PythonКЏЪ§жаЪЙгУ@
ЩдЬсвЛЯТЕФЛљДЁ
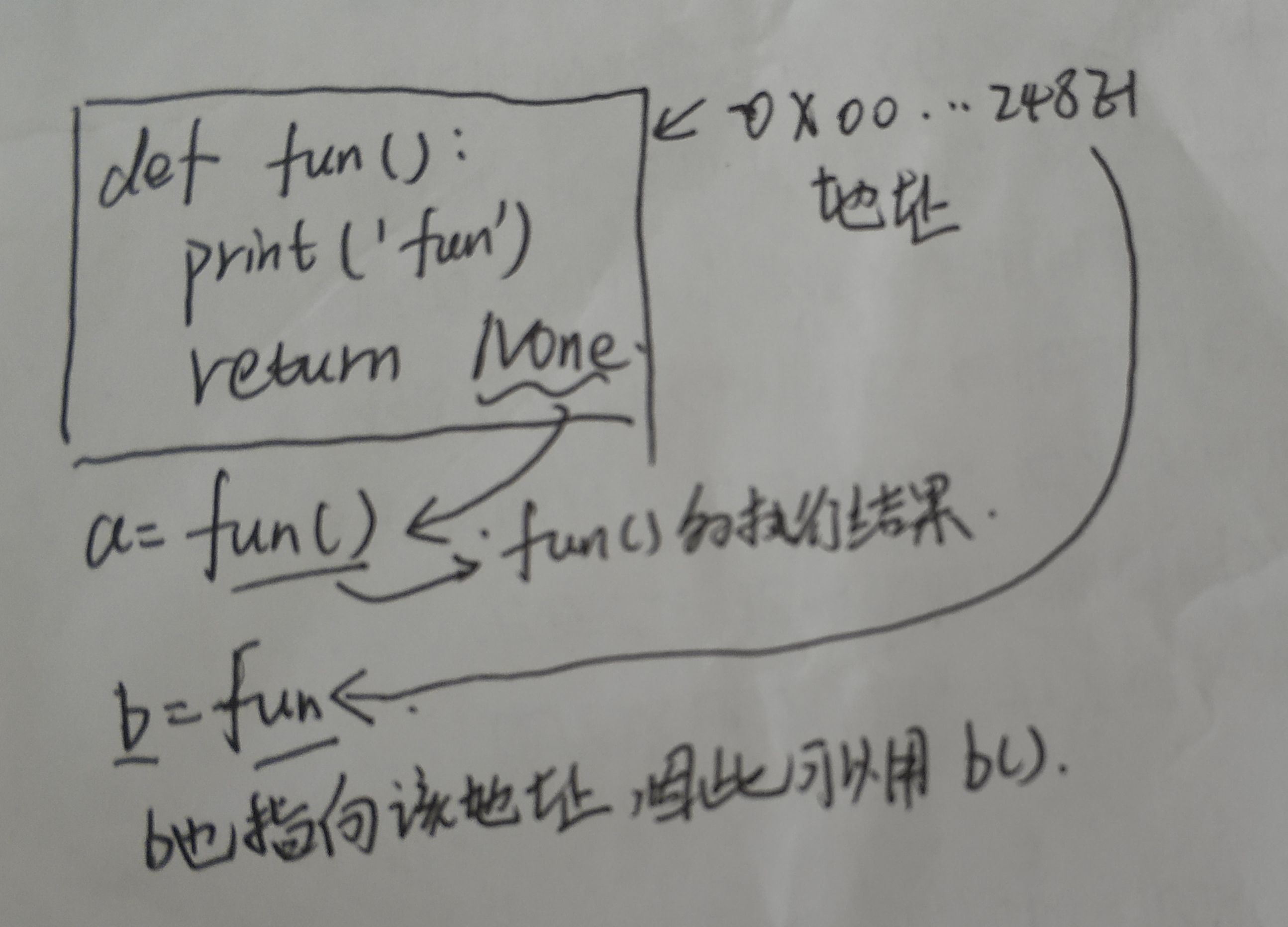
fun КЭfun()ЕФЧјБ№
вдвЛЖЮДњТыЮЊР§ЃК
def fun():
print('fun')
return None
a = fun() #funКЏЪ§ВЂНЋЗЕЛижЕИјa
print('aЕФжЕЮЊ',a)
b = fun #НЋfunКЏЪ§ЕижЗИГИјb
b() #ЕїгУbЃЌbКЭfunжИЯђЕФЕижЗЯрЭЌ
print('bЕФжЕЮЊ',b)
'''ЪфГі
fun
aЕФжЕЮЊ None
fun
bЕФжЕЮЊ <function fun at 0x00000248E1EBE0D0>
'''ИљОнЪфГіПЩвдПДГіЃЌa=fun()ЪЧНЋКЏЪ§funЕФЗЕЛижЕЃЈNoneЃЉИГИјaЃЌЖјb=funЪЧНЋКЏЪ§ЕФЕижЗИГИјb,ШчЙћЕїгУКЏЪ§ЃЌашвЊb()
РрЫЦЕФЃЌЦфЫћФкжУКЏЪ§вВПЩвдЭЈЙ§етжжЗНЗЈЃЌЯрЕБгкЦ№СЫвЛИіЭЌУћЕФКЏЪ§
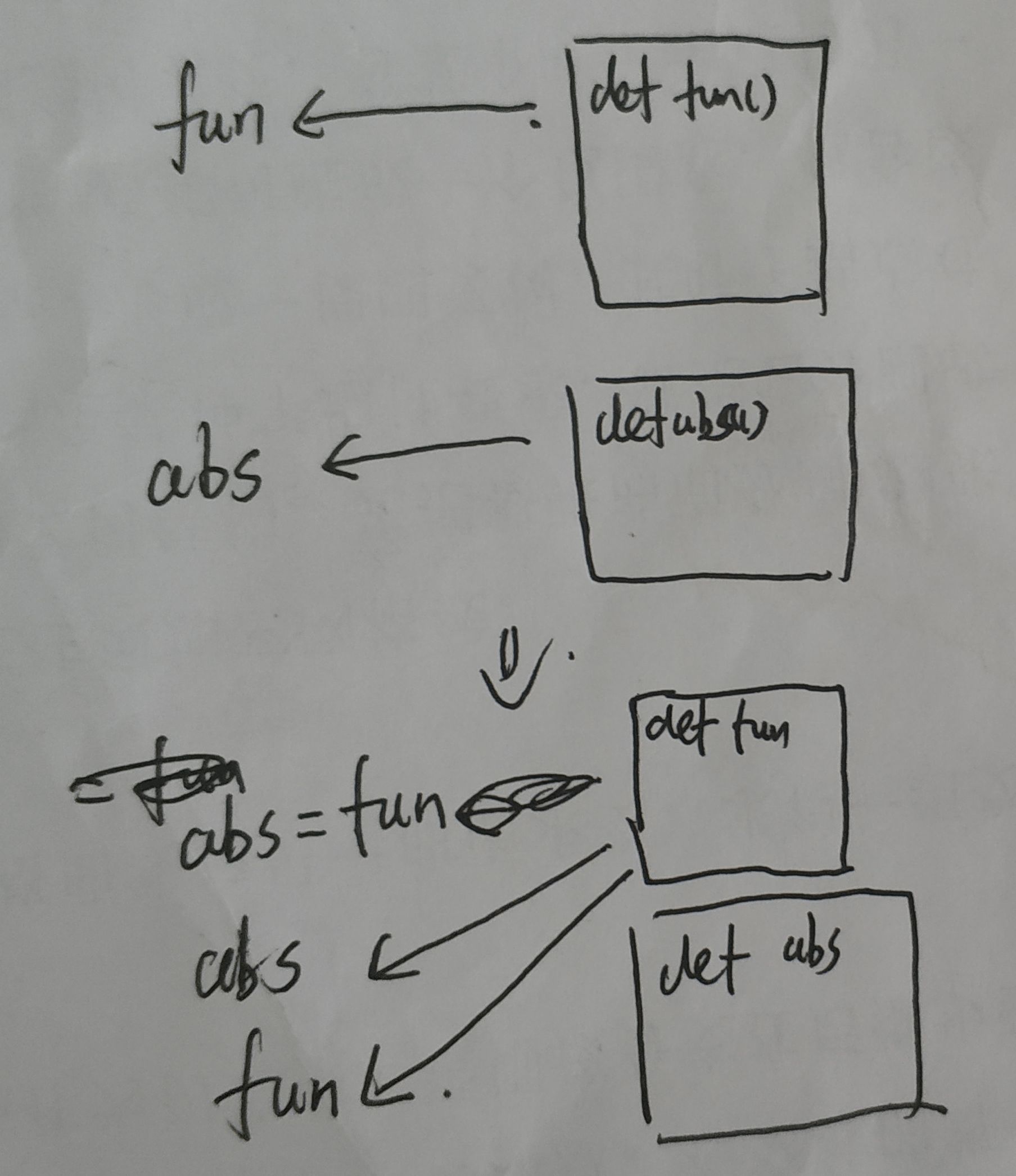
>>>a = abs
>>>a(-1)
1Г§ДЫжЎЭтЃЌдРДЕФКЏЪ§УћвВБЛИВИЧЮЊЦфЫћКЏЪ§ЃЌР§Шч
def fun():
print('fun')
abs = fun
abs() #ЪфГіfun
злЩЯЃЌПЩвдРэНтЮЊfunЃЌabsдкВЛДјРЈКХЪБЮЊБфСПЃЌИУБфСПАќКЌСЫКЏЪ§дкФкШнЕФЕижЗ
ЗЕЛиКЏЪ§
ВЮПМСДНгЃКhttps://www.liaoxuefeng.com/wiki/1016959663602400/1017434209254976
вдСЮРЯЪІЕФНЬГЬЮЊР§
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
>>> f = lazy_sum(1, 3, 5, 7, 9)
>>> f
<function lazy_sum.<locals>.sum at 0x101c6ed90>
>>>f()
25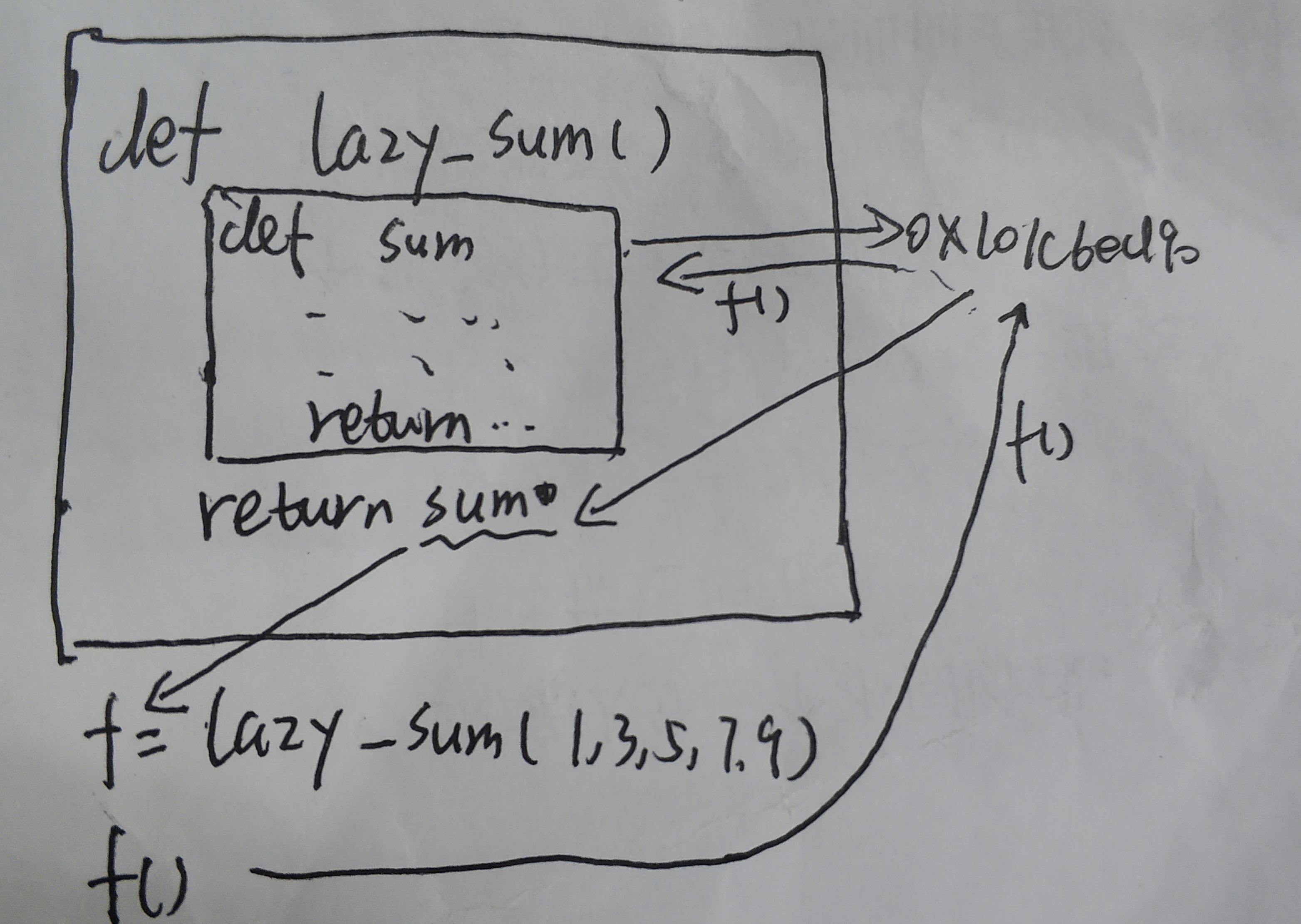
дкЕЅВНЕїЪджаПЩвдЗЂЯжЃЌЕБЖСЕНdef sum():ЪБЃЌНтЪЭЦїЛсжБНгЬјЕНreturn sumНЋsumКЏЪ§ЕФЕижЗЗЕЛиИјfЃЌвђДЫf()МДЮЊжДааsum() (ВЛЪЧЗЧГЃзМШЗЃЌЕЋЯШШчДЫРэНт)
ШчЙћЖдЗЕЛиКЏЪ§ЛЙЪЧгааЉВЛРэНтЕФЛАЃЌПЩвдМйЩшlazy_sum()ЕФЗЕЛижЕИФЮЊ1
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return 1
f = lazy_sum(1,3,5,7,9)
print(f)#QЪфГі1
print(f())#БЈДэ'int' object is not callable
ДЫЪБЮоТлlazy_sum()ЕФВЮЪ§ШчКЮаоИФЃЌЖМЛсАб1ИГИјf,Жј1()ЪЧВЛПЩЕїгУЕФЃЌвђДЫЛсБЈДэ
?ЗЕЛиКЏЪ§жаЕФБеАќЮЪЬтвВвЊСЫНтвЛЯТЃЌФкЧЖКЏЪ§ПЩвдЗУЮЪЭтВуКЏЪ§ЕФБфСП
ВЮЪ§ЕФЧЖЬзЕїгУ
ШдШЛЩЯЪіР§згЃЌДЫЪБНЋlazy_sum()ИФЮЊПеКЏЪ§ЃЌФкЧЖЕФsum()ашвЊВЮЪ§ЃК
def lazy_sum():
def sum(*args):
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f = lazy_sum()(1,3,5,7,9)
print(f)#ЪфГі25АДеедЫЫуЕФгХЯШМЖЃЌПЩвдРэНтЮЊЃК
- жДаа
lazy_sum()ЃЌЗЕЛиsum; - жДаа
sum(1,3,5,7,9)ЃЌЗЕЛи25; - НЋ
25ИГИјf
ШчЙћгаСЫвдЩЯЛљДЁЃЌдйРДПД@ЕФгУЗЈОЭЛсОѕЕУКмШнвзСЫ
@ЕФЪЙгУ
ШчЙћашвЊОпЬхРэНтзАЪЮЦїЃЌПЩвдВЮПМСЮРЯЪІЕФВЉПЭЃЌБОЮФНіНщЩм@ЕФжДааСїГЬ
БОЮФВЮПМСЫ Python @КЏЪ§зАЪЮЦїМАгУЗЈЃЈГЌМЖЯъЯИЃЉЃЌPythonжаЕФзЂНтЁА@ЁБ
ВЛДјВЮЪ§ЕФЕЅвЛЪЙгУЃЈвЛИі@аоЪЮЃЉ
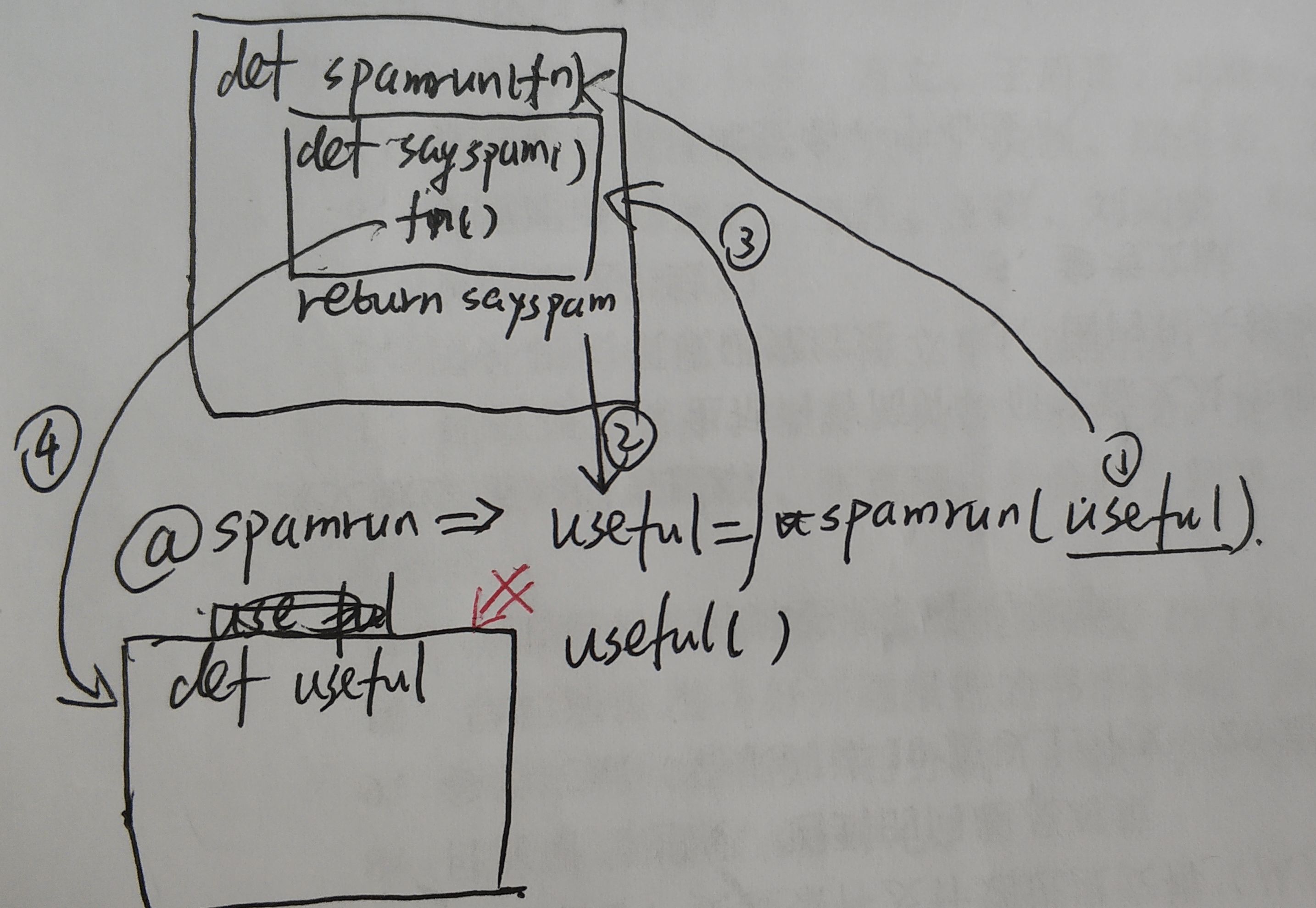
def spamrun(fn):
def sayspam():
print("spam,spam,spam")
fn()
return sayspam
@spamrun
def useful():
print('useful')
useful()
'''
ЪфГіЃК
spam,spam,spam
useful
'''аоЪЮаЇЙћЯрЕБгкuseful = spamrun(useful)ЃЌОпЬхВНжшШчЯТЃК
- дкГѕЪМЛЏЪБЃЌНтЪЭЦїЖСЕН
@spamrun,ДЫЪБНЋЯТЗНЕФusefulзїЮЊВЮЪ§ДЋШыЕНspamrunжа spamrun(useful)жаЃЌгЩгкЪЧЗЕЛиКЏЪ§ЃЌжБНгНЋsayspam()ЕФФкДцЕижЗИГИјuseful- жДаа
useful(),ДЫЪБusefulжИЯђСЫsayspamЃЌвђДЫДђгЁspam,spam,spamЁЃШЛКѓжДааfn()ЃЌДЫЪБЕФfnВХжИЯђдРДЕФuseful()ЕФЕижЗЃЌПЊЪМжДааprint('useful')
жДааСїГЬПЩвддкЯТЭМСЫНтвЛЯТЃЌПЩвдРэНтЮЊОЙ§@КѓЃЌusefulвбОВЛжБНгжИЯђКЏЪ§useful()ЕФЕижЗСЫЃЌЖјЪЧsayspamЁЃдйЕїгУuseful()ЪБЃЌжДааsayspam(),гЩгкfnБЃДцдЯШuseful()КЏЪ§ЕФЕижЗЃЌвђДЫПЩвджДааuseful()ЕФЙІФмЃЌМДПЩвдДђгЁГі'useful'ЁЃШчЙћЁЎЪЙЛЕЁЏАбfn()ШЅЕєЕФЛАЃЌЯрЕБгкuseful()дйвВВЛЛсжДааСЫ
вЛАуЧщПіЯТЃЌЪЙгУ@ЪБВЛЛсИФБфКЏЪ§дЯШЕФжДааТпМЃЌЖјжЛЪЧдіМгЙІФмЃЌвђДЫГЩЮЊзАЪЮЦїЃЌШчСЮРЯЪІНЬГЬжаПЩвдЪЙдКЏЪ§ДђгЁШежО
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
now()
'''
call now():
2015-3-25
'''ВЛДјВЮЪ§ЕФЖрДЮЪЙгУЃЈСНИі@ЃЉ
def spamrun(fn):
def sayspam():
print("spam,spam,spam")
fn()
return sayspam
def spamrun1(fn):
def sayspam1():
print("spam1,spam1,spam1")
fn()
return sayspam1
@spamrun
@spamrun1
def useful():
print('useful')
useful()
'''
spam,spam,spam
spam1,spam1,spam1
useful
'''аоЪЮаЇЙћЯрЕБгкuseful = spamrun1(spamrun(useful))
? 1. НтЪЭЦїДгЩЯЕНЯТЖСШЁЃЌЯШЖСЕН@spamrun,гкЪЧЯђЯТВщевЕквЛИіКЏЪ§ЖЈвхuseful()ЃЌгкЪЧгаuseful=spamrun(useful)
? 2. дйЖСЕН@spamrun1ЃЌжиИДЩЯДЮВйзїЃЌЕЋДЫЪБЕФБфСПusefulвбОБЛзАЪЮЙ§вЛДЮЃЌдйБЛзАЪЮЕкЖўДЮЃЌвђДЫгаuseful=spamrun1(useful)
ДјВЮЪ§ЕФЕЅДЮЪЙгУ
вдСЮРЯЪІНЬГЬжаЕФОйР§ЃЌМђЛЏвЛаЉЃЌЯШВЛПМТЧ*args,**kwЃЌвђЮЊЩцМАЕНЗЕЛиКЏЪ§ЕФБеАќЮЪЬт
def log(text):
def decorator(func):
def wrapper():
print('%s %s():' % (text, func.__name__))
return func()
return wrapper
return decorator
@log('execute')
def now():