|
观地知道某个位置上数值的大小。另外你也可以将这个位置上的颜色,与数据集中的其他位置颜色进行比较。
热力图是一种非常直观的多元变量分析方法。
我们一般使用Seaborn中的sns.heatmap(data)函数,其中data代表需要绘制的热力图数据。
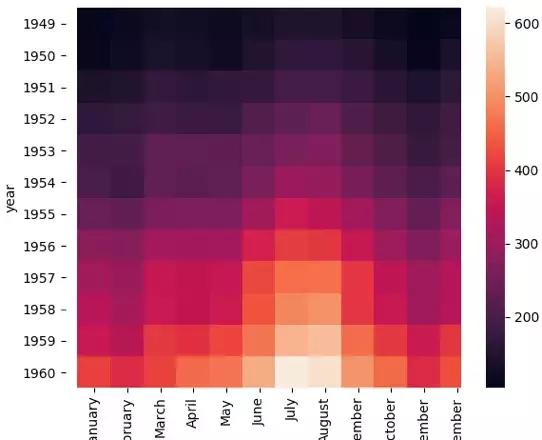
这里我们使用Seaborn中自带的数据集flights,该数据集记录了1949年到1960年期间,每个月的航班乘客的数量。
# 数据准备
flights = sns.load_dataset("flights")
data=flights.pivot('year','month','passengers')
# 用Seaborn画热力图
sns.heatmap(data)
plt.show()
通过seaborn的heatmap函数,我们可以观察到不同年份,不同月份的乘客数量变化情况,其中颜色越浅的代表乘客数量越多,如下图所示:
成对关系
如果想要探索数据集中的多个成对双变量的分布,可以直接采用sns.pairplot()函数。它会同时展示出DataFrame中每对变量的关系,另外在对角线上,你能看到每个变量自身作为单变量的分布情况。它可以说是探索性分析中的常用函数,可以很快帮我们理解变量对之间的关系。
pairplot函数的使用,就好像我们对DataFrame使用describe()函数一样方便,是数据探索中的常用函数。
这里我们使用Seaborn中自带的iris数据集,这个数据集也叫鸢尾花数据集。鸢尾花可以分成Setosa、Versicolour和Virginica三个品种,在这个数据集中,针对每一个品种,都有50个数据,每个数据中包括了4个属性,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。通过这些数据,需要你来预测鸢尾花卉属于三个品种中的哪一种。
# 数据准备
iris = sns.load_dataset('iris')
# 用Seaborn画成对关系
sns.pairplot(iris)
plt.show()
这里我们用seaborn中的pairplot函数来对数据集中的多个双变量的关系进行探索,如下图所示。从图上你能看出,一共有sepal_length、sepal_width、petal_length和petal_width4个变量,它们分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。
下面这张图相当于这4个变量两两之间的关系。比如矩阵中的第一张图代表的就是花萼长度自身的分布图,它右侧的这张图代表的是花萼长度与花萼宽度这两个变量之间的关系。
|