- insert
���������Ҫһ���������ݿ���в��������¼�����Դ�����������������Ż���
insert into tb_test values(1,'tom');
insert into tb_test values(2,'cat');
insert into tb_test values(3,'jerry');
.....
- �Ż�����һ:
������������
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
- �Ż�������
�ֶ���������
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
- �Ż�������
����˳����룬����Ҫ����������롣
����������� : 8 1 9 21 88 2 4 15 89 5 7 3
����˳����� : 1 2 3 4 5 7 8 9 15 21 88 89
��������������
���һ������Ҫ�������������(����: ������ļ�¼)��ʹ��insert���������ܽϵͣ���ʱ����ʹ��MySQL���ݿ��ṩ��loadָ����в��롣�������£�
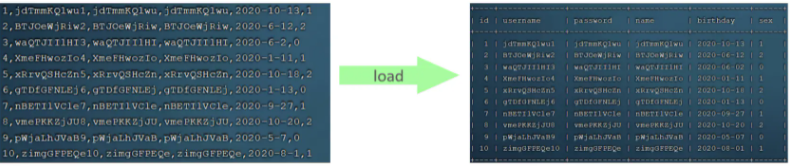
����ִ������ָ������ݽű��ļ��е����ݼ��ص����ṹ�У�
-- �ͻ������ӷ����ʱ�����ϲ��� -�Clocal-infile
mysql �C-local-infile -u root -p
-- ����ȫ�ֲ���local_infileΪ1�������ӱ��ؼ����ļ��������ݵĿ���
set global local_infile = 1;
-- ִ��loadָ����õ����ݣ����ص����ṹ��
load data local infile '/root/sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n' ;
����˳��������ܸ����������
ʵ����ʾ��
- �������ṹ
CREATE TABLE `tb_user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`username` VARCHAR(50) NOT NULL,
`password` VARCHAR(50) NOT NULL,
`name` VARCHAR(20) NOT NULL,
`birthday` DATE DEFAULT NULL,
`sex` CHAR(1) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ;
- ����
-- �ͻ������ӷ����ʱ�����ϲ��� -�Clocal-infile
mysql �C-local-infile -u root -p
-- ����ȫ�ֲ���local_infileΪ1�������ӱ��ؼ����ļ��������ݵĿ���
set global local_infile = 1;
- load��������
load data local infile '/root/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n' ;
mysql> load data local infile '/root/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n' ;
Query OK, 1000000 rows affected (15.47 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 0
mysql> select count(*) from tb_user;
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
1 row in set (0.31 sec)
���ǿ���������100w�ļ�¼��15.47s������ˣ����ܺܺá�
��loadʱ������˳��������ܸ����������
�����Ż�
����˳������������Ҫ�����������ġ�����������һ�¾����ԭ��Ȼ���ٷ���һ�������ָ������ơ�
- ������֯��ʽ
��InnoDB�洢�����У������ݶ��Ǹ�������˳����֯��ŵģ����ִ洢��ʽ�ı���Ϊ������֯��(index organized table IOT)��
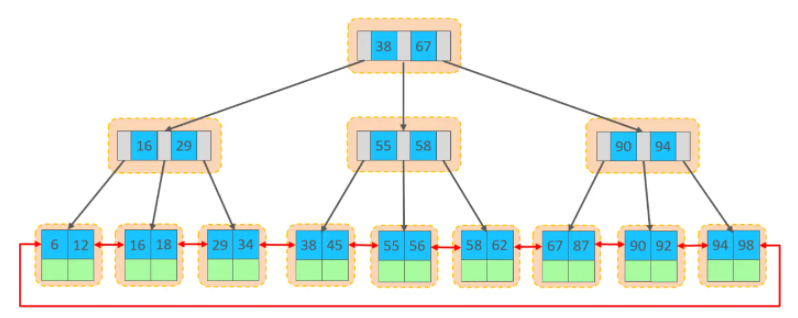
�����ݣ����Ǵ洢�ھۼ�������Ҷ�ӽڵ��ϵġ�������֮ǰҲ�����InnoDB�����ṹͼ��
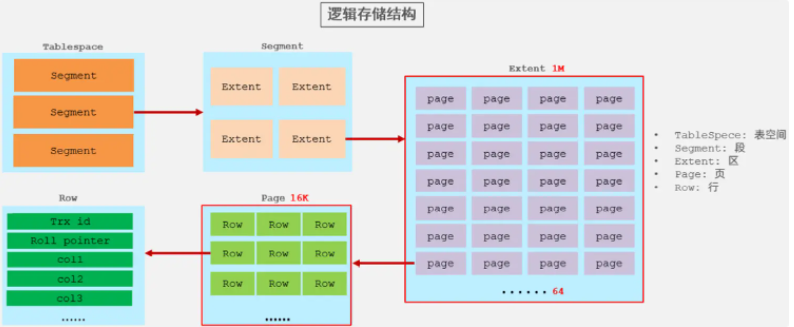
��InnoDB�����У��������Ǽ�¼�����ṹ page ҳ�еģ���ÿһ��ҳ�Ĵ�С�ǹ̶��ģ�Ĭ��16K����Ҳ����ζ�ţ� һ��ҳ�����洢����Ҳ�����ģ���������������row�ڸ�ҳ�洢��С������洢����һ��ҳ�У�ҳ��ҳ֮���ͨ��ָ�����ӡ�
- ҳ����
ҳ����Ϊ�գ�Ҳ�������һ�룬Ҳ�������100%��ÿ��ҳ������2-N������(���һ�����ݹ��������)�������������С�
-
����˳�����Ч��
-
�Ӵ���������ҳ�� ����˳�����
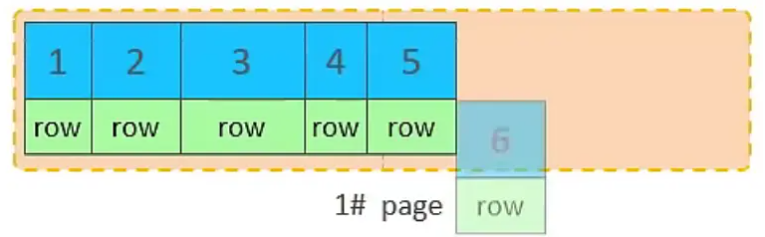
-
��һ��ҳû��������������һҳ����
-
����һ��Ҳд��֮����д��ڶ���ҳ��ҳ��ҳ֮���ͨ��ָ������
-

- ���ڶ�ҳд���ˣ���������ҳд��

-
�������������
- ����1#,2#ҳ���Ѿ�д���ˣ��������ͼ��ʾ������

-
��ʱ�ٲ���idΪ50�ļ�¼�������������ᷢ��ʲô����
���ٴο���һ��ҳ��д���µ�ҳ����
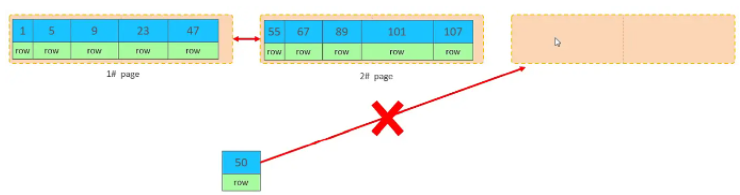
���ᡣ��Ϊ�������ṹ��Ҷ�ӽڵ�����˳��ġ�����˳��Ӧ�ô洢��47֮��
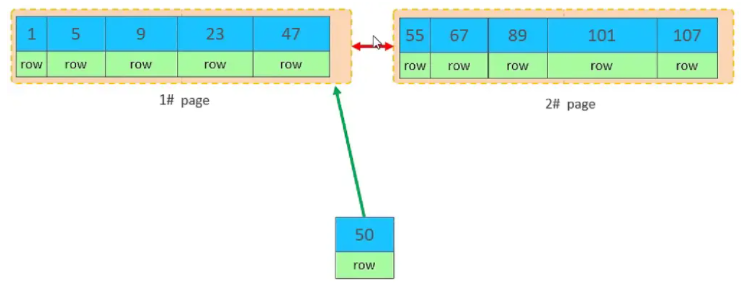
����47���ڵ�1#ҳ���Ѿ�д���ˣ��洢����50��Ӧ�������ˡ� ��ô��ʱ�Ὺ��һ���µ�ҳ 3#��

���Dz�����ֱ�ӽ�50����3#ҳ�����ǻὫ1#ҳ��һ������ݣ��ƶ���3#ҳ��Ȼ����3#ҳ������50��
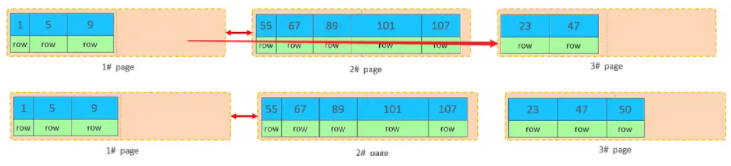
�ƶ����ݣ�������idΪ50������֮����ô��ʱ��������ҳ֮�������˳����������ġ� 1#����һ�� ҳ��Ӧ����3#�� 3#����һ��ҳ��2#�� ���ԣ���ʱ����Ҫ������������ָ�롣

��������������֮Ϊ "ҳ����"���DZȽϺķ����ܵIJ�����
-
ҳ�ϲ�
- Ŀǰ�����������ݵ������ṹ(Ҷ�ӽڵ�)���£�

-
�����Ƕ��������ݽ���ɾ��ʱ�������Ч������:
-
��ɾ��һ�м�¼ʱ��ʵ���ϼ�¼��û�б�����ɾ����ֻ�Ǽ�¼����ǣ�flaged��Ϊɾ���������Ŀռ���������������¼����ʹ�á�

- �����Ǽ���ɾ��2#�����ݼ�¼

- ��ҳ��ɾ���ļ�¼�ﵽ
MERGE_THRESHOLD��Ĭ��Ϊҳ��50%����InnoDB�ῪʼѰ�������ҳ��ǰ ������Ƿ���Խ�����ҳ�ϲ����Ż��ռ�ʹ�á�
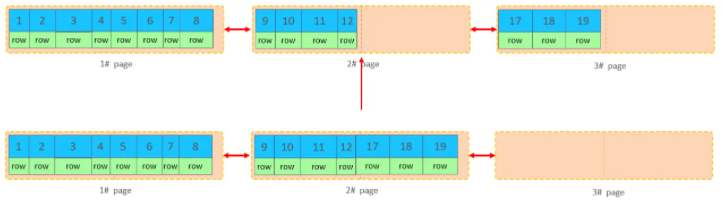
- ɾ�����ݣ�����ҳ�ϲ�֮���ٴβ����µ�����21����ֱ�Ӳ���3#ҳ

- ��������������ĺϲ�ҳ��������ͳ�֮Ϊ "ҳ�ϲ�"��
֪ʶС��ʿ��
MERGE_THRESHOLD���ϲ�ҳ����ֵ�������Լ����ã��ڴ��������ߴ�������ʱָ����