这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1
分析网址,参数'page/'后面的数字'1'指的是页数,第二页就是'/page/2',以此类推。。。
一、分析网页
网页图片

然后明确要爬取的元素:作者名、内容、好笑数、以及评论数量
每一个段子的信息存放在'div id="content-left"'下的div中
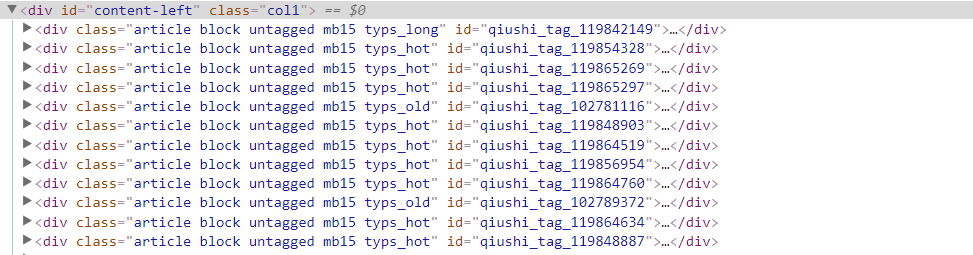
爬取元素的所在位置
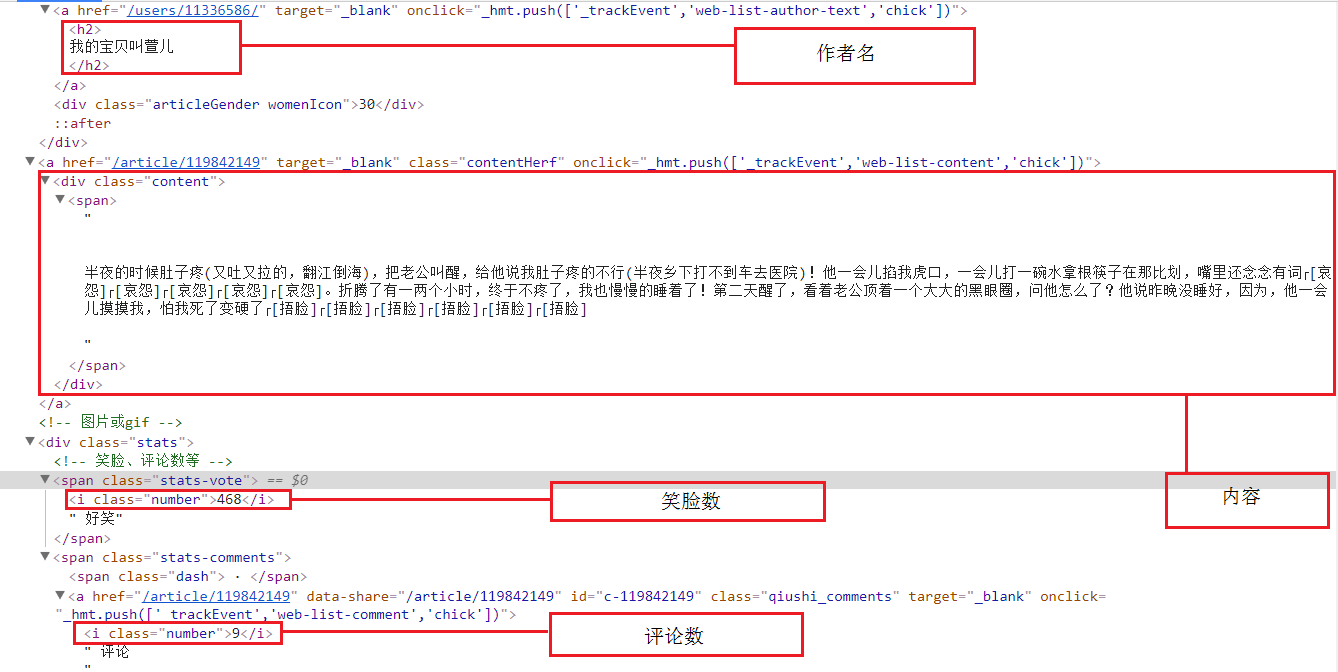
二、爬取部分
工具:
Python3
requests
xpath
1、获取每一个段子
1 # 返回页面的div_list 2 def getHtmlDivList(self, pageIndex): 3 pageUrl = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex) 4 html = requests.get(url=pageUrl, headers=self.headers).text 5 selector = etree.HTML(html) 6 divList = selector.xpath('//div[@id="content-left"]/div') 7 return divList
每一个段子都在div中,这里用xpath,筛选出来后返回的是一个列表,每一个div都在里面
2、获取每一个段子中的元素
1 def getHtmlItems(self, divList): 2 3 items = [] 4 5 for div in divList: 6 item = [] 7 # 发布人 8 name = div.xpath('.//h2/text()')[0].replace("\n", "") 9 item.append(name) 10 11 # 内容(阅读全文) 12 contentForAll = div.xpath('.//div[@class="content"]/span[@class="contentForAll"]') 13 if contentForAll: 14 contentForAllHref = div.xpath('.//a[@class="contentHerf"]/@href')[0] 15 contentForAllHref = "https://www.qiushibaike.com" + contentForAllHref 16 contentForAllHrefPage = requests.get(url=contentForAllHref).text 17 selector2 = etree.HTML(contentForAllHrefPage) 18 content = selector2.xpath('//div[@class="content"]/text()') 19 content = "".join(content) 20 content = content.replace("\n", "") 21 else: 22 content = div.xpath('.//div[@class="content"]/span/text()') 23 content = "".join(content) 24 content = content.replace("\n", "") 25 item.append(content) 26 27 # 点赞数 28 love = div.xpath('.//span[@class="stats-vote"]/i[@class="number"]/text()') 29 love = love[0] 30 item.append(love) 31 32 # 评论人数 33 num = div.xpath('.//span[@class="stats-comments"]//i[@class="number"]/text()') 34 num = num[0] 35 item.append(num) 36 37 items.append(item) 38 39 return items
这里需要注意的是,xpath返回的是一个列表,筛选出来后需要用[0]获取到字符串类型
上面的代码中,爬取的内容里,有的段子是这样的,如下图:

内容中会有标签<br>,那么用xpath爬取出来后,里面的内容都会成一个列表(这里的div就是列表),
那div[0]就是"有一次回老家看姥姥,遇到舅妈说到表弟小时候的事~",所以需要将div转换成字符串
其他的部分就xpath语法的使用
3、保存进文本
1 # 保存入文本 2 def saveItem(self, items): 3 f = open('F:\\Pythontest1\\qiushi.txt', "a", encoding='UTF-8') 4 5 for item in items: 6 name = item[0] 7 content = item[1] 8 love = item[2] 9 num = item[3] 10 11 # 写入文本 12 f.write("发布人:" + name + '\n') 13 f.write("内容:" + content + '\n') 14 f.write("点赞数:" + love + '\t') 15 f.write("评论人数:" + num) 16 f.write('\n\n') 17 18 f.close()
4、全部代码


1 import os 2 import re 3 import requests 4 from lxml import etree 5 6 7 # 糗事百科爬虫 8 class QSBK: 9 # 初始化方法,定义变量 10 def __init__(self): 11 self.pageIndex = 1 12 self.headers = { 13 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" 14 } 15 self.enable = False 16 17 # 返回页面的div_list 18 def getHtmlDivList(self, pageIndex): 19 pageUrl = 'http://www.qiushibaike.com/hot/page/' + str(pageIndex) 20 html = requests.get(url=pageUrl,