上节讨论了如何保障数据中台的数据质量,让数据“准”。除了“快”和“准”,数据中台还离不开“省”。随数据规模越来越大,成本越来越高,如不合理控制成本,还没等你挖掘出数据应用价值,企业利润就被消耗完。
能否做到精细化成本管理,关乎数据中台项目成败。
某电商业务数据建设资源增长趋势(CU= 1vcpu + 4G memory):
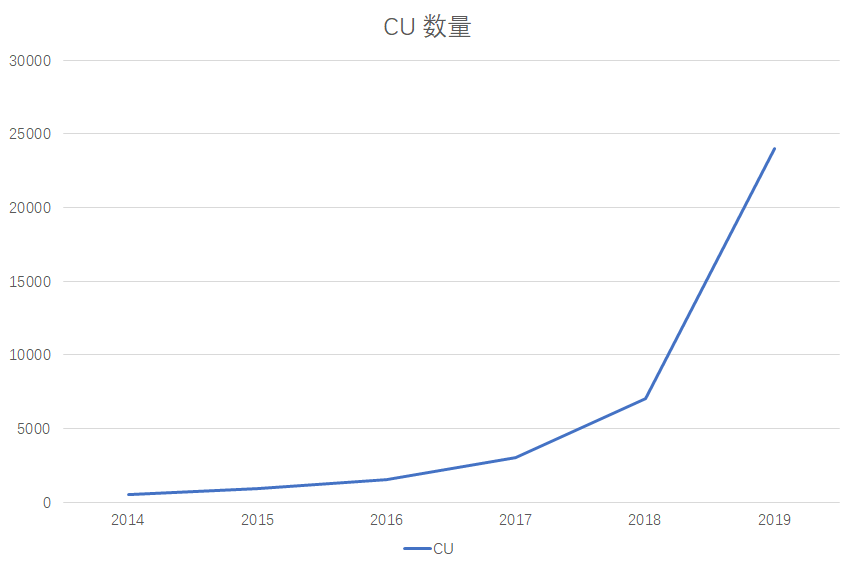
某电商平台的大数据资源消耗增长趋势,2019全年资源规模25000CU,全年机器预算3500W。对创业企业显然不小开支。
一天,数据团队负责人李好看被CEO叫到了办公室:
- 这3500W花在什么业务?
- 你们做了哪些成本优化的举措,效果如何?
把李问懵,他心想:团队的成本是按机器又不是数据应用核算。在数据中台中,数据应用之间的底层数据是复用的,那具体每个数据产品或者报表花了多少钱,自己没有这样的数据啊,咋可能知道。
可对CEO这些很重要,因为资源有限,他须确保资源都用在战略目标的关键节点。如电商团队今年核心KPI是提升单个注册会员在平台的消费额,老板角度,他须确保资源都投入与KPI相关业务,如基于数据对注册会员精准化营销,提升会员在平台的消费额。
自己所在的团队是否发生过类似的事情? 数据部门是企业的成本中心,如要展现自己的价值:
- 支撑好业务,获得业务的认可
- 精简成本,为公司省钱
所以,今天重点在省钱,聊数据中台的精细化成本管理。
1 成本陷阱
一开始建设数据中台时,你往往会关注新业务的接入,数据的整合,数据价值的挖掘上,忽略成本管控的问题,从而落入陷阱中,造成成本爆炸式的增长。所以,有必要深入了解有哪些陷阱,尽量在日常开发中避免。
这里总结8种陷阱:
- 1~3广泛存在,但易被忽略
- 4~8涉及数据开发中一些技能,开发时注意就可
“知其然,更要知其所以然”,才能发现问题本质,深入掌握解决问题的方法。
1.1 数据上线容易,下线难
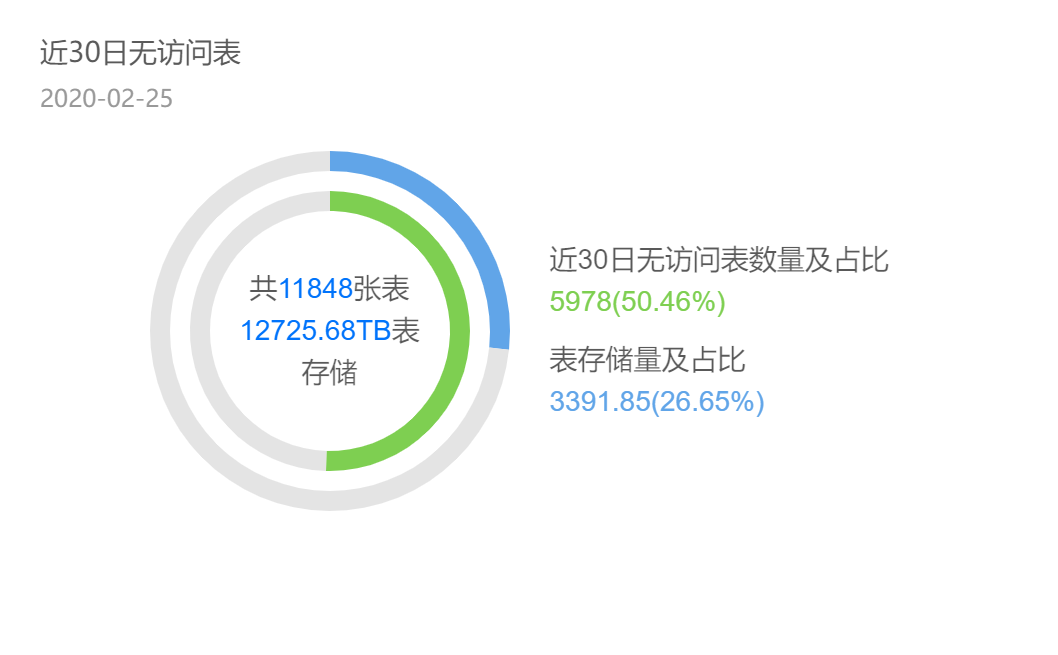
某数据中台项目,表相关的使用统计。一半的表30d内都没有访问,而这些表占26%存储。如把这些表的产出任务单独拎出,高峰期需消耗5000Core CPU计算资源,换算成服务器需125台(按一台服务器可分配CPU 40Core计算),成本一年近500W。自己竟然有这么多无用数据?我经常把数据比作手机中的图片,我们不断拍照生图,却懒得清,最终手机存储经常不够。
无法及时清数据,数据开发也有苦衷。他们不知道一个表:
- 还有哪些任务在引用
- 还有哪些人在查询
自然不敢停止这个表的数据加工,导致数据上线易,下线难。
1.2 低价值的数据应用消耗了大量的资源
数据看上去每天都被访问,但究竟产出多少价值,ROI值得吗?
有个宽表(拥有很多列的表,经常出现在数据中台下游的汇总层数据中),加上上游加工链路的任务,每天加工这张宽表要消耗6000块钱,一年200W,可追查后我们发现,这张宽表实际每天只有一个人在使用,还是一个运营的实习生。显然,投入和产出极不匹配。
间接说明,数据部门比较关注新的数据产品带给业务的价值,却忽略已存产品或报表是否还存在价值,最终导致低价值的应用仍大量耗资源。
1.3 烟囱式的开发模式
不仅研发效率低,因数据重复加工,还资源浪费。一张500T表,加工这表,计算任务需高峰期消耗300Core,折合7台服务器(按一台服务器可分配CPU 40Core计算),加上存储盘成本(按照0.7 元/TB*天计算),一年消耗40W。
而这张表每复用一次,就可节省40W。所以模型复用,还可实现省钱。
第四,数据倾斜。
数据倾斜会让任务性能变差,也会浪费大量的资源,那什么是数据倾斜呢?
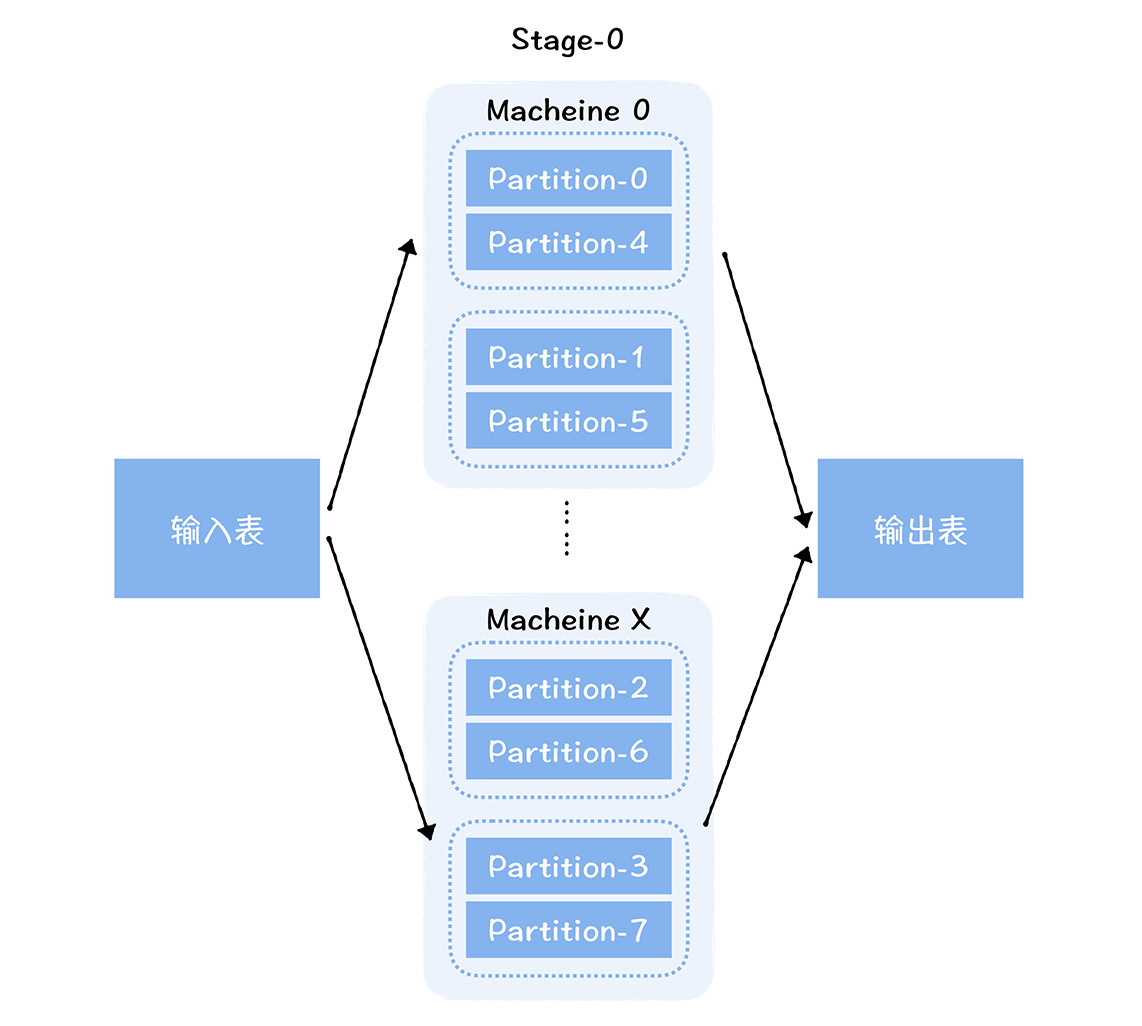
你肯定听说过木桶效应吧?一个木桶装多少水,主要取决于最短的那块板。对于一个分布式并行计算框架来说,这个效应同样存在。对于Spark计算引擎来说,它可以将海量的数据切分成不同的分片(Partition),分配到不同机器运行的任务中,进行并行计算,从而实现计算能力水平扩展。
但是整个任务的运行时长,其实取决于运行最长的那个任务。因为每个分片的数据量可能不同,每个任务需要的资源也不相同。由于不同的任务不能分配不同的资源,所以,总任务消耗资源=max{单个任务消耗的资源} * 任务数量。这样一来,数据量小的任务会消耗更多的资源,就会造成资源的浪费。
我们还是举个电商场景的例子。
假设你需要按照商户粒度统计每个商户的交易金额,此时,我们需要对订单流水表按照商户进行group by计算。在平台上,每个商户的订单交易量实际差距很大,有的订单交易量很多,有的却比较少。
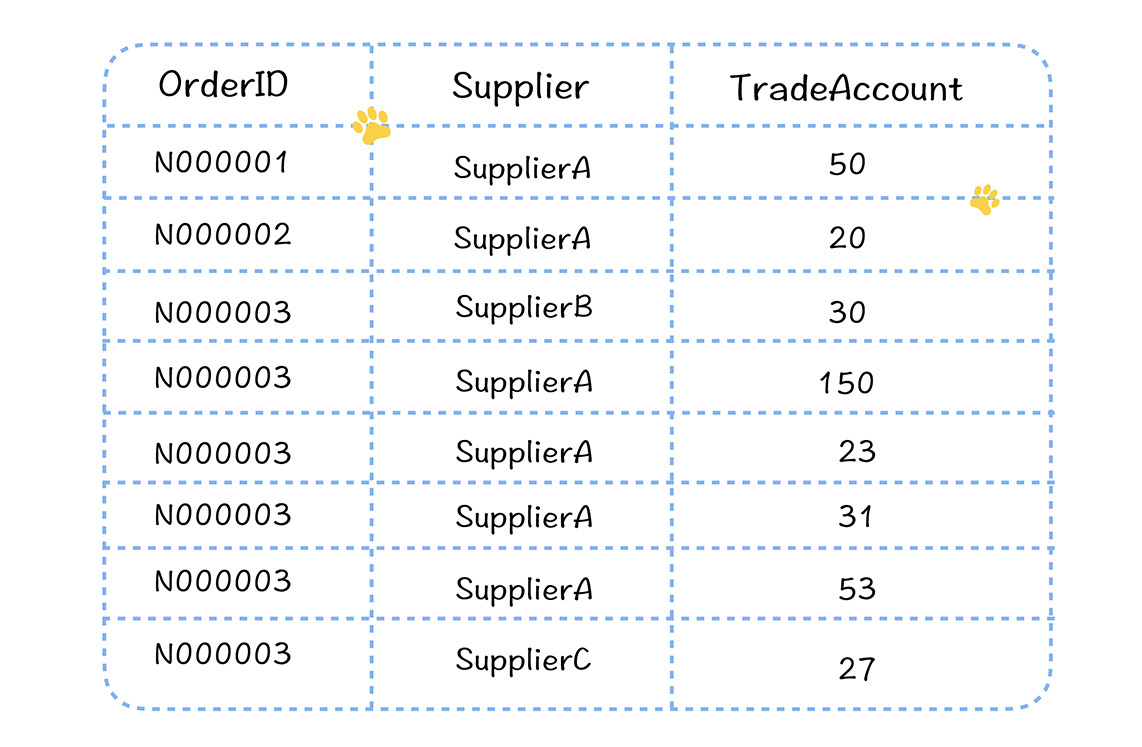
我们利用Spark SQL完成计算过程。
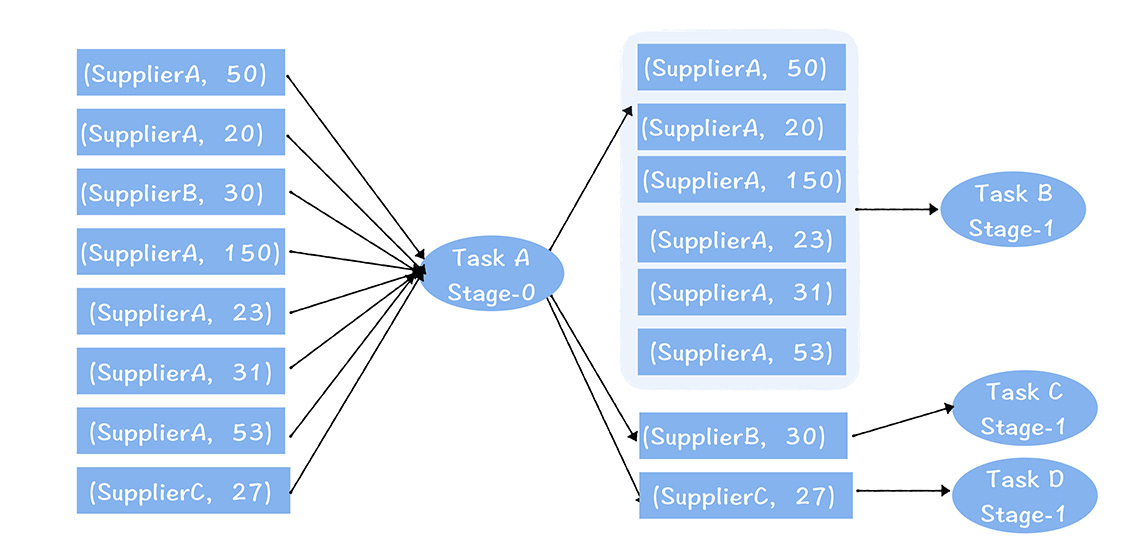
在上图中,任务A 读取了左边某个分片的数据,按照供应商进行聚合,然后输出给下一个Stage的B、C、D任务。
你可以看到,聚合后,B、C和D任务输入的数据量有很大的不同,B处理的数据量比C和D多,消耗的内存自然更多,假设单个Executor需要分配16G,而B、C、D不能设置不同的内存大小,所以C和D也都设置了16G。可实际上,按照C和D的数据量,只需要4G就够了。这就造成了C和D 任务资源分配的浪费。
第五,数据未设置生命周期。
在06讲中,我强调,一般原始数据和明细数据,会保留完整的历史数据。而在汇总层、集市层或者应用层,考虑到存储成本,数据建议按照生命周期来管理,通常保留几天的快照或者分区。如果存在大表没有设置生命周期,就会浪费存储资源。
第六,调度周期不合理。
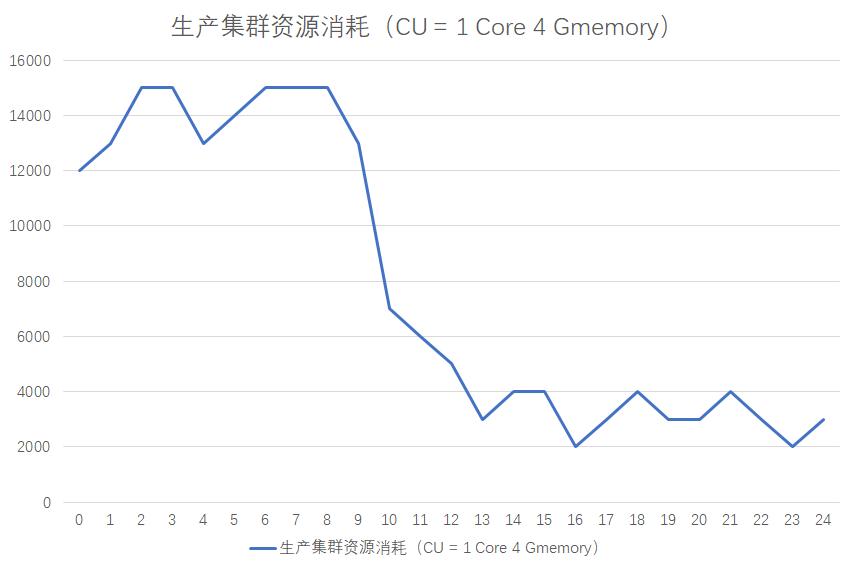
通过这张图你可以看到,大数据任务的资源消耗有很明显的高峰和低谷效应,一般晚上12点到第二天的9点是高峰期,9点到晚上12点,是低谷期。
虽然任务有明显的高峰低谷效应,但是服务器资源不是弹性的,所以就会出现服务器在低谷期比较空闲,在高峰期比较繁忙的情况,整个集群的资源配置取决于高峰期的任务消耗。所以,把一些不必要在高峰期内运行任务迁移到低谷期运行,也可以节省资源的消耗。
第七,任务参数配置。
任务参数配置的不合理,往往也会浪费资源。比如在Spark中,Executor 内存设置的过大;CPU设置的过多;还有Spark 没有开启动态资源分配策略,一些已经运行完Task的Executor 不能释放,持续占用资源,尤其是遇到数据倾斜的情况,资源浪费会更加明显。
第八,数据未压缩。
Hadoop 的HDFS 为了实现高可用,默认数据存储3副本,所以大数据的物理存储量消耗是比较大的。尤其是对于一些原始数据层和明细数据层的大表,动辄500多T,折合物理存储需要1.5P(三副本,所以实际物理存储5003),大约需要16台物理服务器(一台服务器可分配存储按照128T计算),如果不启用压缩,存储资源成本会很高。
另外,在Hive或者Spark 计算过程中,中间结果也需要压缩,可以降低网络传输量,提高Shuffer (在Hive或者Spark 计算过程中,数据在不同节点之间的传输过程)性能。
你看,我为你列举了8个典型的成本陷阱,那你可能会问了,老师,我已经中招了,该怎么办呢? 别急,接下来我们就看一看,如何进行精细化的成本管理。
2 如何实现精细化成本管理?
成本治理应遵循全局盘点、发现问题、治理优化和效果评估四步。
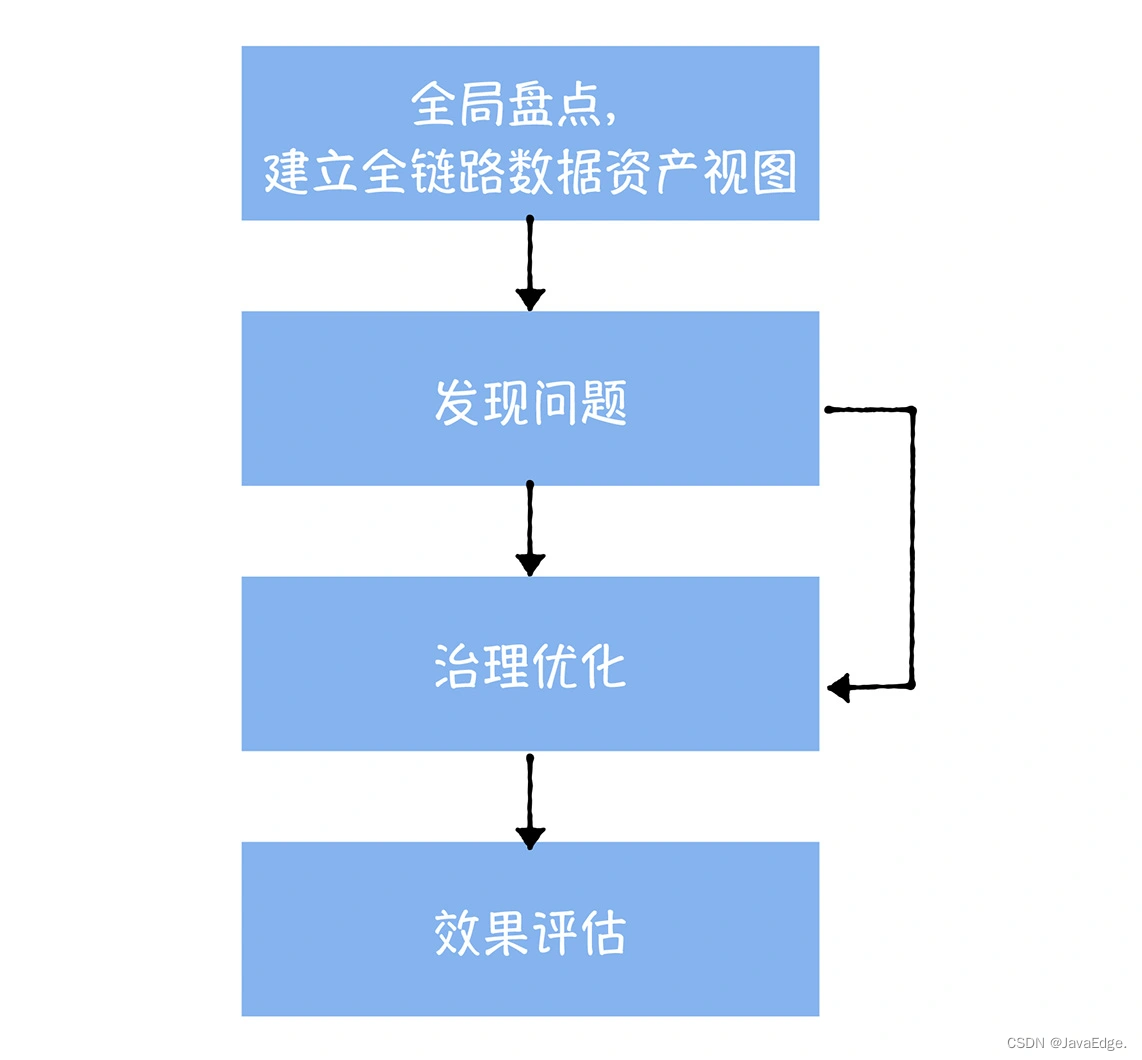
2.1 全局资产盘点
对数据中台中,所有的数据进行一次全面盘点,基于元数据中心提供的数据血缘,建立全链路的数据资产视图。
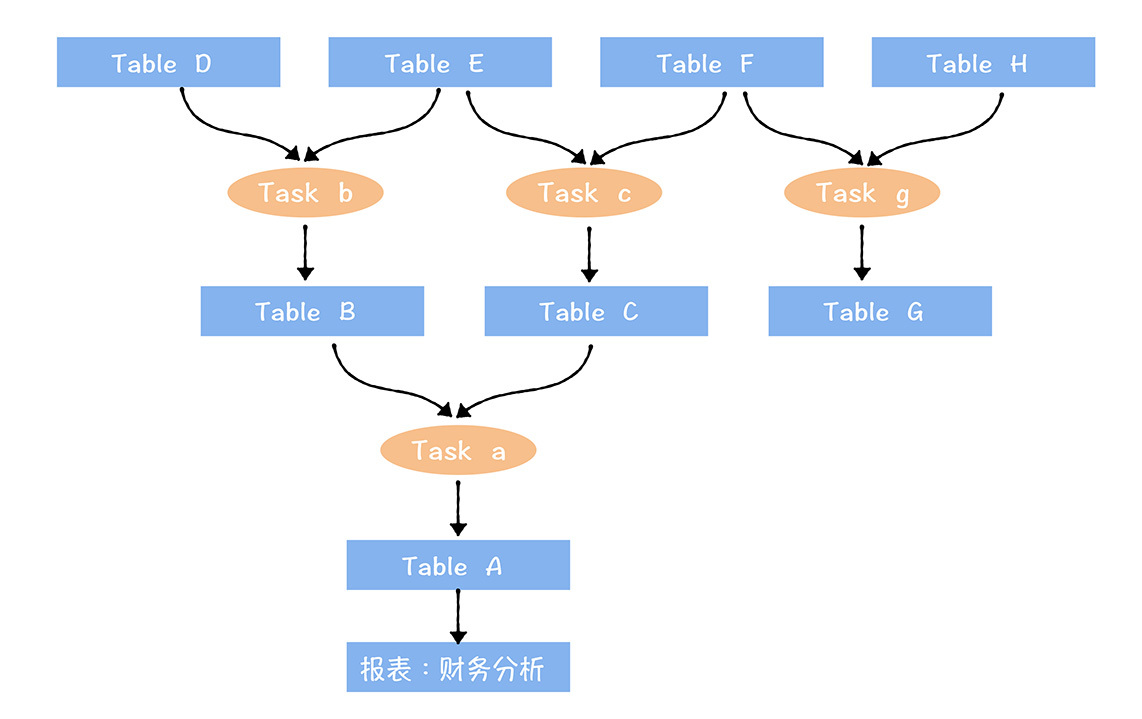
全链路数据资产视图:
- 下游末端关联到数据