一、索引原理
1,什么是索引?
索引在MySQL中也叫‘键’或者‘key’,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要,减少IO次数,加快查询。
2,索引的数据结构:b+树
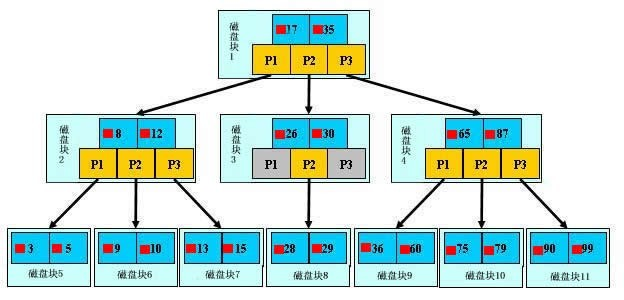
上图就是一个b+树的数据结构,我们的InnoDB索引的数据就是以这种结构存放的。比如说我们要查找29,首先会把磁盘块1加载到内存,发生一次IO,发现29在17和35 中间,就锁定磁盘块中的p2指向的磁盘模块3,然后把磁盘块3加载到内存,发生第二次IO,发现29在26和30之间,就锁定磁盘块3中p2指向的磁盘块8,然后把磁盘块8加载到内存,发生第三次IO,此时和29相比,有一值等于29,从而就找到了29。这样的b+树可以表示上百万的数据,如果上百万的数据查找也只需要三次IO,那么性能提高是非常大的,如果没有索引,每次数据项都要发生一次IO,总共需要上百万次的IO,得花多少时间。
3,b+树的性质
3.1 索引字段要尽量的小
通过上面的例子来看,基本上是b+树的层级高度决定了IO的次数,也决定了查询的效率,所以,要提高效率就应该减少b+树的高度。对于每个磁盘块所能存放的数据量是有限的。假设当前的所有数据大小为N,每个磁盘能存放某个数据的个数为m=磁盘块的大小/每个数据的大小,则高度为h=log(m+1)N,当数据一定时,m越大,h就越小。说明每个数据越小,高度越低,IO次数就越少,效率就更高。所以我们在建立索引的时候喜欢用id字段,而不是name字段,数字类型肯定比char类型占的空间小嘛。
3.2 索引的最左匹配原则特性
查询数据是从数据块的左边开始匹配,再匹配右边的。
二、聚集索引与辅助索引
数据库中的b+树索引可以分为聚集索引和辅助索引
相同点:其内部都是b+树的形式,叶子节点都存放着数据
不同点:聚集索引存放的是一整行所有数据,而辅助索引只存放索引字段的数据+主键
1,聚集索引
#InnoDB存储引擎表示索引组织表,即表中数据按照主键顺序存放。而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。
同B+树数据结构一样,每个数据页都通过一个双向链表来进行链接。 #如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。 #如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。 #由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。在多少情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。此外由于定义了数据的逻辑顺序,聚集索引能够特别快地访问针对范围值得查询。
它对主键的排序和范围查找熟读非常的快,叶子节点的数据就是用户所要查询的数据,如用户需要查找一张表,查询最后的10位用户信息,由于b+树索引是双向链表,所以用户可以快速查找到最后一个数据夜,并取出10条数据。


#参照第六小结测试索引的准备阶段来创建出表s1 mysql> desc s1; #最开始没有主键 +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ rows in set (0.00 sec) mysql> explain select * from s1 order by id desc limit 10; #Using filesort,需要二次排序 +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2633472 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ row in set, 1 warning (0.11 sec) mysql> alter table s1 add primary key(id); #添加主键 Query OK, 0 rows affected (13.37 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 order by id desc limit 10; #基于主键的聚集索引在创建完毕后就已经完成了排序,无需二次排序 +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | 1 | SIMPLE | s1 | NULL | index | NULL | PRIMARY | 4 | NULL | 10 | 100.00 | NULL | +----+-------------+-------+---