在2017年末,Face++发了一篇论文ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices讨论了一个极有效率且可以运行在手机等移动设备上的网络结构――ShuffleNet。这个英文名我更愿意翻译成“重组通道网络”,ShuffleNet通过分组卷积与\(1 \times 1\)的卷积核来降低计算量,通过重组通道来丰富各个通道的信息。这个论文的mxnet源码的开源地址为:MXShuffleNet。
分组卷积与核大小对计算量的影响
论文说中到“We propose using pointwise group convolutions to reduce computation complexity of 1 × 1 convolutions”,那么为什么用分组卷积与小的卷积核会减少计算的复杂度呢?先来看看卷积在编程中是如何实现的,Caffe与mxnet的CPU版本都是用差不多的方法实现的,但Caffe的计算代码会更加简洁。
不分组且只有一个样本
在不分组与输入的样本量为1(batch_size=1)的条件下,输出一个通道上的一个点是卷积核会与所有的通道卷积之积,如图1所示:
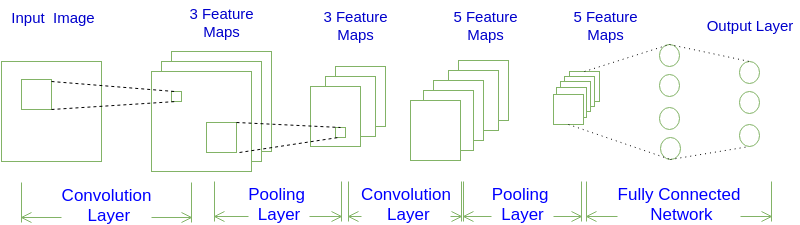
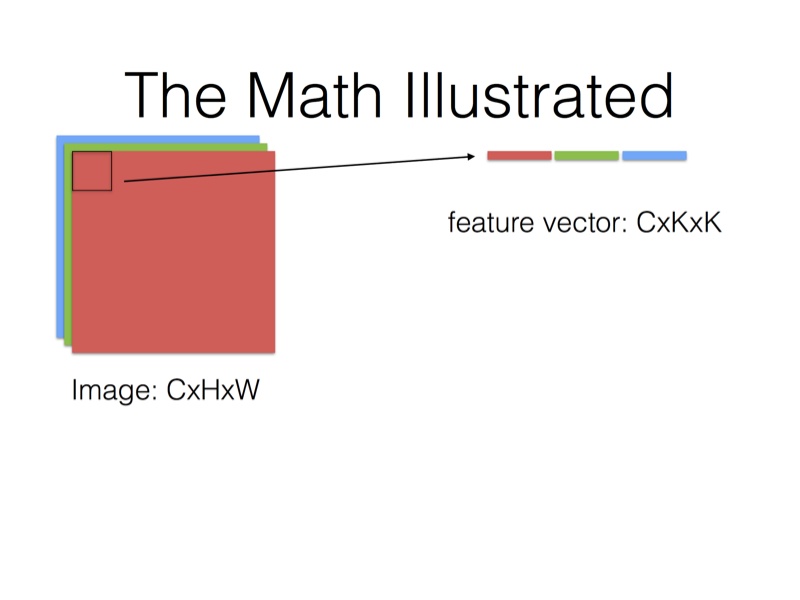
在Caffe的计算方法中,先要将输入张量为\(n \times C_{in} \times H_{in} \times W_{in}\)(n是batch_size)转化为一个$ \left(C_{in} \times H_k \times H_w\right) \times \left(H_{in} \times W_{in}\right)\(的矩阵,这个过程叫**im2col**。最后得到的输出张量为\)n \times C_{out} \times H_{in} \times W_{in}$。
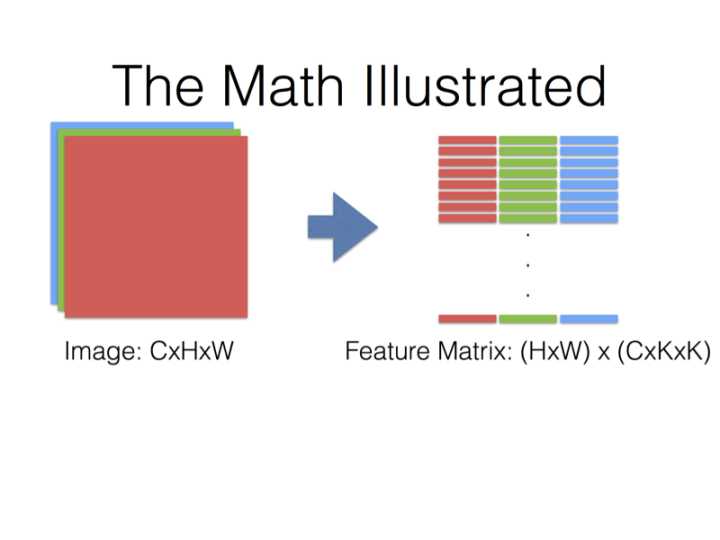
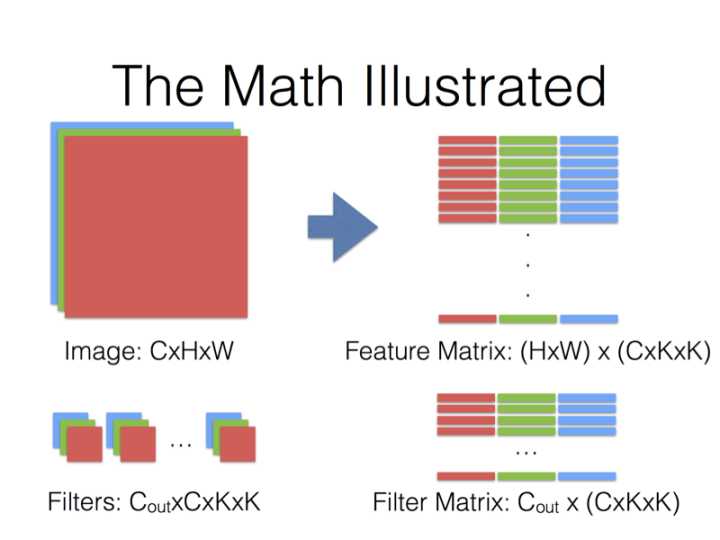
得到的两个矩阵Feature与Filter相乘得到输出矩阵Output,再Reshape成\(C_{out} \times C_{in} \times H_k \times W_k\)张量:
\[ Filter_{C_{out} \times \left( C_{in} \times K_h \times K_w \right)} \times Feature_{\left(C_{in} \times H_k \times H_w\right) \times \left(H_{out} \times W_{out}\right)} = Output_{C_{out} \times (H_{out} \times W_{out})} \tag{1.1} \]
现在的计算技术中,对方长度为\(n\)的方阵,计算量能从\(n^3\)代码到\(n^{2.376}\),最小的复杂度现在仍然未知,本文为了方便计算量就以\(n^3\)为基准。所以式(1.1)的矩阵计算最普通的计算量\(Computation\)是:
\[ Computation=C_{out} \times H_{out} \times W_{out} \times \left( C_{in} \times K_h \times K_w \right)^2 \tag{1.2} \]
从式(1.2)中可以看出来,卷积核的大小对计算量影响是很大的,\(3 \times 3\)的卷积核比\(1 \times 1\)的计算量要大\(3^4=81\)倍。
分组且只有一个样本
什么叫做分组,就是将输入与输出的通道分成几组,比如输出与输入的通道数都是4个且分成2组,那第1、2通道的输出只使用第1、2通道的输入,同样那第3、4通道的输出只使用第1、2通道的输入。也就是说,不同组的输出与输入没有关系了,减少联系必然会使计算量减小,但同时也会导致信息的丢失。
当分成g组后,一层参数量的大小由\(Filter_{C_{out} \times \left( C_{in} \times K_h \times K_w \right)}\)变成\(Filter_{C_{out} \times \left( C_{in} \times K_h \times K_w / g \right)}\)。Feature Matrix的大小虽然没发生变化,但是每一组的使用量是原来的$1/g,Filter也只用到所有参数的\(1/g\)\(。然后再循环计算\)g$次(同时FeatureMatrix与FilterMatrix要有地址偏移),那么计算公式与计算量的大小为:
\[ Filter_{C_{out}/g \times \left( C_{in} \times K_h \times K_w /g \right)} \times Feature_{\left(C_{in} \times H_k \times H_w /g\right) \times \left(H_{out} \times W_{out}\right)} = Output_{C_{out}/g \times (H_{out} \times W_{out})} \tag{1.3} \]
\[ Computation=C_{out} \times H_{out} \times W_{out} \times \left( C_{in} \times K_h \times K_w /g \right)^2 \tag{1.4} \]
所以,分成\(g\)组可以使参数量变成原来的\(1/g\),计算量是原来的\(1/g^2\)。
多个样本输入
为了节省内存,多个样本输入的时候,上述的所有过程都不会改变,而是每一个样本都运行一次上述的过程。
以上只是最简单、粗略的分析,实际上计算效率的提升并不会有上述这么多,一方面因为im2col会消耗与矩阵运算差不多的时间,另一方面因为现代的blas库优化了矩阵运算,复杂度并没有上述分析的那么多,还有计算过程for循环是比较耗时的指令,即使用openmp也不能优化卷积的计算过程。
交换通道(Shuffle Channels)
在上面我提到过,分组会导致信息的丢失,那么有没有办法来解决这个问题呢?这个论文给出的方法就是交换通道,因为在同一组中不同的通道蕴