- 数据来源: kaggle
- 分析工具:Python 3.6 & jupyter notebook
- 附上数据:链接: https://pan.baidu.com/s/1D7JNvHmqTIw0OoPXBWzWHA 提取码: hdtt
- 本篇分析比较基础,集中于清洗和可视化,后续可能会慢慢修改,如果我能想起来的话,欢迎各路大神指正
#设置jupyter可以打印多条结果
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
#导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
df=pd.read_csv('titanic_data.csv')
df.head()
# passengerId:旅客 id;survived:0 代表遇难,1 代表存活;pclass:舱位,1-3 分别代表一二三等舱;
# name:旅客姓名;sex:旅客性别;age:年龄;
# sibsp:船上的同代亲属人数,如兄弟姐妹;parch:船上的非同代亲属人数,如父母子女;
# ticket:船票编号;fare:船票价格;cabin:客舱号;embarked:登船港口
猜测生存率跟以下因素有关
1.pclass:客舱等级,一等舱可能有大部分权贵
2.sex:性别,lady first
3.age:年龄,尊老爱幼,通用的道德规范
4.sibsp:同代亲属,可能亲属多的获救概率更大
5.parch:非同代亲属,可能会让父母子女先得救
6.fare:船票价格,反应经济能力和社会地位,跟客舱等级存在关联
# 数据量以及大小,缺失值
df.info()
df.shape
- 结论:数据总量 891 条,12 列,age 列缺失 177 条数据,因为尊老爱幼也是一个通用的道德规范,因此考虑 age 对生存率会有影响,后续可能需要填充; cabin 舱号对生存考虑无影响,缺失影响不大
# 数据汇总统计
df.describe()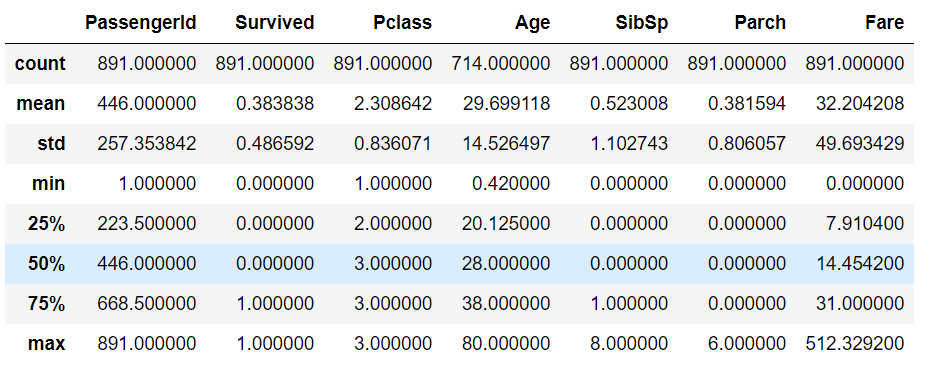
# 整体生存情况
survived=df['Survived'].value_counts()
survived
# 可以看到,891 人中,只有342人存活
# 计算生存比例
survived_perc=survived / survived.sum()
survived_perc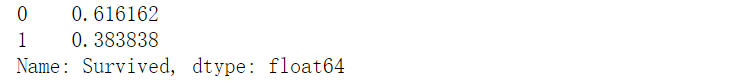
# 绘制饼图
plt.rc('font',family='Arial Unicode MS',size=15) #设置字体
fig=plt.figure(1,figsize=(7,7)) #设置画布
ax1=fig.add_subplot(1,1,1) #生成子图
label=['遇难','存活']
color=['#C0C0C0','#F5DEB3']
explode=0.05,0.05 #扇区间隔
ax1.pie(survived_perc,labels=label,colors=color,startangle=90,autopct='%3.2f%%',explode=explode,shadow=True)
ax1.set_title('整体生存情况') 
# 性别与生存情况
sex=df.groupby(['Survived','Sex']).size()
sex
# 转换为 dataframe
sex=sex.unstack('Sex')
sex=sex.rename(index={0:'遇难',1:'存活'})
sex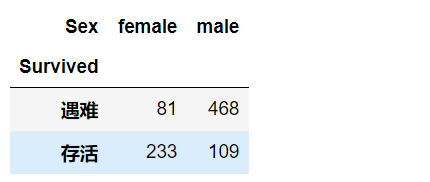
# 计算生存比例
sex_perc=sex / sex.sum()
sex_perc
- 从结果看,女性遇难 81 人,存活率约 75%,男性存活 109人,存活率不到 20%
# 绘制条形堆叠图
plt.rc('font',family='Arial Unicode MS',size=15) #设置字体
fig=plt.figure(1,figsize=(7,7)) #设置画布
ax1=fig.add_subplot(1,1,1) #生成子图
x=range(2)
a=sex_perc.loc['遇难',:]
b=sex_perc.loc['存活',:]
ax1.bar(x,a,label='遇难',color='#C0C0C0')
ax1.bar(x,b,bottom=a,label='存活',color='#F5DEB3') #通过bottom参数绘制堆积柱状图
ax1.set_xticks(range(3)) #设置x轴刻度,之所以设置为3,是为了让图例显示在空白处
ax1.set_xticklabels(['女性','男性']) #设置x轴刻度标签名称
ax1.set_yticks([])
ax1.legend(['遇难','存活'],loc='center right') #设置图例名称及位置
ax1.set_title('性别生存分布') #设置标题
#添加数据标签
for x,y,z in zip(range(2),a,b):
ax1.text(x,y/2,'{:.2%}'.format(y))
ax1.text(x,y+z/2,'{:.2%}'.format(z))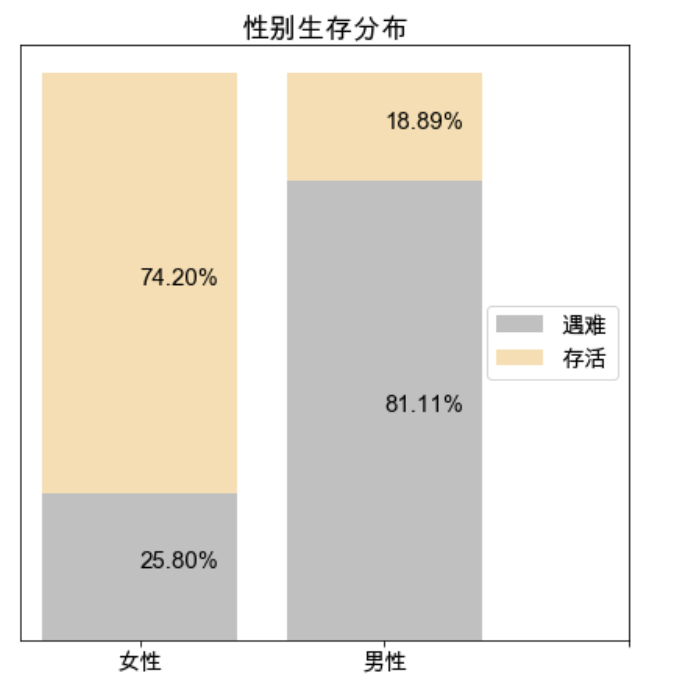
# 年龄分布
age_df=df.loc[:,['Survived','Age']]
age_df.head() 
#对年龄分组,从前面的描述性统计可以看到,年龄的最小值是0.42岁,最大值是80岁
bins=[0,20,40,60,100]
labels=['20岁及以下','21-40岁','41-60岁','60岁以上']
age_df['levels']=pd.cut(age_df['Age'],bins=bins,labels=labels)
age_df.head() 
# 遇难/存活人员的年龄分布
age_level=age_df.groupby(['Survived','levels']).size()
age_level 
# 可以看到在遇难和存活的人中,都是21-40岁的人巨多
# 转为 dataframe
age_level=age_level.unstack()
age_level=age_level.rename(index={0:'遇难',1:'存活'})
age_level 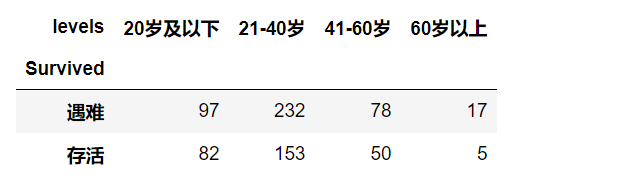
# 计算比例
age_perc=age_level/age_level.sum()
age_perc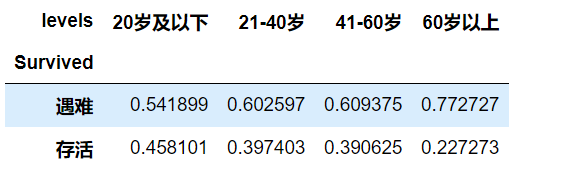
- 可以看到随着年龄的增加,存活比例逐渐降低,在天灾面前,大家还是会把生的希望更多的让给年轻人
plt.rc('font',family='Arial Unicode MS',size=15) #设置字体
fig=plt.figure(1,figsize=(11,7)) #设置画布
ax1=fig.add_subplot(1,1,1) #添加子图
x=range(4)
a=age_perc.loc['遇难',:]
b=age_perc.loc['存活',:]
ax1.bar(x,a,label='遇难',width=0.5,color='#C0C0C0')
ax1.bar(x,b,bot