BlockingQueue之类的队列,ringBuffer的使用,使得内存被循环使用,减少了某些场景的内存分配回收扩容等耗时操作。
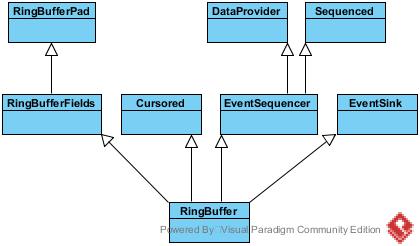
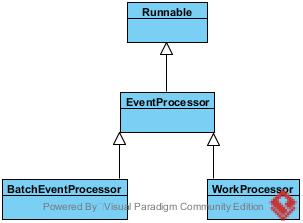
EventProcessor: 事件处理器,实际上可以理解为消费者模型的框架,实现了线程Runnable的run方法,将循环判断等操作封在了里面。
EventHandler: 事件处置器,与前面处理器的不同是,事件处置器不负责框架内的行为,仅仅是EventProcessor作为消费者框架对外预留的扩展点罢了。
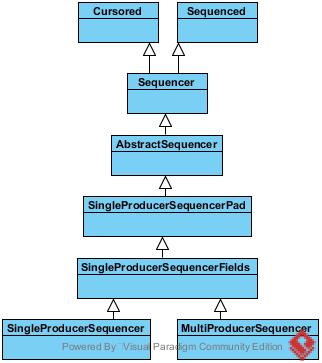
Sequencer: 作为RingBuffer生产者的父接口,其直接实现有SingleProducerSequencer和MultiProducerSequencer。
EventTranslator: 事件转换器。实际上就是新事件向旧事件覆盖的接口定义。
SequenceBarrier: 消费者路障。规定了消费者如何向下走。都说disruptor无锁,事实上,该路障算是变向的锁。
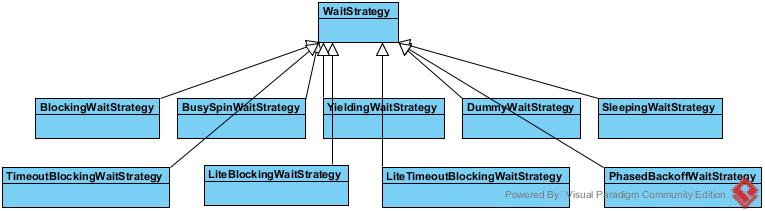
WaitStrategy: 当生产者生产得太快而消费者消费得太慢时的等待策略。
把上面几个关键概念画个图,大概长这样:
所以接下来主要也就从生产者,消费者以及ringBuffer3个维度去看disruptor是如何玩的。
生产者
生产者发布消息的过程从disruptor的publish方法为入口,实际调用了ringBuffer的publish方法。publish方法主要做了几件事,一是先确保能拿到后面的n个sequence;二是使用translator来填充新数据到相应的位置;三是真正的声明这些位置已经发布完成。
public void publishEvent(EventTranslator<E> translator)
{
final long sequence = sequencer.next();
translateAndPublish(translator, sequence);
}
public void publishEvents(EventTranslator<E>[] translators, int batchStartsAt, int batchSize)
{
checkBounds(translators, batchStartsAt, batchSize);
final long finalSequence = sequencer.next(batchSize);
translateAndPublishBatch(translators, batchStartsAt, batchSize, finalSequence);
}
获取生产者下一个sequence的方法,细节已经注释,实际上最终目的就是确保生产者和消费者互相不越界。
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
//该生产者发布的最大序列号
long nextValue = this.nextValue;
//该生产者欲发布的序列号
long nextSequence = nextValue + n;
//覆盖点,即该生产者如果发布了这次的序列号,那它最终会落在哪个位置,实际上是nextSequence做了算术处理以后的值,最终目的是统一计算,否则就要去判绝对值以及取模等麻烦操作
long wrapPoint = nextSequence - bufferSize;
//所有消费者中消费得最慢那个的前一个序列号
long cachedGatingSequence = this.cachedValue;
//这里两个判断条件:一是看生产者生产是不是超过了消费者,所以判断的是覆盖点是否超过了最慢消费者;二是看消费者是否超过了当前生产者的最大序号,判断的是消费者是不是比生产者还快这种异常情况
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
cursor.setVolatile(nextValue); // StoreLoad fence
long minSequence;
//覆盖点是不是已经超过了最慢消费者和当前生产者序列号的最小者(这两个有点难理解,实际上就是覆盖点不能超过最慢那个生产者,也不能超过当前自身,比如一次发布超过bufferSize),gatingSequences的处理也是类似算术处理,也可以看成是相对于原点是正还是负
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{
//唤醒阻塞的消费者
waitStrategy.signalAllWhenBlocking();
//等上1纳秒
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
//把这个最慢消费者缓存下来,以便下一次使用
this.cachedValue = minSequence;
}
//把当前序列号更新为欲发布序列号
this.nextValue = nextSequence;
return nextSequence;
}
translator由用户在调用时自己实现,其实就是预留的一个扩展点,将覆盖事件预留出来。大部分实现都是将ByteBuffer复制到Event中,参考disruptor github官方例子。
最后声明新序列号发布完成,实际上就是设置了cursor,并且通知可能阻塞的消费者,这里已经发布完新的Event了,快来消费吧。
public void publish(long sequence)
{
cursor.set(sequence);
waitStrategy.signalAllWhenBlocking();
}
以上就是单生产者的分析,MultiProducerSequencer可以类似分析。
等待策略
等待策略实际上就是用来同步生产者和消费者的方法。SequenceBarrier只有一个实现ProcessingSequenceBarrier,中间就用到了WaitStrategy
BlockingWaitStrategy就是真正的加锁阻塞策略,采用的就是ReentrantLock以及Condition来控制阻塞与唤醒。
TimeoutBlockingWaitStrategy是BlockingWaitStr