ժҪ��Apache ShardingSphere ��һ��ֲ�ʽ�����ݿ���̬ϵͳ�������������Ʒ��ShardingSphere-Proxy��ShardingSphere-JDBC��
���ķ����Ի�Ϊ��������������һƪ��ShardingSphere-jdbc ʵս��Ҳ�������������ߣ��¸�javaʵս���� ��
1 ShardingSphere ��̬
Apache ShardingSphere ��һ��ֲ�ʽ�����ݿ���̬ϵͳ�������������Ʒ��
- ShardingSphere-Proxy
- ShardingSphere-JDBC
��һ��ShardingSphere-Proxy
ShardingSphere-Proxy ����λΪ���������ݿ�����ˣ��ṩ��װ�����ݿ������Э��ķ���˰汾��������ɶ��칹���Ե�֧�֡�
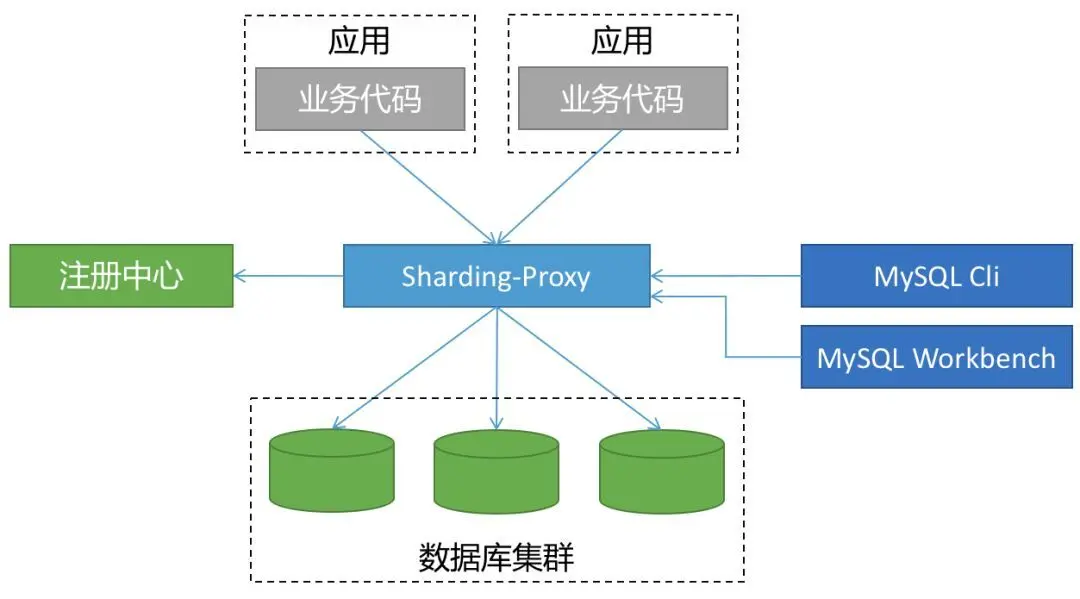
���������Ӧ�ó��������ݿ�䣬ÿ��������Ҫ��һ��ת�����������ڶ����ʱ�ӡ�
���ַ�ʽ����Ӧ�÷dz��Ѻã�Ӧ�û�����Ķ����������أ�����ͨ�����ӹ����������������ġ�
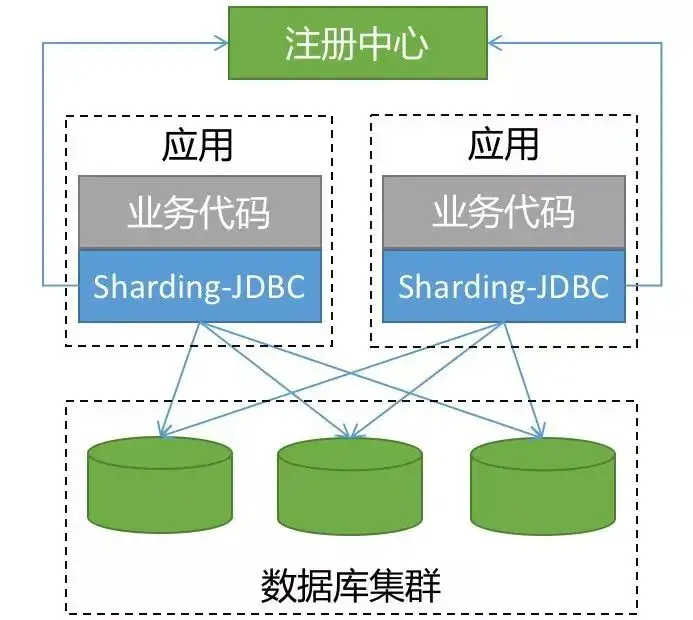
������ShardingSphere-JDBC
ShardingSphere-JDBC �� ShardingSphere �ĵ�һ����Ʒ��Ҳ�� ShardingSphere ��ǰ���� ���Ǿ������֮Ϊ��sharding-jdbc ��
����λΪ������ Java ��ܣ��� Java �� JDBC ���ṩ�Ķ��������ʹ�ÿͻ���ֱ�����ݿ⣬�� jar ����ʽ�ṩ����������ⲿ���������������Ϊ��ǿ��� JDBC ��������ȫ���� JDBC ���� ORM ��ܡ�
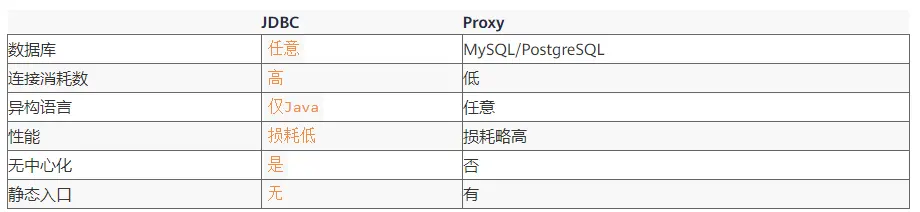
�������� Proxy �� JDBC ����ģʽѡ��ʱ�����Բο��±����գ�
Խ��Խ��Ĺ�˾������������ʹ���� sharding-jdbc ������ĵ�ԭ����ǣ�����ԭ��������ʵ�֣�������ά����
2 ����ԭ��
�ں�˿����У�JDBC �����������IJ��������� ORM ����� Mybatis ���� Hibernate ������� spring-jpa �����ǵĵײ�ʵ���� JDBC ��ģ�͡�
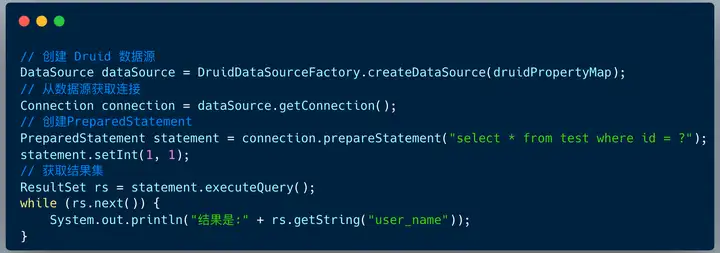
sharding-jdbc �ı����Ͼ���ʵ�� JDBC �ĺ��Ľӿڡ�
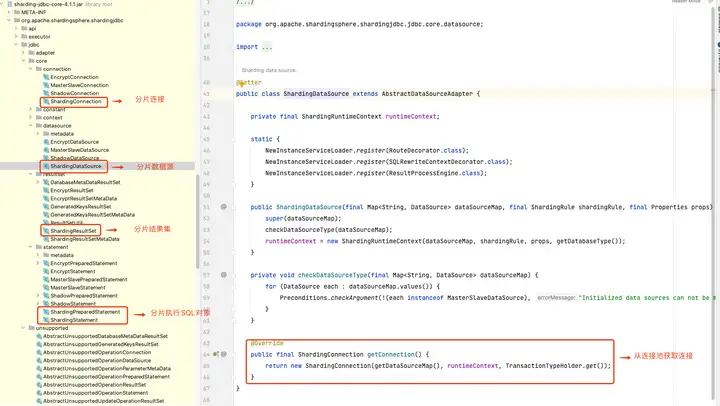

��Ȼ���������� sharding-jdbc �ı��ʣ���������ʵ���������зdz����ϸ�ڣ���ͼչʾ�� Prxoy �� JDBC ����ģʽ�ĺ������̡�
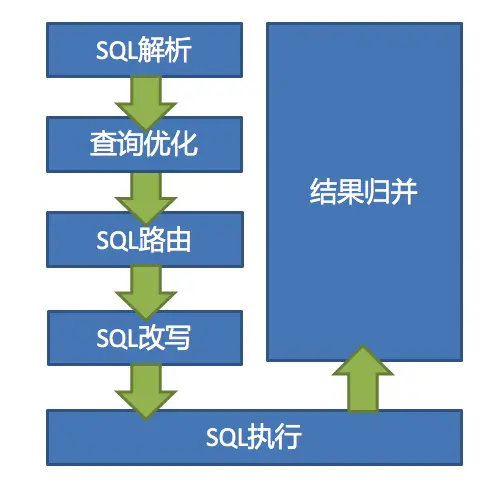
1.SQL ����
��Ϊ�ʷ�������������� ��ͨ���ʷ��������� SQL ���Ϊһ���������ٷֵĵ��ʡ���ʹ����������� SQL �������⣬���������������������ġ�
���������İ�������ѡ��������������ۺϺ�������ҳ��Ϣ����ѯ�����Լ�������Ҫ�ĵ�ռλ���ı�ǡ�
2.ִ�����Ż�
�ϲ����Ż���Ƭ�������� OR �ȡ�
3.SQL ·��
���ݽ���������ƥ���û����õķ�Ƭ���ԣ�������·��·����Ŀǰ֧�ַ�Ƭ·�ɺ㲥·�ɡ�
4.SQL ��д
�� SQL ��дΪ����ʵ���ݿ��п�����ȷִ�е���䡣SQL ��д��Ϊ��ȷ�Ը�д���Ż���д��
5.SQL ִ��
ͨ�����߳�ִ�����첽ִ�С�
6.����鲢
�����ִ�н�����鲢�Ա���ͨ��ͳһ�� JDBC �ӿ����������鲢������ʽ�鲢���ڴ�鲢��ʹ��װ����ģʽ���ӹ鲢�⼸�ַ�ʽ��
���ĵ��ص�����ʵս���棬 sharding-jdbc ��ʵ��ԭ��ϸ�����ǻ��ں���������һһ����ҳ��� ��
3 ʵս����
��������Ϊ�人һ�� O2O ��˾�������������ֿ�ֱ��ܹ���� ������ҵ�û�����һ���ɹ����� �� ���������¼�¼��
- ����������t_ent_order ��������¼
- ���������t_ent_order_detail ��������¼
- ������ϸ��t_ent_order_item��N ����¼
�������ݲ��������µķֿ�ֱ����ԣ�
- �������������� ent_id (��ҵ�û����) �ֿ� ���������������һ�£�
- ������ϸ������ ent_id (��ҵ�û����) �ֿ⣬ͬʱҲҪ���� ent_id (��ҵ���) �ֱ���
���ȴ��� 4 ���⣬�ֱ��ǣ�ds_0��ds_1��ds_2��ds_3 ��
���ĸ��ֿ⣬ÿ���ֿⶼ���� ���������� �� ��������� ��������ϸ�� ��������Ϊ��ϸ����Ҫ�ֱ������������ű���
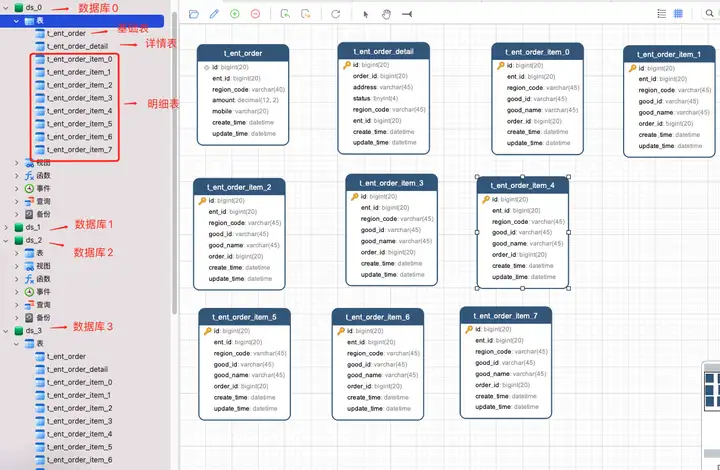
Ȼ�� springboot ��Ŀ���������� ��
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.1.1</version> </dependency>
�����ļ����������£�
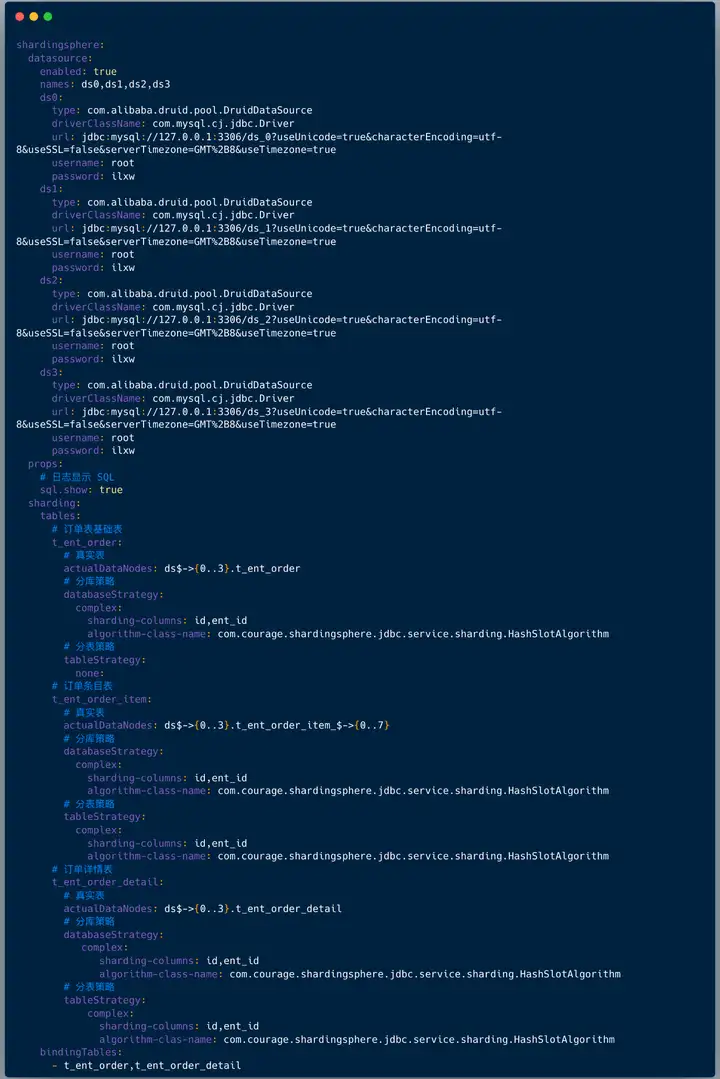
- ��������Դ��������������Դ�ǣ� ds0��ds1��ds2��ds3 ��
- ���ô�ӡ��־��Ҳ���ǣ�sql.show ���ڲ��Ի�������� �����ڵ��ԣ�
- ������Щ����Ҫ�ֿ�ֱ� ���� shardingsphere.datasource.sharding.tables �ڵ��������ã�

��ͼ�����ǿ������÷�Ƭ��������������㣺
1����ʵ�ڵ�
�������ǵ�Ӧ�����������Dz�ѯ�������ǣ�t_ent_order_item ��
���������ݿ��е���ʵ��̬�ǣ�t_ent_order_item_0 �� t_ent_order_item_7��
��ʵ���ݽڵ���ָ���ݷ�Ƭ����С��Ԫ��������Դ���ƺ����ݱ���ɡ�
������ϸ������ʵ�ڵ��ǣ�ds$->{0..3}.t_ent_order_item_$->{0..7} ��
2���ֿ�ֱ��㷨
���÷ֿ���Ժͷֱ����� , ÿ�ֲ��Զ���Ҫ������Ƭ�ֶ��� sharding-columns ������Ƭ�㷨��
4 ���� & �Զ��帴�Ϸ�Ƭ�㷨
��Ƭ�㷨�Ͱ��↑Դ�����ݿ��м�� cobar ·���㷨�dz����Ƶġ�
����������Ҫ��������ƽ����ֵ�4���ֿ� shard0 ��shard1 ��shard2 ��shard3 ��
���Ƚ� [0-1023] ƽ����Ϊ4�����Σ�[0-255]��[256-511]��[512-767]��[768-1023]��Ȼ����ַ��������Ӵ������û��Զ��壩�� hash�� hash ����� 1024 ȡģ�����յó��Ľ�� slot �����ĸ����Σ���·�ɵ��ĸ��ֿ⡣
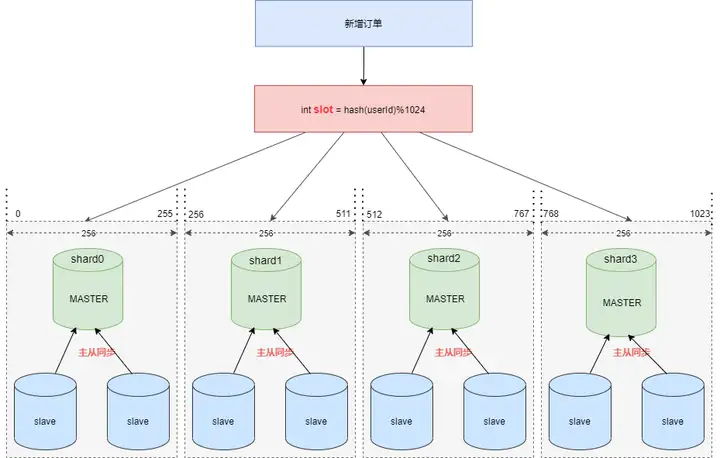
��������Ƭ�㷨�ܼ���������Ҫ���ն��� ID ��ѯ������Ϣʱ��Ȼ��Ҫ·���ĸ���Ƭ��Ч�ʲ��ߣ���ô����Ż��� ��
���ǣ����� & �Զ��帴�Ϸ�Ƭ�㷨��
������ָ�ڶ��� ID ��Я����ҵ�û������Ϣ�����ǿ����ڴ������� order_id ʱʹ��ѩ���㷨��Ȼ�� slot ��ֵ������ 10λ�������� ID �
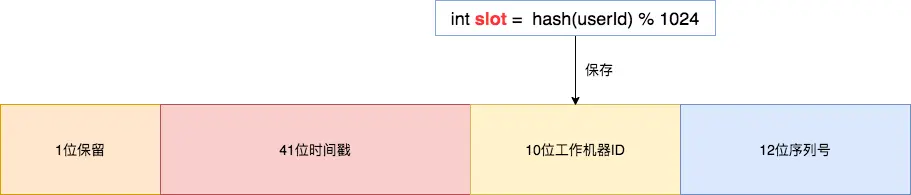
ͨ������ order_id ���Է���� slot , �Ϳ��Զ�λ���û��Ķ������ݴ洢���ĸ���Ƭ�
Integer getWorkerId(Long orderId) { Long workerId = (orderId >> 12) & 0x03ff; return workerId.intValue(); }
��ͼչʾ�˶��� ID ʹ��ѩ���㷨�����ɹ��̣����ɵı�Ż�Я����ҵ�û� ID ��Ϣ��

����˷ֲ�ʽ ID ���⣬��������һ�����⣺sharding-jdbc �ɷ�֧�ְ��ն��� ID ����ҵ�û� ID