���������� ��ѧ�ȿ�Ұ�ܹ�ʦ
������
����������
���������������ͬһ������������������������һ��Ϊд��������ʱ����������֮��ʹ������������ԡ����������������������ͣ�
| ���� | ����ʾ�� | ˵�� |
|---|---|---|
| д��� | a = 1;b = a; | дһ������֮���ٶ����λ�á� |
| д��д | a = 1;a = 2; | дһ������֮����д��������� |
| ����д | a = b;b = 1; | ��һ������֮����д��������� |
�������������ֻҪ����������������ִ��˳�����ִ�н�����ᱻ�ı䡣
ǰ���ᵽ�����������ʹ��������ܻ�Բ����������������ʹ�������������ʱ�����������������ԣ��������ʹ���������ı��������������ϵ������������ִ��˳��
ע�⣬������˵�����������Խ���Ե�����������ִ�е�ָ�����к͵����߳���ִ�еIJ�������ͬ������֮��Ͳ�ͬ�߳�֮������������Բ����������ʹ��������ǡ�
as-if-serial����
as-if-serial�������˼ָ��������ô�����������ʹ�����Ϊ����߲��жȣ��������̣߳������ִ�н�����ܱ��ı䡣��������runtime �ʹ���������������as-if-serial���塣
Ϊ������as-if-serial���壬�������ʹ���������Դ�������������ϵ�IJ�������������Ϊ�����������ı�ִ�н�������ǣ��������֮�䲻��������������ϵ����Щ�������ܱ��������ʹ�����������Ϊ�˾���˵�����뿴�������Բ����Ĵ���ʾ����
COPYdouble pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
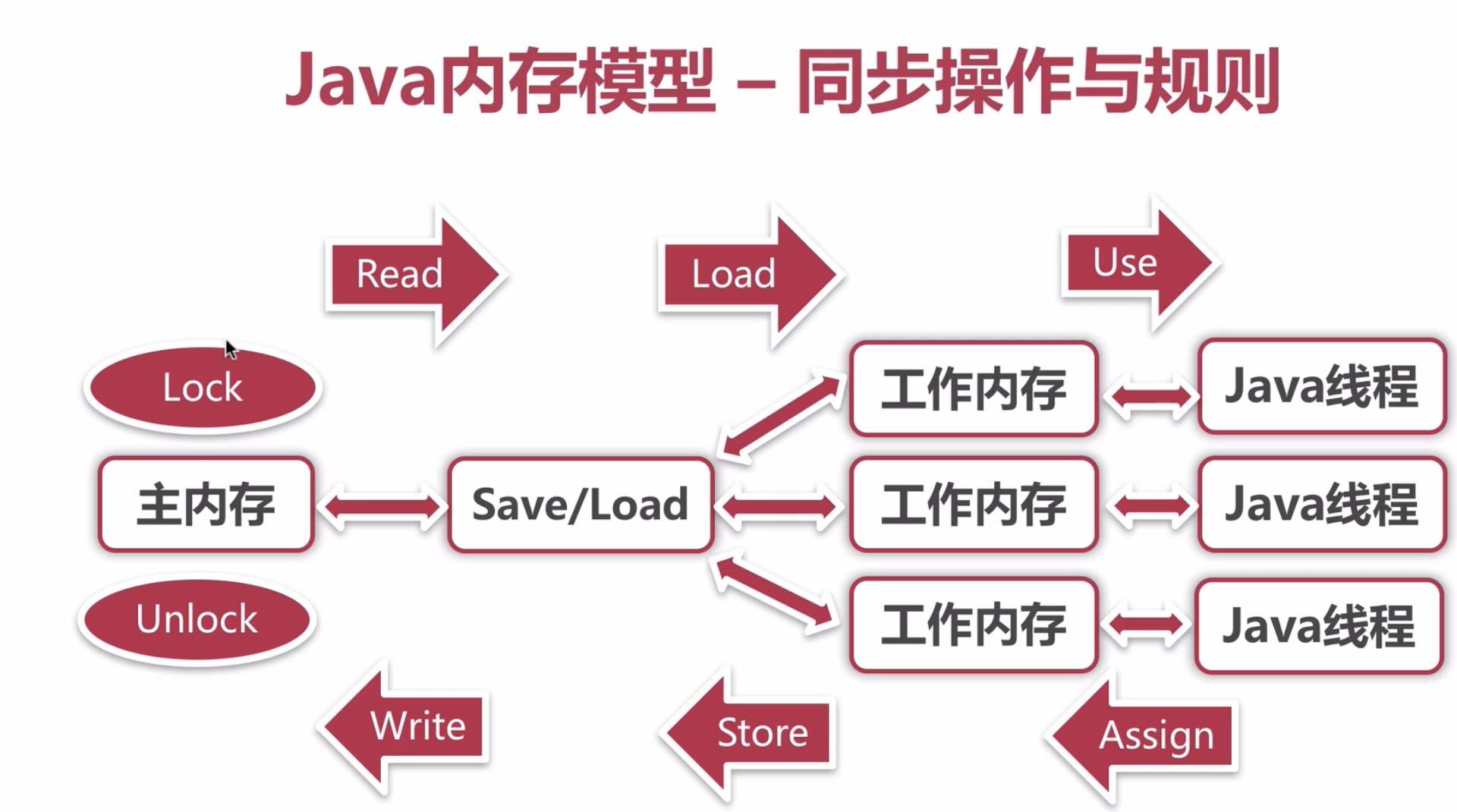
������������������������ϵ����ͼ��ʾ��
����ͼ��ʾ��A��C֮���������������ϵ��ͬʱB��C֮��Ҳ��������������ϵ�����������ִ�е�ָ�������У�C���ܱ�������A��B��ǰ�棨C�ŵ�A��B��ǰ�棬����Ľ�����ᱻ�ı䣩����A��B֮��û������������ϵ���������ʹ���������������A��B֮���ִ��˳����ͼ�Ǹó��������ִ��˳��
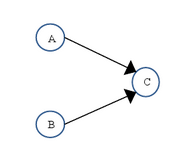
as-if-serial����ѵ��̳߳���������������as-if-serial����ı�������runtime �ʹ�������ͬΪ��д���̳߳���ij���Ա������һ���þ������̳߳����ǰ������˳����ִ�еġ�as-if-serial����ʹ���̳߳���Ա���赣���������������ǣ�Ҳ���赣���ڴ�ɼ������⡣
����˳�����
����happens- before�ij���˳������������Բ�������ʾ�������������happens- before��ϵ��
COPYA happens- before B;
B happens- before C;
A happens- before C;
����ĵ�3��happens- before��ϵ���Ǹ���happens- before�Ĵ������Ƶ������ġ�
����A happens- before B����ʵ��ִ��ʱBȴ��������A֮ǰִ�У����������������ִ��˳�����A happens- before B��JMM����Ҫ��Aһ��Ҫ��B֮ǰִ�С�JMM����Ҫ��ǰһ��������ִ�еĽ�����Ժ�һ�������ɼ�����ǰһ��������˳�����ڵڶ�������֮ǰ���������A��ִ�н������Ҫ�Բ���B�ɼ����������������A�Ͳ���B���ִ�н���������A�Ͳ���B��happens- before˳��ִ�еĽ��һ�¡�����������£�JMM����Ϊ�����������Ƿ���not illegal����JMM��������������
�ڼ�����У�����������Ӳ��������һ����ͬ��Ŀ�꣺�ڲ��ı����ִ�н����ǰ���£������ܵĿ������жȡ��������ʹ����������һĿ�꣬��happens- before�Ķ������ǿ��Կ�����JMMͬ�������һĿ�ꡣ
������Զ��̵߳�Ӱ��
�������������������������Ƿ��ı���̳߳����ִ�н�����뿴�����ʾ�����룺
COPYclass ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
public void reader() {
if (flag) { //3
int i = a * a; //4
����
}
}
}
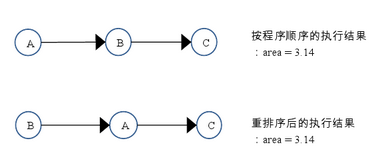
flag�����Ǹ���ǣ�������ʶ����a�Ƿ��ѱ�д�롣��������������߳�A��B��A����ִ��writer()���������B�߳̽���ִ��reader()�������߳�B��ִ�в���4ʱ���ܷ��߳�A�ڲ���1�Թ�������a��д�룿
���ǣ���һ���ܿ�����
���ڲ���1�Ͳ���2û������������ϵ���������ʹ��������Զ�����������������ͬ��������3�Ͳ���4û������������ϵ���������ʹ�����Ҳ���Զ���������������������������������������1�Ͳ���2������ʱ�����ܻ����ʲôЧ�����뿴����ij���ִ��ʱ��ͼ��
����ͼ��ʾ������1�Ͳ���2������������ִ��ʱ���߳�A����д��DZ���flag������߳�B��������������������ж�Ϊ�棬�߳�B����ȡ����a����ʱ������a������û�б��߳�Aд�룬��������̳߳�������屻�������ƻ��ˣ�
ע������ͳһ�ú�ɫ������߱�ʾ����Ķ�����������ɫ������߱�ʾ��ȷ�Ķ�������
�����������ǿ�����������3�Ͳ���4������ʱ�����ʲôЧ�������������������˳��˵�����������ԣ���
�����Dz���3�Ͳ���4����������ִ��ʱ��ͼ��
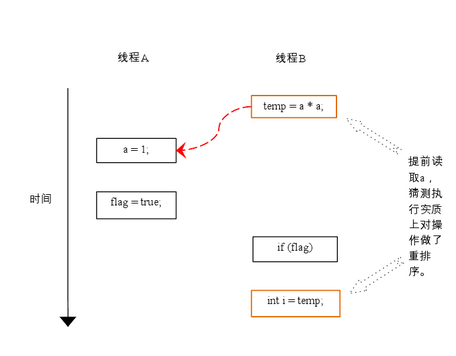
�ڳ����У�����3�Ͳ���4���ڿ���������ϵ���������д��ڿ���������ʱ����Ӱ��ָ������ִ�еIJ��жȡ�Ϊ�ˣ��������ʹ���������ò²⣨Speculation��ִ�����˷���������ԶԲ��жȵ�Ӱ�졣�Դ������IJ²�ִ��Ϊ����ִ���߳�B�Ĵ�����������ǰ��ȡ������a*a��Ȼ��Ѽ�������ʱ���浽һ����Ϊ�����壨reorder buffer ROB����Ӳ�������С�������������3�������ж�Ϊ��ʱ���ͰѸü�����д�����i�С�
��ͼ�����ǿ��Կ������²�ִ��ʵ���϶Բ���3��4�����������������������ƻ��˶��̳߳�������壡
�ڵ��̳߳����У��Դ��ڿ��������IJ�����������ı�ִ�н������Ҳ��as-if-serial���������Դ��ڿ��������IJ������������ԭ�����ڶ��̳߳����У��Դ��ڿ��������IJ����������ܻ�ı�����ִ�н����
˳��һ����
���ݾ�����˳��һ���Ա�֤
������δ��ȷͬ��ʱ���ͻ�������ݾ�����java�ڴ�ģ�淶�����ݾ����Ķ������£�
- ��һ���߳���дһ��������
- ����һ���̶߳�ͬһ��������
- ����д�Ͷ�û��ͨ��ͬ��������
�������а������ݾ���ʱ�������ִ����������Υ��ֱ���Ľ�������һ�����̳߳�������ȷͬ�������������һ��û�����ݾ����ij���
JMM����ȷͬ���Ķ��̳߳�����ڴ�һ�����������±�֤��
�����������ȷͬ���ģ������ִ�н�����˳��һ���ԣ�sequentially consistent���C�������ִ�н����ó�����˳��һ�����ڴ�ģ���е�ִ�н����ͬ���������ǽ��ῴ��������ڳ���Ա��˵��һ����ǿ�ı�֤���������ͬ����ָ�����ϵ�ͬ���������Գ���ͬ��ԭ�lock��volatile��final������ȷʹ�á�
˳��һ�����ڴ�ģ��
˳��һ�����ڴ�ģ����һ�����������ѧ�����뻯�˵����۲ο�ģ�ͣ���Ϊ����Ա�ṩ�˼�ǿ���ڴ�ɼ��Ա�֤��˳��һ�����ڴ�ģ�����������ԣ�