一、什么是关系?
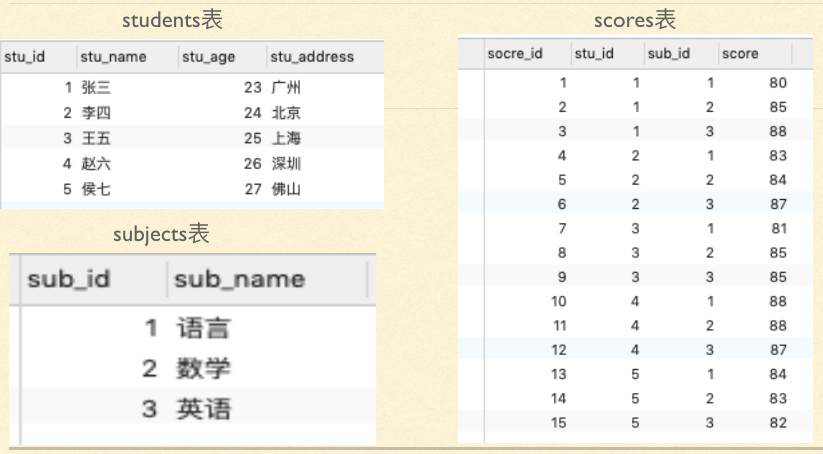
1、分析:有这么一组数据关于学生的数据
学号、姓名、年龄、住址、成绩、学科、学科(语文、数学、英语)
我们应该怎么去设计储存这些数据呢?
2、先考虑第一范式:列不可在拆分原则
这里面学科包含了三个学科,所以学科拆分为:语文学科、数学学科、英语学科,同样的成绩也要拆分为语文成绩、数学成绩、英语成绩。这样既满足了第一范式,各列可以设计为:
学号、姓名、年龄、住址、语文学科、数学学科、英语学科、语文成绩、数学成绩、英语成绩
3、在考虑第二范式:唯一标识
也就是说在1NF的基础上,非Key属性必须完全依赖于主键,第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。即确定主键,我们可以选取学号为主键
4、接着在考虑第三范式:
确保表中各列与主键列直接相关,而不是间接相关。即各列与主键列都是一种直接依赖关系,则满足第三范式。
不难发现在这么多列中,年龄、住址和成绩、学科没有直接关系,也就是说我考多少分,和年龄及住址都无关,他们都是学生的信息,但都是不相关的信息,所以根据第三范式,我们需要将这些数据根据其相关性拆分为多个表。

5、表与表之间的关系
如果我们要想找到张三的语文成绩,那么我们就必须去成绩表中查找,因为成绩表中保存的所有人的所有学科成绩。但是在成绩表中查找的时候,需要从省标中查到张三的学号(stu_id)和从学科表中查到语文学科(sub_id)的编号,这个时候这三张表就发生了关系,这也就是关系型数据库的精髓,而根据这种表与表之间的关系也会衍生出很多的查询的高级操作
二、外键(foreign key)
外键约束:用于限制主表与从表数据完整性。
alter table scores add constraint 'stu_score_fk' foreign key(stu_id) references students(stu_id);
- 将scores表的stu_id外键关联到students表的stu_id字段(说明:这里scores表里面字段stu_id和students表里的stu_id重名了,最好避免重名)
- 每个外键都有一个名字,可以通过constraint指定
- 存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
- 作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。例如,此时在从表插入或者修改数据时,如果stu_id的值在students表中不存在则会报错
- 外键也可以在创建表时可以直接创建约束
语法:
foreign key (外键字段) references 主表名 (关联字段)
例如:
create table scores( id int primary key auto_increment, stu_id int, sub_id int, score decimal(5,2), foreign key(stuid) references students(id), foreign key(subid) references subjects(id) );
[主表记录删除时的动作] [主表记录更新时的动作],此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
三、外键的级联操作
- 在删除或者修改students表的数据时,如果这个stu_id值在scores中已经存在,则会抛异常
- 推荐使用逻辑删除,还可以解决这个问题
- 可以创建表时指定级联操作,也可以在创建表后再修改外键的级联操作
alter table scores add constraint stu_sco foreign key(stu_id) references students(stu_id) on delete cascade;
除了on delete还有on update都要注意级联操作
级联操作的类型包括:
- restrict(限制):默认值,抛异常,拒绝父表删除或者更新
- cascade(级联):如果主表的记录删掉,则从表中相关联的记录都将被删除,如果主表修改记录,则从表记录也将被修改
- set null:将外键设置为空
- no action:什么都不做
四、链接查询
在讲解第一个问题关系的时候,我们提到了,如果要查找张三的语文成绩,需要用到三个表,当我们查询结果来源于多张表的时候就需要使用连接查询
链接查询关键:找到表间的关系,当前的关系是
- students表的stu_id---scores表的stu_id
- subjects表的sub_id---scores表的sub_id
select students.stu_name,subjects.sub_name,scores.score from scores inner join students on scores.stu_id=students.stu_id inner join subjects on scores.sub_id=subjects.sub_id where students.stu_name='张三' and subjects.sub_name='语文';
+----------+----------+-------+
| stu_name | sub_name | score |
+----------+----------+-------+
| 张三 | 语文 | 80 |
+----------+----------+-------+
- 结论:当需要对有关系的多张表进行查询时,需要使用连接join 连接查询分类如下:
- 表A inner join 表B:表A与表B匹配的行会出现在结果中
- 表A left join 表B:表A与表B匹配的行会出现在结果中,外加表A中独有的数据,未对应的数据使用null填充
- 表A right join 表B:表A与表B匹配的行会出现在结果中,外加表B中独有的数据,未对应的数据使用null填充
- 在查询或条件中推荐使用“表名.列名”的语法
- 如果多个表中列名不重复可以省略“表名.”部分
- 如果表的名称太长,可以在表名后面使用' as 简写名'或' 简写名',为表起个临时的简写名称
五、视图
视图就像我们python里面的函数一样,对SQL语言代码块的封装
-
- 对于复杂的查询,在多次使用后,维护是一件非常麻烦的事情
- 解决:定义视图
- 视图本质就是对查询的一个封装
- 定义视图
create view stuscore as select students.stu_name,subjects.sub_name,scores.score from scores inner join students on scores.stu_id=students.stu_id inner join subjects on scores.sub_id=subjects.sub_id;
这句话的意思就是用stuscore就相当于后面红色很长的一段SQL语句:
mysql> select *from stuscore; +----------+----------+-------+ | stu_n