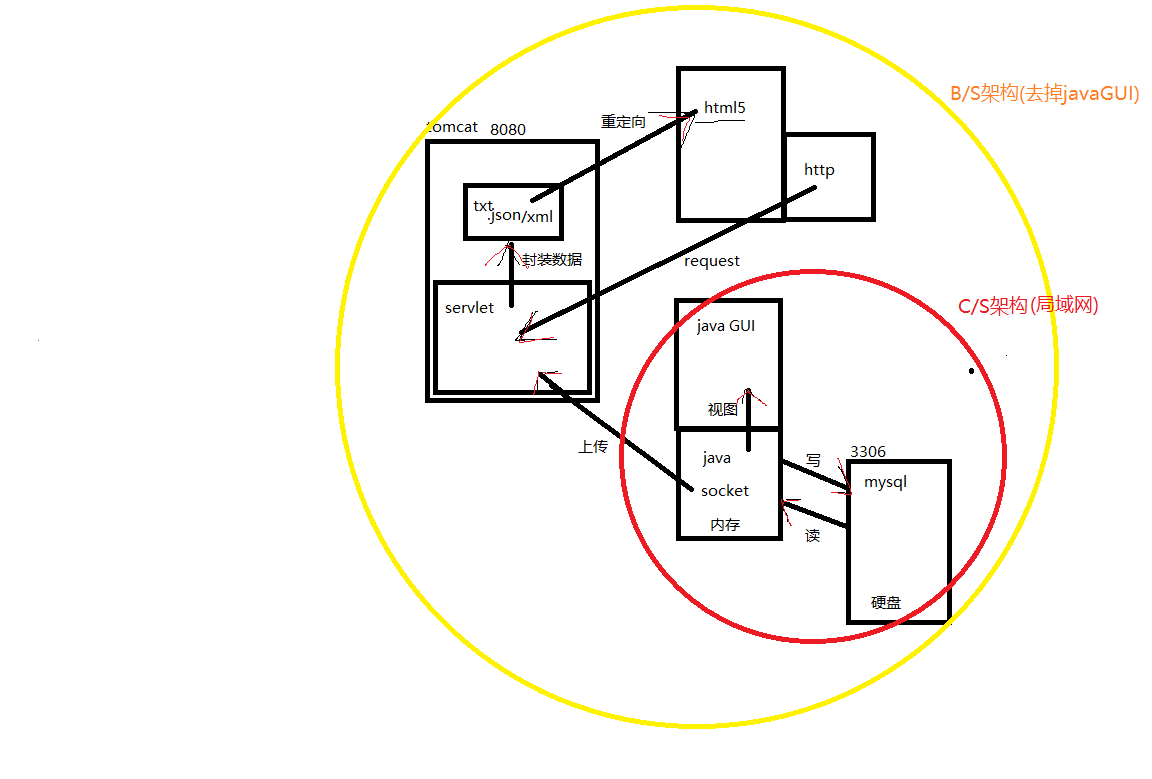
javaweb模型
声明:本文中的数据和资源两个词完全等价,本文中有大量逻辑包含关系,经常出现的是大概念和小概念偷换,望见谅。
动态和静态:这是一个不新鲜的问题。我准备用新鲜的例子去解释。
我有一个需求,我想要得到圆周率小数点后一亿亿亿亿位的数据(忽略除运算条件外的其他条件),因为我的计算机运算能力不足所以我需要一台算力更优秀的电脑去运算并将结果获取过来。但是我们知道随着运算的深入这个结果是有可能发生变化的,其变化不取决于我的电脑,而取决于提供数据的电脑,像这种数据的提供取决于在“非我电脑”上的现象,我们称之为动态。再比如你的账号数据不能在你自己的电脑上修改,这是因为数据存储于其他电脑的数据库。静态反之。
因为资源在质与量方面的差异,以及电脑用户对资源质量的追求,通过网络获取动态资源的必要性和紧迫性与日俱增。电脑接入网络(以太网,广域网,局域网.....)变为连接设备,有开放的连接设备的称为服务器(服务器是个相对概念),请求方为客户端,响应方称之为服务器。
动态数据传输通道――动态数据传输需要通道:
1、网络:现在的网络质量都不算太差,太差的网络会导致各种问题,比如丢包,重连等,这一层由运营商代理,该通道不能存储数据,除非提供中介服务器。
2、内存:现在的内存传输效率也不低,但不能存储数据,只能运算数据。
3、硬盘:分为固态硬盘和机械硬盘,随着技术的提高,固态硬盘容量越来越大,数据读写效率也有极大提高,质量也越来越好,最重要是缓冲区得到极大拓展,但仍然是CPU效率瓶颈。
动态数据传输通道路线:
请求:客户端硬盘(读取数据)→客户端内存(封装需求)→域网络(请求)→服务端内存(解封需求)→服务端硬盘(写入数据)
响应:服务器硬盘(读取数据)→服务器内存(封装服务)→域网络(响应)→客户端内存(解封服务)→客户端硬盘(写入数据)
这个是一个闭环传输通路,其实只要能够构成一个闭环传输通路,任何数据都能够成为动态数据。
有以下至少三种选择:
域网络(请求)→域网络(响应)→域网络(请求)这就是一个最简单的动态数据通路,只不过这个数据只在域网络中传输,也有这种情况的使用比如DOS里的ping命令用来验证网络可达性,也就是所谓的延迟。
客户端内存→......→服务器内存→......客户端内存 这是一个持续型动态数据通路,这个数据在内存中运行,比如说远程连接,在线视频通话等。这也就是为什么远程吞吐量极大的原因,本身远程获取来的数据没有条件也跟本不可能存储到硬盘里。
客户端硬盘→......→服务器硬盘→......客户端硬盘 这是一个应用最广的动态数据通路,客户端和服务器都有硬盘资源,客户端可以(不)上传任意的量的数据,服务器可以(不)响应任意量的数据,客户端可以(不)下载任意量的数据,由此最大程度的控制了动态资源的任意性。
其他选择:
客户端内存→域网络→客户端内存,命令服务系统,dos窗口的小程序等。
客户端硬盘→域网络→客户端硬盘,文件服务系统,对单硬盘文件的读写操作,两个硬盘文件的拷贝等。
数据资源的任意性:
①、客户端有可能向服务器上传不可预计质量的数据(比如超量数据、恶性数据、非请求规范数据):比如明码、木马脚本等
②、服务器有可能向客户端响应不可预计质量的数据(比如超量数据、恶性数据、非响应规范数据):比如捆绑软件、木马脚本等。
③、客户端有可能向数据库存储不可预计的质量数据(比如超量数据、恶性数据、非存储规范数据):比如爬虫、磁力链、其他系统软件等。
动态数据传输通道的实现:
我们只说最长的通道,因为本文讲的就是最长通道实现的方式――javaweb。
域闭环传输实现。接根网线,可以是通往各种域的网线。我们这里选择了通往本机的网线,IP地址是127.0.0.1或localhost,tomcat软件服务器端口8080,数据流可以通过。
内存闭环传输实现。开启谷歌浏览器。编写java文件,通过数据流向页面输出数据。
硬盘闭环传输实现。我们不上传数据(上传0量数据),通过设置请求服务的URL,通过数据流请求数据,java获取请求数据,java连接数据库,获取定量数据,通过数据流响应数据,我们不下载数据(下载0量数据)。
综上分析,tomcat和浏览器共同集成了对于数据流的域闭环传输和内存闭环传输以及客户端侧的硬盘闭环传输。这样的话服务器只需要专注于自己的硬盘闭环传输问题就可以了。
服务器端硬盘闭环传输问题:
域请求(响应)处理,这个处理都是在HTjava中执行的,一般意义上的大数据吞吐量没有问题。
内存――硬盘通路处理(javaweb的核心),这个问题说简单点就是内存到硬盘的传输效率问题,也叫做数据持久化问题。
java的代码是在内存里的,比如Array、LIst、Map这就意味着在这些容器中存储的数据都是临时的,重启java程序之后数据进入新的生命周期。这种程序也有,比如计算器――本质上是只使用程序的计算代码,属于基本功能。
但是要对存储的数据进行持久化,则需要使用存储于硬盘的文件,比如txt,properties,json、xml、sql等,java的io类等提供了对这些文件的操作接口。
一种文件类型是否适合存储数据要看多方面表现的情况,txt存储数数据没有统一规范,所以不适用,properties、json、xml存储数据有统一规范但是由于缺乏构建庞大复杂数据和数据处理的算法特点,所以不适用。
sql凭借优秀的规范进入数据持久化的行列。我们使用mysql举例,他的默认端口是3306,java程序通过这个端口和mysql提供的连接接口实现了数据持久化,这样一个服务器端硬盘闭环传输问题就从逻辑上解决了。
我们的研究定位到了javaweb模型图右下角的mysql模块,从这里是构建javaweb项目开始,根据模型我们看到了下一个环节。
此时,还需要一个输入和输出的载体,java提供了awt和swing来完成它的图形化,但是由于使用过的人说很不好,所以没使用过的人也就对它不理睬了。
到此刻已经是一个局域网内的C/S架构的软件了,只要他们配置的是同一个数据库,他们就可以实现数据的共享和操作,这类软件太多了,几乎都成了规模化生产了,像什么各类的管理系统。
去掉javaGUI,我们继续看图。tomcat提供了servlet,你需要开启tomcat服务器,这个服务器的端口是8080,我们这个时候仍然需要一个用于表现的载体,说白了就是如何让html文件和java文件联系起来。
启动tomcat之后可以看得出来localhost:8080打开的网页实际上是这个网页(index.jsp),按照链接规范原则上我们可以访问该目录下的所有开放资源。

我很抱歉我把图片顺序弄得一塌糊涂,但就是这个意思。实际上这种访问我们不通过tomcat也可以实现,你只需要在同级目录下创建一个html5文件和json文件并使用超链接访问即可。那么使用tomcat的意义在哪呢?
就像我们刚才说的重点在于实现html和java文件的联系http发布一个请求这请求是一个路径,由于这个请求是在tomcat服务器内发生的,tomcat服务器提供了一个路径映射文件,通过路径映射文件去寻找开放目录下的class文件(被编译的java