文件读取与异常
文件读取与判断
os模块是调用来处理文件的。
先从最原始的读取txt文件开始吧!
新建一个aaa.txt文档,键入如下英文名篇:
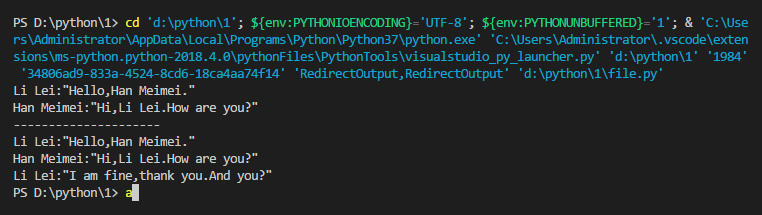
Li Lei:"Hello,Han Meimei."
Han Meimei:"Hi,Li Lei.How are you?"
Li Lei:"I am fine,thank you.And you?"同目录下创建一个新的file.py文档
import os
os.getcwd()
data=open('aaa.txt')
# 打开文件
print(data.readline(),end='')
# 读取文件
print(data.readline(), end='')
data.seek(0)
# 又回到最初的起点
for line in data:
print(line,end='')结果如下
如果文件不存在怎么办?
import os
if os.path.exists('aaa.txt'):
# 业务代码
else:
print('error:the file is not existed.')split切分
现在我们要把这个桥段转化为第三人称的形式
for line in data:
(role,spoken)=line.split(':')
print(role,end='')
print(' said:',end='')
print(spoken,end='')这里是个极其简单对话区分。如果我把对话稍微复杂点
。。。
Han Meimei:"There is a question:shall we go to the bed together?"
(pause)
Li Lei:"Oh,let us go to the bed together!"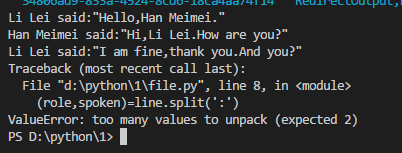
关键时刻岂可报错。
首先发现问题出在冒号,split方法允许第二个参数.
以下实例展示了split()函数的使用方法:
#!/usr/bin/python str = "Line1-abcdef \nLine2-abc \nLine4-abcd"; print str.split( ); print str.split(' ', 1 );以上实例输出结果如下:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd'] ['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
data = open('aaa.txt')
# 打开文件
for line in data:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')取反:not
结果pause解析不了。每一行做多一个判断。取反用的是not方法,查找用的是find方法。
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
find()方法语法:
str.find(str, beg=0, end=len(string))
考虑这样写
for line in data:
if not line.find(':')==-1:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
data.close()关注代码本身的目的功能:try...except...捕获处理异常
剧本里的对话千差万别,而我只想要人物的对话。不断增加代码复杂度是绝对不明智的。
python遇到代码错误会以traceback方式告诉你大概出了什么错,并中断处理流程(程序崩了!)。
而try...except...类似try...catch语法,允许代码中的错误发生,不中断业务流程。
在上述业务代码中我想统一忽略掉所有
只显示
木有冒号的文本行
可以 这么写:
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except:
passpass是python中的null语句,理解为啥也不做。
通过这个语法,忽略处理掉了所有不必要的复杂逻辑。
复杂系统中,aaa.txt可能是不存在的,你固然可以用if读取,还有一个更激进(先进)的写法:
import os
try:
data = open('aaa.txt')
# 打开文件
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except:
pass
except:
print('error:could not read the file.')两种逻辑是不一样的,上述是无法读取(可能读取出错),if是路径不存在。于是引发了最后一个问题。
错误类型指定
过于一般化的代码,总是不能很好地判断就是是哪出了错。try语句无法判断:究竟是文件路径不对还是别的问题
import os
try:
data = open('aaa.txt')
# 打开文件
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except ValueError:
# 参数出错
pass
except IOError:
# 输入输出出错
print('error:could not find the file.')python中异常对象有很多,可自行查阅。
数据不符合期望格式:ValueError
IOError:路径出错
数据储存到文件
业务代码工作流程可以储存到文件中保存下来。下面先看一个需求:
- 分别创建一个名为lilei和hanmeimei的空列表
- 删除一个line里面的换行符(replace方法和js中几乎一样。去除左右空格用
strip方法)- 给出条件和代码,根据role的值将line添加到适当的列表中
- 输出各自列表。
简单说就是一个条件查询的实现。
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.replace('\n', '')
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError: