继业务全面上云后,今年双11,阿里微服务技术栈全面迁移到以 Dubbo3 为代表的云上开源标准中间件体系。在业务上,基于 Dubbo3 首次实现了关键业务不停推、不降级的全面用户体验提升,从技术上,大幅提高研发与运维效率的同时地址推送等资源利用率在一些关键场景提升超 40%,基于三位一体的 Dubbo3 开源中间件体系打造了阿里在云上的单元化最佳实践和统一标准,同时将规模化实践经验与技术创新贡献开源社区,成为微服务开源技术与标准发展的核心源泉与推动力。
面对百万规模的集群实例,实现关键链路不停推、资源利用率大幅提升的关键即是 Dubbo3 中新引入的应用级服务发现。接下来我们着重讲解 Dubbo3 应用级服务发现的详细方案,同时通过饿了么案例来说明其升级迁移过程。
饿了么自去年 11月份启动 Dubbo3 相关的升级工作,在此之前饿了么的服务框架是用的 是 HSF2,从 HSF2 到 Dubbo3 的总体升级过程经历了半年,目前已基本完成,有近 2000 个应用、10w 个节点已经跑在 Dubbo3 之上。
通过这次分享,主要想给大家同步饿了么的 Dubbo3 升级经验,为什么升级 Dubbo3、升级的具体流程以及中间遇到的问题、尤其是饿了么重点关注的应用级服务发现模型,如何完成了地址发现模型的升级以及最终效果。当然在此之前,我们先对 Dubbo3 及应用级服务发现做一个全面的介绍。

关于 Dubbo3 的简介,期望通过这部分带大家了解 Dubbo3 到底是什么,与 2.7 架构的主要区别是什么,提供了哪些特性、可以解决哪些实际的问题等;其中也包括大家都关心兼容性、升级成本以及与 HSF2 的关系等。
我们定义 Dubbo3 是下一代的云原生服务框架,但 3.0 架构到底都包含哪些内容那?
我们先一起看看 3.0 的一些核心设计原则:首先,从架构层面 Dubbo 是面向云原生设计的,支持超大规模的微服务集群实践 - 百万实例级别,期望通过智能化流量调度系统提升系统稳定性与吞吐量;在策略层面,Dubbo3 的内核将是毫无保留开源的,它将成为国内公有云事实标准的服务框架,得到各大公有云厂商的支持,并通过灵活的 SPI 扩展机制支持不同部署场景的定制化需求;而在业务价值上,Dubbo3 将显著降低单机资源消耗,提升全链路资源利用率与服务治理效率。
这就是 3.0 设计过程中遵循的核心原则或目标,让我们从一个更高的层面认识了 Dubbo3。
具体到选型 Dubbo3 框架,大家一定关心 Dubbo3 提供了哪些新功能,如果是 Dubbo 老用户的话,还关心 Dubbo3 的兼容性,总结起来就是 Dubbo3 的迁移成本以及其能带来的核心价值。
左边这部分是关于 Dubbo3 兼容性及来源的详细描述。首先 Dubbo3 是从其自身 2.0 架构演进而来,因此它继承了 2.0 几乎所有的特性,且保持了对 Dubbo2 的完全兼容,因此,老用户几乎可以零成本迁移到 Dubbo3。Dubbo3 是在企业实践经验的基础上演进而来,我们知道 Dubbo 最初是由阿里开源并贡献给 Apache 社区,而这一次,阿里也已将 Dubbo3 定位为其下一代服务框架,因此,Dubbo3 融合了 HSF2 的几乎所有服务治理特性,并且已经开始在阿里巴巴全面取代 HSF2 框架,这一点我们在后面企业实践部分还会讲到。
右边是 Dubbo3 提供的核心特性列表,主要包括四部分。
- 全新服务发现模型。应用粒度服务发现,面向云原生设计,适配基础设施与异构系统;性能与集群伸缩性大幅提升
- 下一代 RPC 协议 Triple。基于 HTTP/2 的 Triple 协议,兼容 gRPC;网关穿透性强、多语言友好、支持 Reactive Stream
- 统一流量治理模型。面向云原生流量治理,SDK、Mesh、VM、Container 等统一治理规则;支持更丰富的流量治理场景
- Service Mesh。Sidecar Mesh 与 Proxyless Mesh,更多架构选择,降低迁移、落地成本
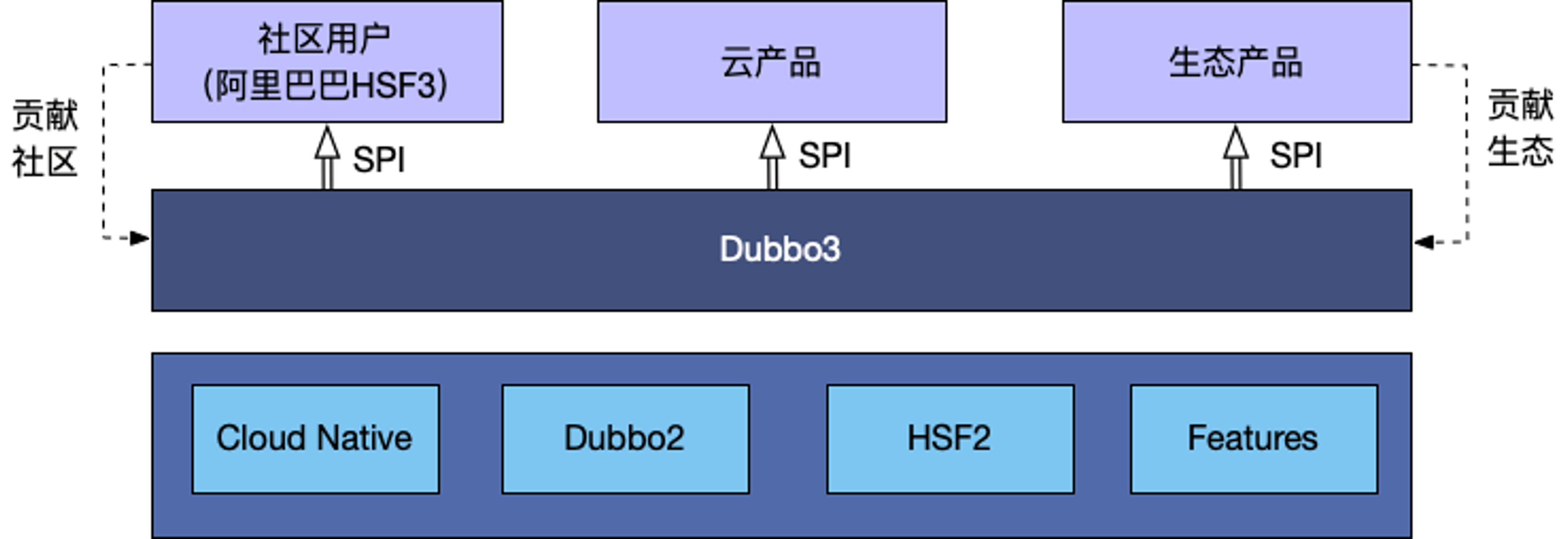
这张图更直观的反映了 Dubbo3 产生的背景以及与一些重要产品之间的关系。Dubbo3 诞生的基础是 Dubbo2、HSF2 两款产品,同时以云原生架构作为指导思想进行了大量重构,并规划一系列的功能特性;这些共同组成了 Dubbo3,也就是我们在 github 仓库及开源官网上看到的 Dubbo3;而在开源 Dubbo3 产品之上那,我们有基于 Dubbo3 的企业实践用户、生态产品以及公有云厂商的云产品。比如大家比较关心的 Dubbo3 典型用户阿里巴巴,阿里巴巴内部在此之前一直运行在自研 HSF2 框架,当然鉴于 HSF2 与 Dubbo2 的历史两者之间有很多相似之处,但实际却已经演进成两个不同的框架,在实现了 Dubbo3 的融合之后,阿里巴巴正在完全用开源 Dubbo3 取代 HSF2;在此,有些朋友可能会问,完全用开源的 Dubbo3 如何满足阿里自身特有的诉求?答案就是通过 SPI 扩展,所以在阿里内部现在还有一套 HSF3,而 HSF3 与以往的 HSF2 已经完全不同了,HSF3 完全就是基于标准 Dubbo3 的 SPI 扩展库,如注册中心扩展、路由组件扩展、监控组件扩展等,而其他配置组装、服务暴露、服务发现、地址解析等核心流程都是完全跑在 Dubbo3 之上;在这样的模式下,阿里巴巴的内部实践诉求都将完全体现在开源 Dubbo3 之上,包括内部开发人员也工作在开源 Dubbo3 之上。通过 SPI 扩展,同样也适用于公有云产品以及其他厂商的实践。
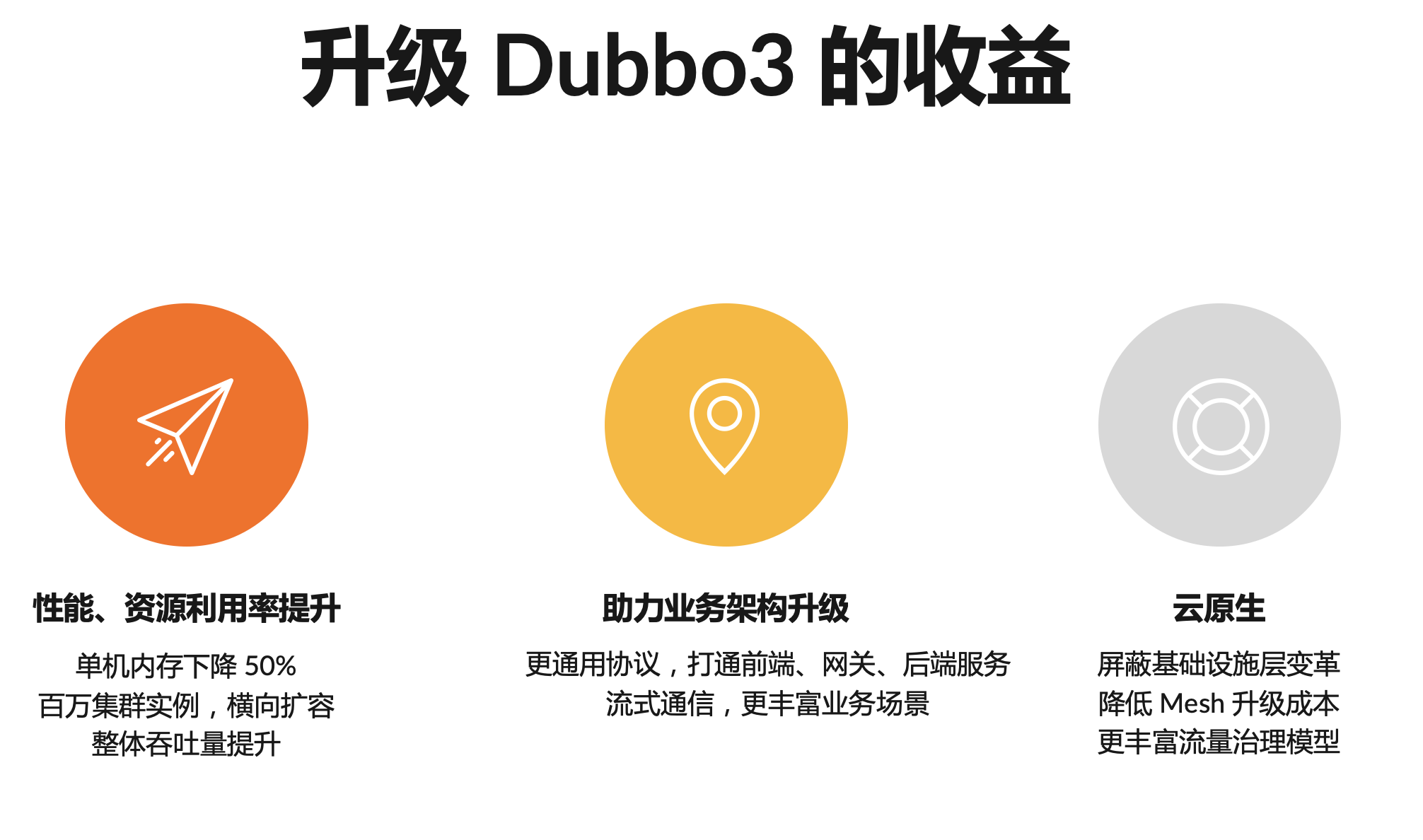
首先是性能、资源利用率的提升。升级 Dubbo3 的应用预期能实现单机内存 50% 的下降,对于越大规模的集群效果将越明显,Dubbo3 从架构上支持百万实例级别的集群横向扩展,同时依赖应用级服务发现、Triple协议等可以大大提供应用的服务治理效率和吞吐量。
其次,是 Dubbo3 让业务架构升级变得更容易、更合理。这个怎么理解那,其中值得重点关注的就是协议,在 2.x 版本中,web、移动端与后端的通信都要经过网关代理,完成协议转换、类型映射等工作,Triple 协议让这些变得更容易与自然;并通过流式通信模型满足更多的业务场景。
最后,得益于 Dubbo3 的完善云原生解决方案,Dubbo3 可以帮助业务屏蔽底层云原生基础设施细节,使得业务的迁移成本更低。
接下来我们着重讲解 Dubbo3 应用级服务发现的详细方案,也就是饿了么升级目标中最重要的一部分能力。
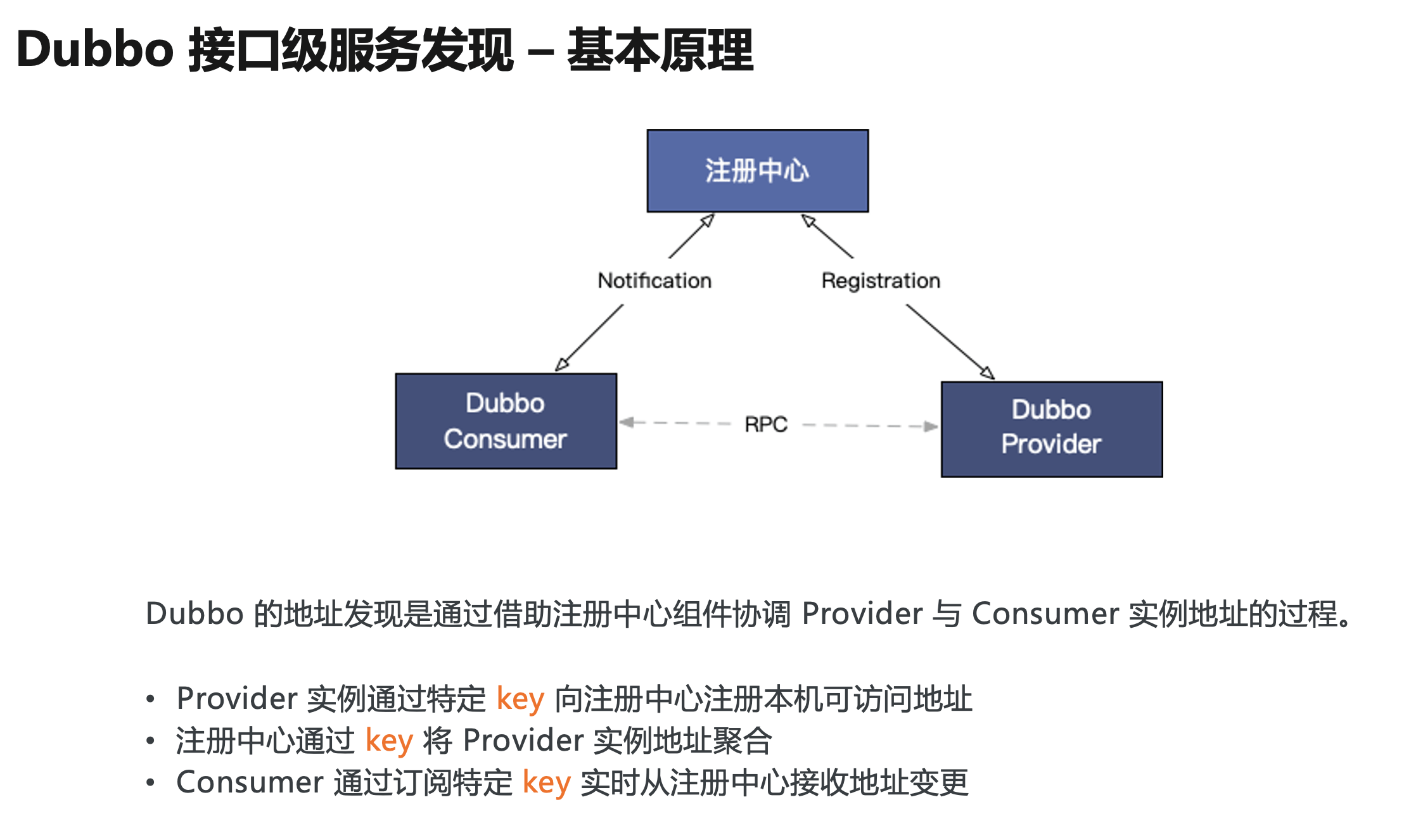
我们从 Dubbo 最经典的工作原理图说起,Dubbo 从设计之初就内置了服务地址发现的能力,Provider 注册地址到注册中心,Consumer 通过订阅实时获取注册中心的地址更新,在收到地址列表后,consumer 基于特定的负载均衡策略发起对 provider 的 RPC 调用。
在这个过程中
- 每个 Provider 通过特定的 key 向注册中心注册本机可访问地址;
- 注册中心通过这个 key 对 provider 实例地址进行聚合;
- Consumer 通过同样的 key 从注册中心订阅,以便及时收到聚合后的地址列表;
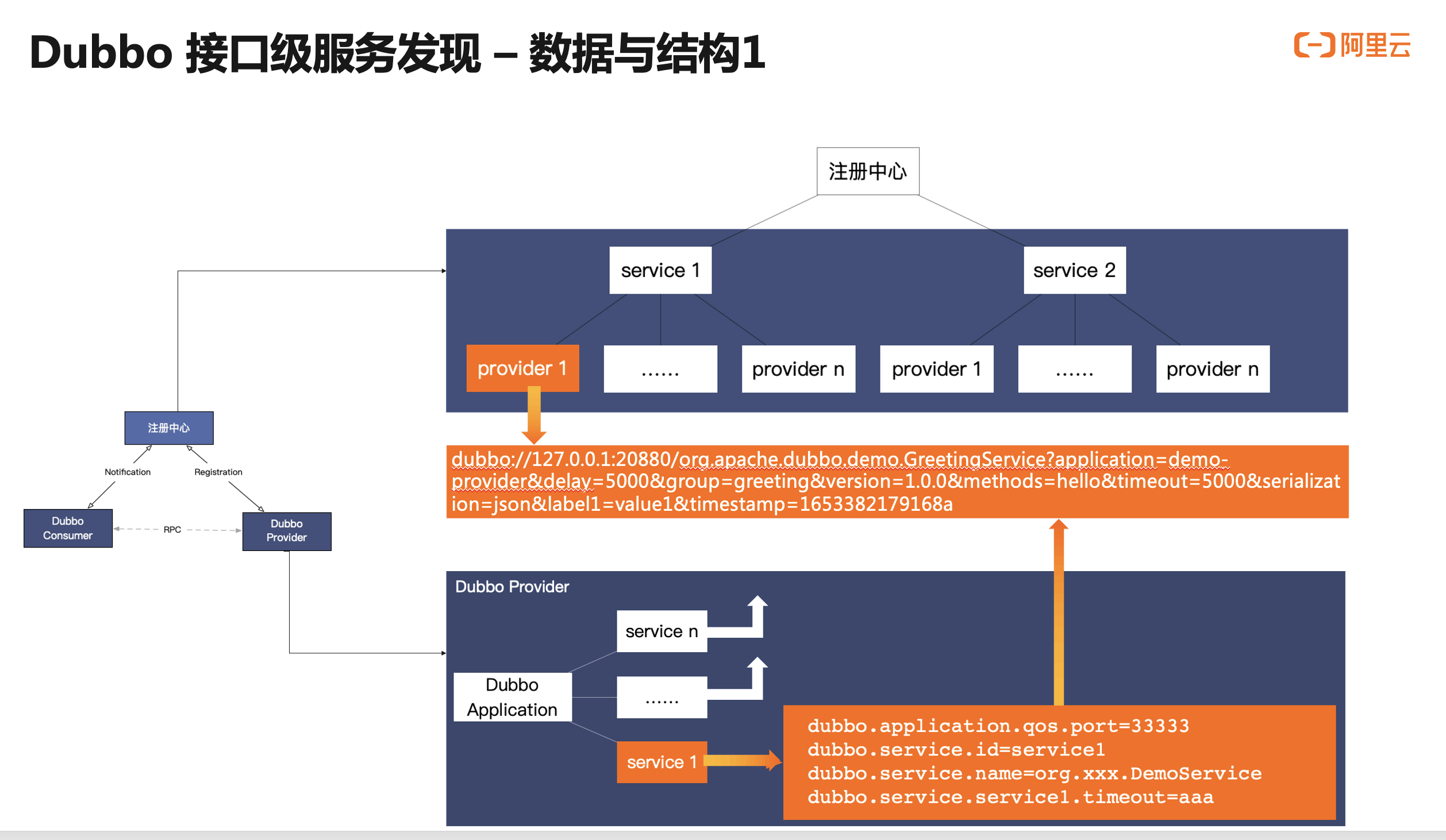
这里,我们对接口级地址发现的内部数据结构进行详细分析。
首先,看右下角 provider 实例内部的数据与行为。Provider 部署的应用中通常会有多个 Service,也就是 Dubbo2 中的服务,每个 service 都可能会有其独有的配置,我们所讲的 service 服务发布的过程,其实就是基于这个服务配置生成地址 URL 的过程,生成的地址数据如图所示;