第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter=
分析网址'?'符号后的参数,第一个参数'start=0',这个代表页数,‘=0’时代表第一页,‘=25’代表第二页。。。以此类推
一、分析网页:
网页图片

明确要爬取的元素 :排名、名字、导演、评语、评分,在这里利用Chrome浏览器,查看元素的所在位置
每一部电影信息都在<li></li>当中
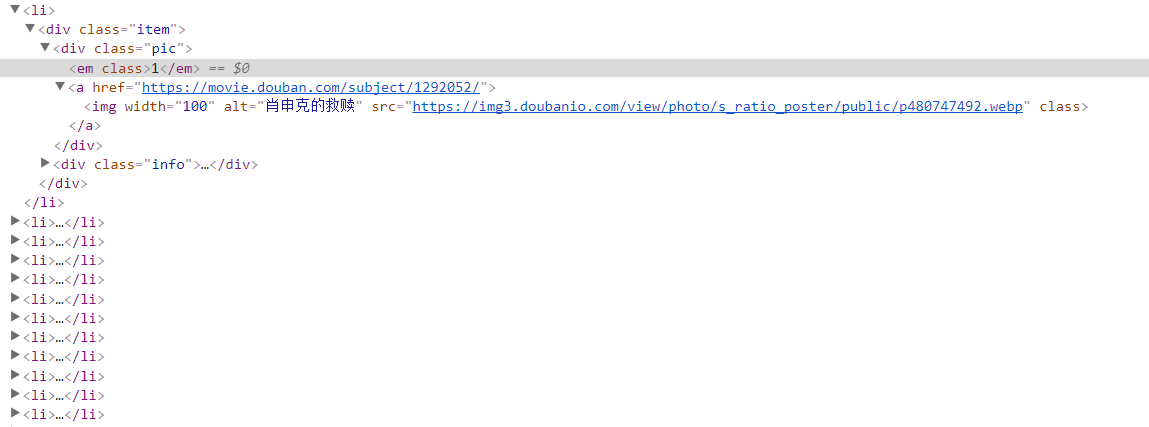
爬取元素的所在位置
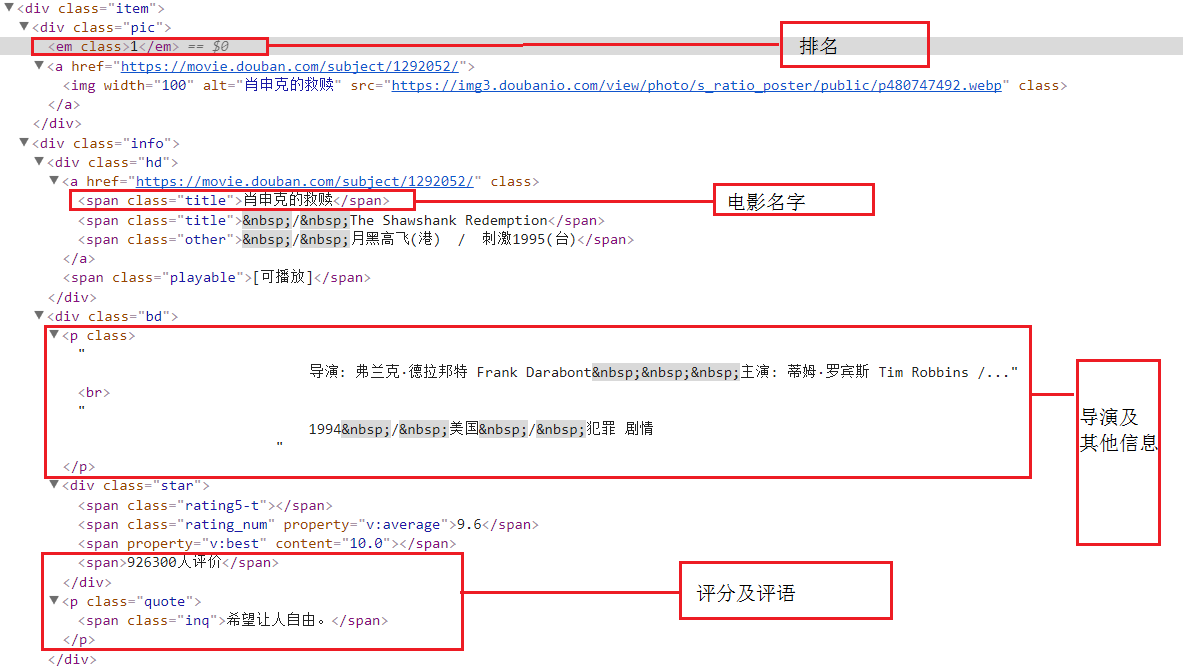
分析完要爬取的元素,开始准备爬取的工作
二、爬取部分:
工具:
Python3
requests
BeautifulSoup
1、获取每一部电影的信息
1 def get_html(web_url): # 爬虫获取网页没啥好说的 2 header = { 3 "User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"} 4 html = requests.get(url=web_url, headers=header).text#不加text返回的是response,加了返回的是字符串 5 Soup = BeautifulSoup(html, "lxml") 6 data = Soup.find("ol").find_all("li") # 还是有一点要说,就是返回的信息最好只有你需要的那部分,所以这里进行了筛选 7 return data
requests.get()函数,会根据参数中url的链接,返回response对象
.text会将response对象转换成str类型
find_all()函数,会将html文本中的ol标签下的每一个li标签中的内容筛选出来
2、筛选出信息,保存进文本
1 def get_info(all_move): 2 f = open("F:\\Pythontest1\\douban.txt", "a") 3 4 for info in all_move: 5 # 排名 6 nums = info.find('em') 7 num = nums.get_text() 8 9 # 名字 10 names = info.find("span") # 名字比较简单 直接获取第一个span就是 11 name = names.get_text() 12 13 # 导演 14 charactors = info.find("p") # 这段信息中有太多非法符号你需要替换掉 15 charactor = charactors.get_text().replace(" ", "").replace("\n", "") # 使信息排列规律 16 charactor = charactor.replace("\xa0", "").replace("\xee", "").replace("\xf6", "").replace("\u0161", "").replace( 17 "\xf4", "").replace("\xfb", "").replace("\u2027", "").replace("\xe5", "") 18 19 # 评语 20 remarks = info.find_all("span", {"class": "inq"}) 21 if remarks: # 这个判断是因为有的电影没有评语,你需要做判断 22 remark = remarks[0].get_text().replace("\u22ef", "") 23 else: 24 remark = "此影片没有评价" 25 print(remarks) 26 27 # 评分 28 scores = info.find_all("span", {"class": "rating_num"}) 29 score = scores[0].get_text() 30 31 32 f.write(num + '、') 33 f.write(name + "\n") 34 f.write(charactor + "\n") 35 f.write(remark + "\n") 36 f.write(score) 37 f.write("\n\n") 38 39 f.close() # 记得关闭文件
注意爬取元素的时候,会有非法符号(因为这些符号的存在,会影响你写入文本中),所以需要将符号用replace函数替换
其余的部分就不做解释了~~
3、全部代码
1 from bs4 import BeautifulSoup 2 import requests 3 import os 4 5 6 def get_html(web_url): # 爬虫获取网页没啥好说的 7 header = { 8 "User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"} 9 html = requests.get(url=web_url, headers=header).text#不加text返回的是response,加了返回的是字符串 10 Soup = BeautifulSoup(html, "lxml") 11 data = Soup.find("ol").find_all("li") # 还是有一点要说,就是返回的信息最好只有你需要的那部分,所以这里进行了筛选 12 return data 13 14 15 def get_info(all_move): 16 f = open("F:\\Pythontest1\\douban.txt", "a") 17 18 for info in all_move: 19 # 排名 20 nums = info.find('em') 21 num = nums.get_text() 22 23 # 名字 24