半自动化给PDF加书签-Python实现-上篇
使用介绍
Github:https://github.com/Davy-Zhou/pdf_add_bookmark_semi
一、PDF加书签介绍
1.1 不那么漂亮的话
- 本工具只进行书签部分格式化和加书签操作,书签获取需要配合其它工具
- 最终书签效果因人而异,程序只能格式化最常见的层级,毕竟是半自动的
- 最好了解一定正则和列操作,不了解的话可能要多手工重复一些操作
- 相比现有工具,书签获取自动化,可自动识别部分PDF页偏移?
- 反反复复改了一星期,差不多能用了,虽然代码依然很烂
1.2 PDF加书签难点
1.2.1 书签获取
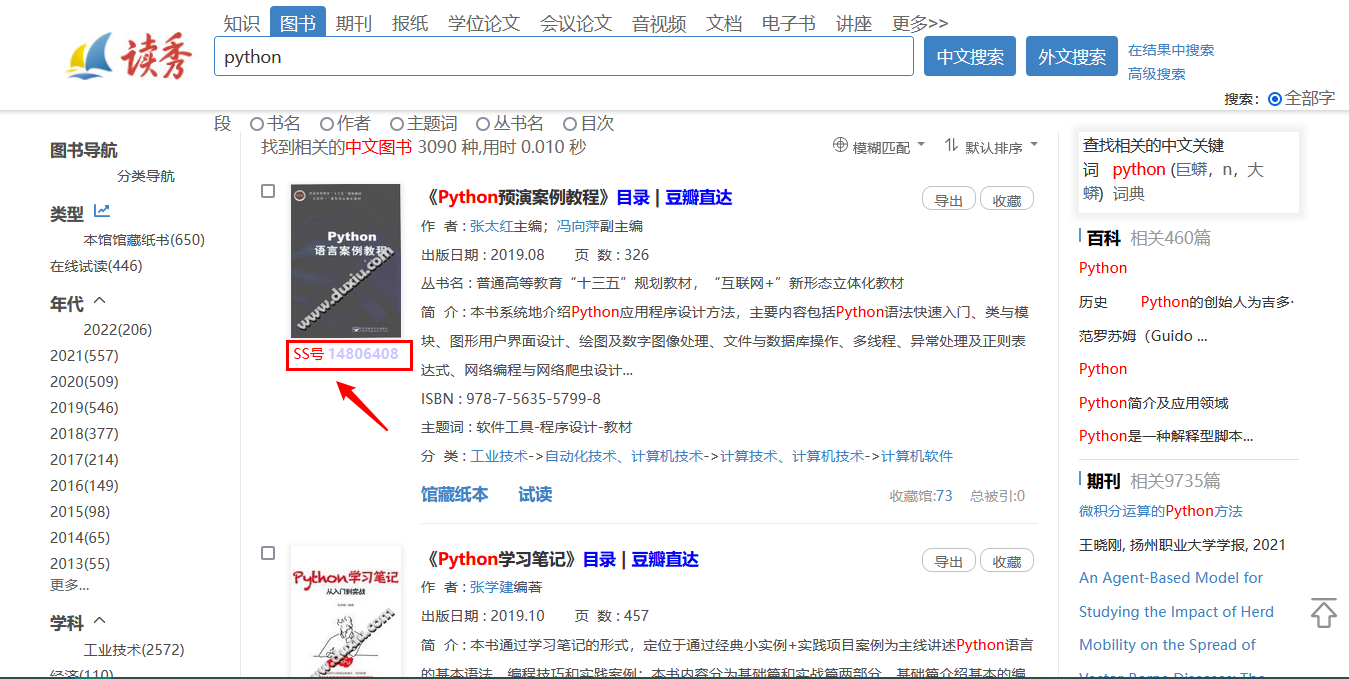
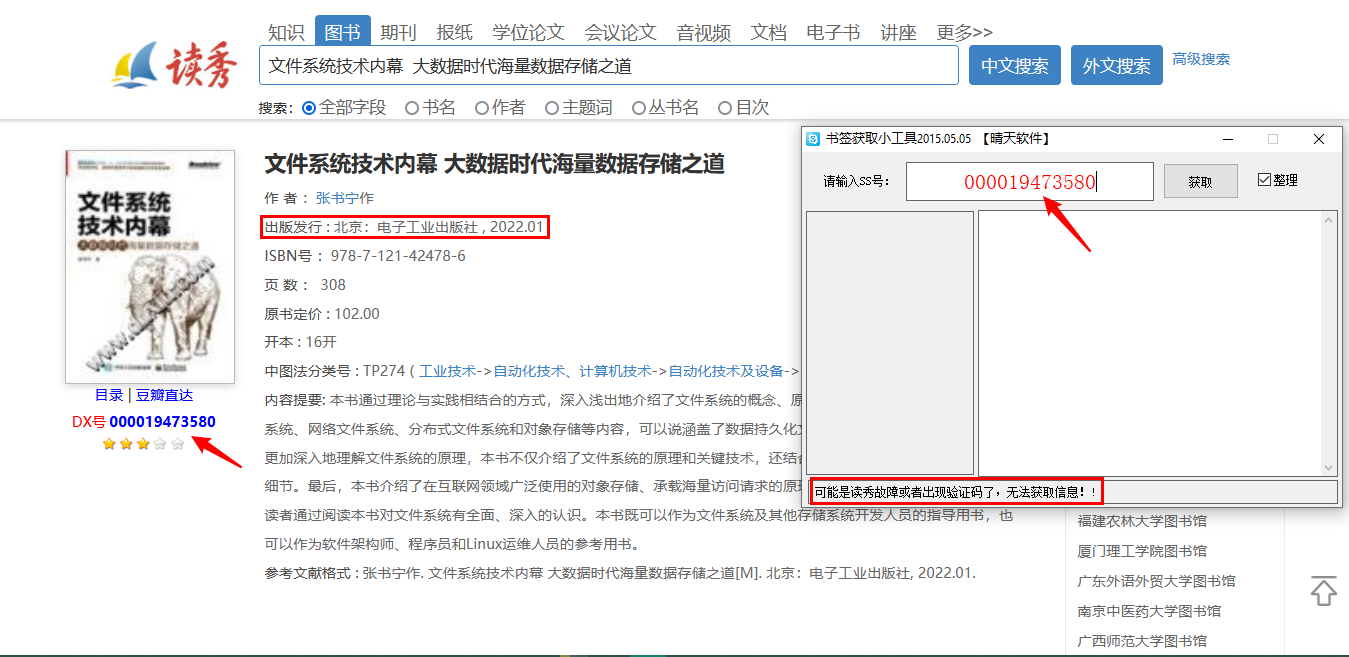
一般需要加书签的,大多是扫描版书籍,而市面上绝大多数扫描版书籍均出自超星公司(读秀和全国图书参考联盟都是他家的),为了方便学术检索,超星有对目录进行提取,如下图。
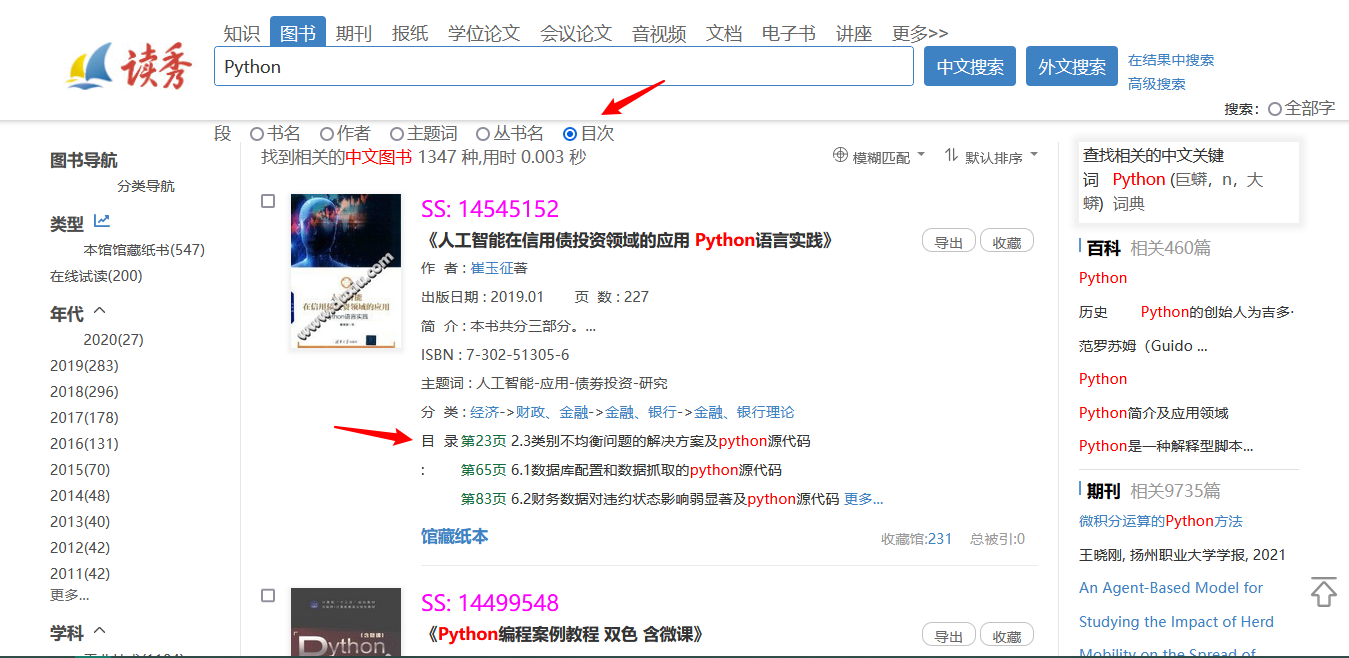
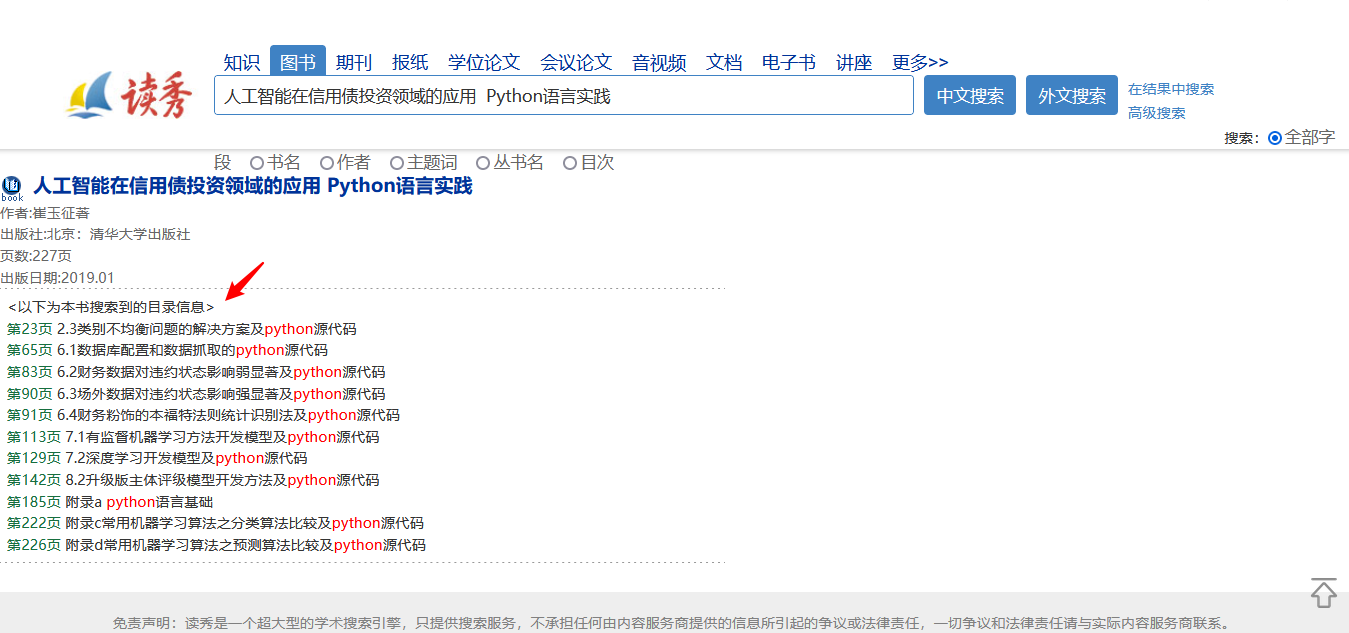

? 额,然后有人分析出了超星书签的接口,做成了书签获取工具,如下图,通过它能获取大多数书的书签。

但检索一本书的书签,需要知道书在超星的内部编号,上图书签获取工具填的就是那个编号
-
SSID( Super Star ID,超星英文简写)
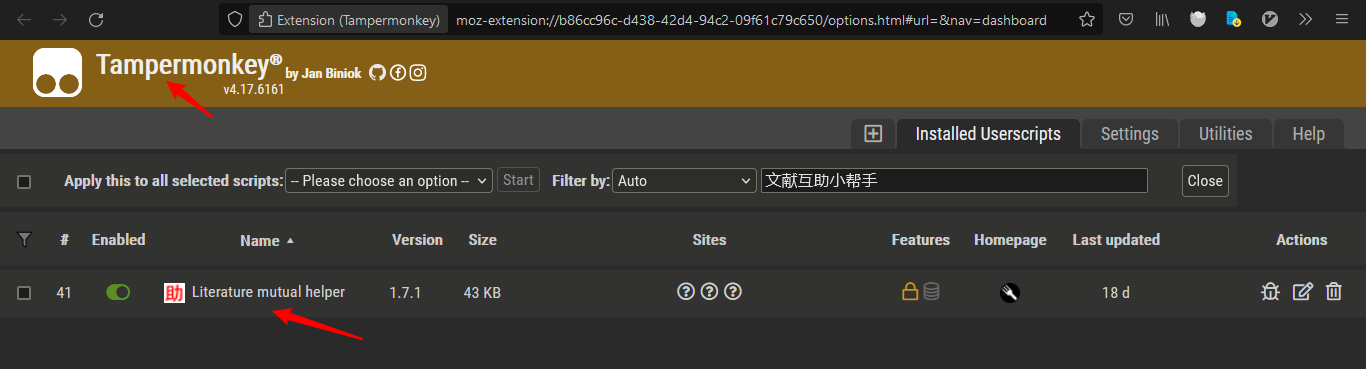
书签接口是超星开发的,其中检索每本书的书签不是通过ISBN或书名,而是其内部定义的编号SSID,这个SSID可以油猴脚本获取,推荐文献互助小帮手这个脚本,读秀和全国图书参考联盟都可以获取SSID,但在装油猴脚本前需要装油猴插件
装好的油猴插件、油猴脚本
如果书签工具也没有那本书的书签,怎么办?
- 这篇博客 下载超星或读秀图书时,怎么搞定完整书签? 讲的可以,不重复了,主要是在
各出版社官网,电商网站,豆瓣找,直接Google书签里面的内容,层级深一点的那个,实在没有就OCR书里面的目录部分再整理
推荐阅读,上面的内容主要参考这三篇文章
- 文献互助小帮手:https://greasyfork.org/zh-CN/scripts/435569-文献互助小帮手-从图书馆参考咨询联盟-ucdrs-或读秀-duxiu-获取ssid-dxid-从中美百万-cadal-获取ssno-提供ucdrs-duxiu-cadal到豆瓣图书的链接
- 淘宝书商为啥什么书都能找到:揭秘代找PDF背后的真相 :https://mp.weixin.qq.com/s/7SX-Oztgx2q76AN5YpntTA
- 下载超星或读秀图书时,怎么搞定完整书签? :https://blog.csdn.net/youthlzu/article/details/24514703
1.2.2 书签格式化
? 最初获取的书签结构化程度,很大程度决定了后期格式化用的时间。根据经验,书签格式化有三个小点,书签层级、每级书签样式和页码偏移。
-
书签层级
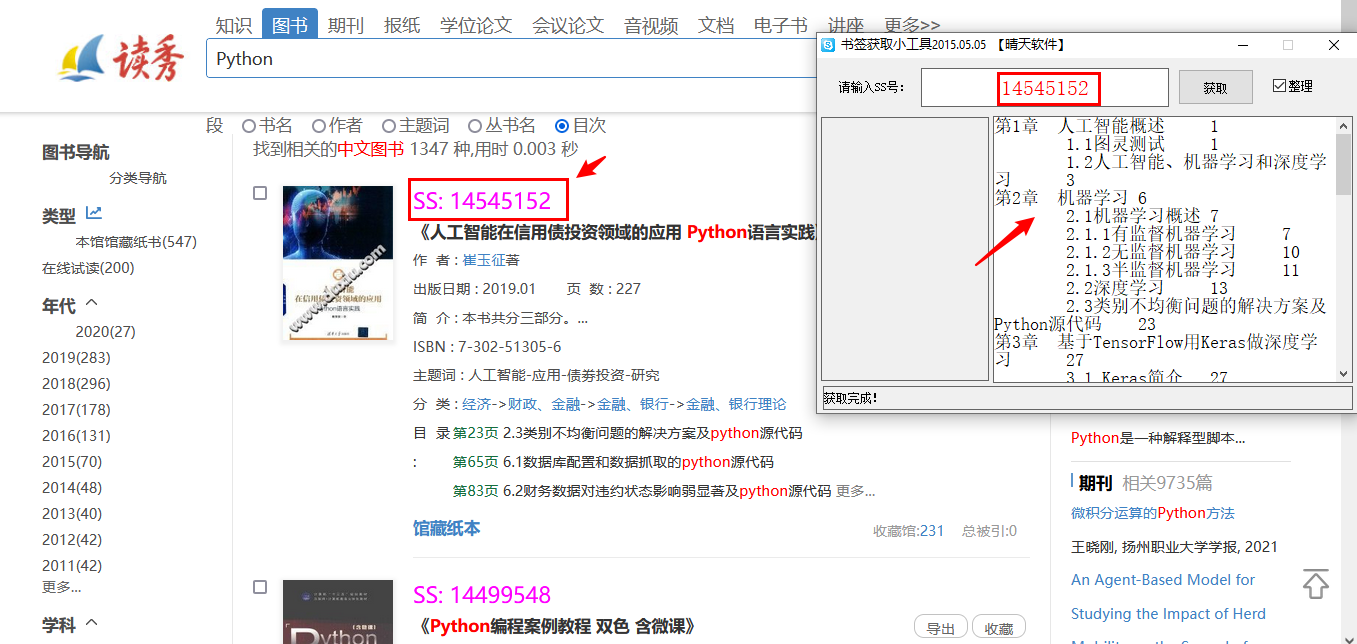
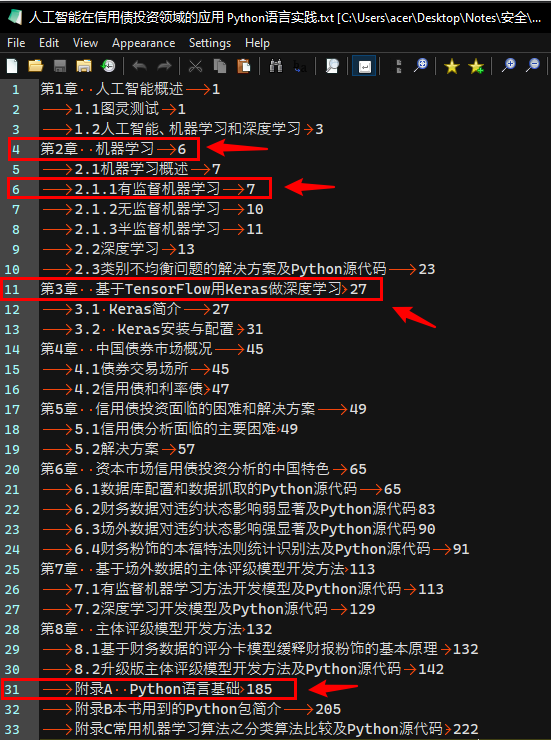
? 以《人工智能在信用债投资领域的应用 Python语言实践》(SSID: 14545152)这本书为例,见下图,这是从
书签获取小工具2015.05.05【晴天软件】获得的初步整理的书签。另外规定对于书签的层级一律以Tab来区分,一级书签前面没有Tab,二级书签前面有1个Tab,三级书签则有2个Tab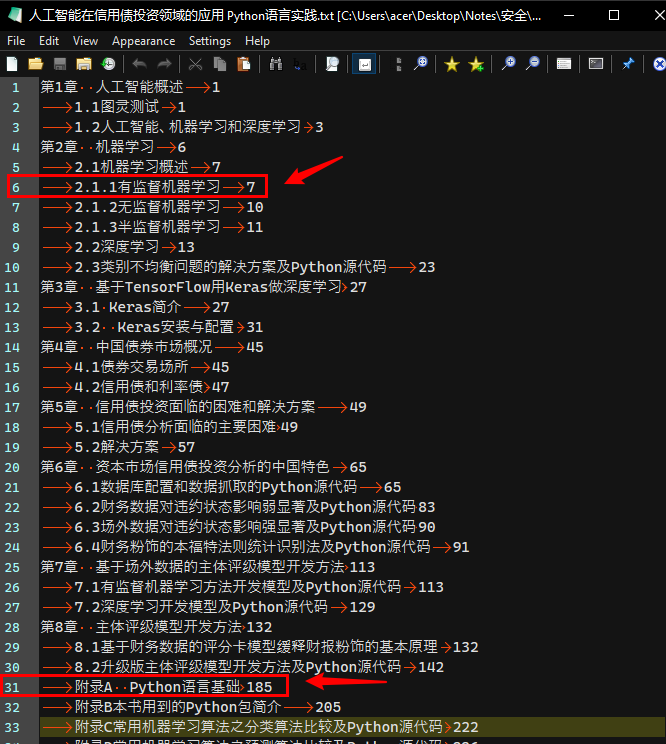
? 从中可以看出,除对一级书签(即按章开头的那个第*章),其它书签均格式化为二级书签,其中标注的第6行和第31行应分别为三级书签和一级书签,如下图为修正好的书签
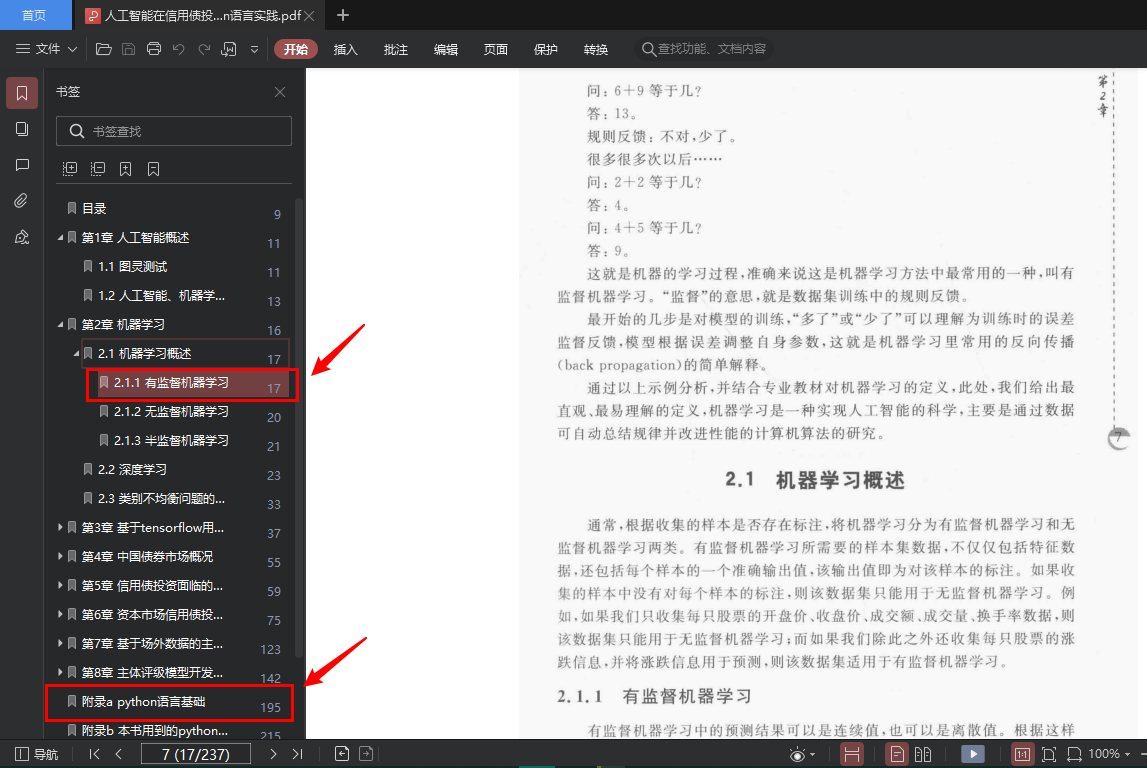
-
每级书签样式
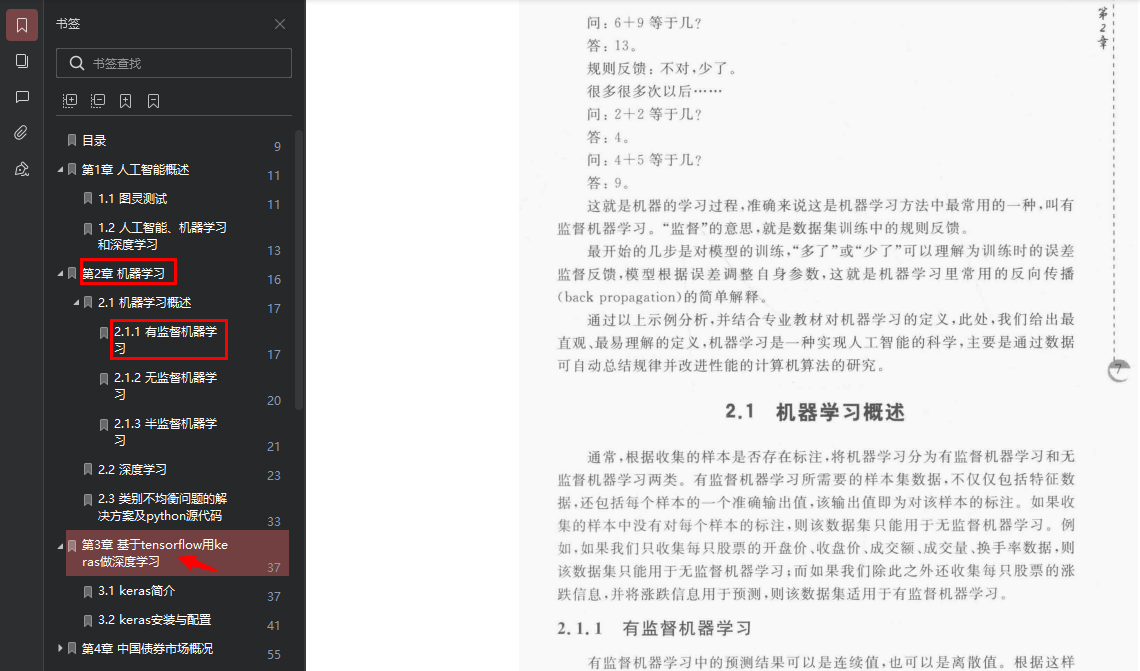
? 还是以同一本书为例看书签样式问题,注意第4行,
第2章 机器学习,标号与标题中间有两个空格;第6行,2.1.1有监督机器学习,标号与标题中间则没有空格;第11行,第3章 基于TensorFlow用Keras做深度学习,里面的英文单词是应该首字母大写还是按原样输出,后面的附录那节同第一个问题。? 这个按照每个人的审美不同,具体怎么弄,得看你们自己的选择
? 个人的审美是,标号与标题之间只留一个空格,英文单词全部统一成小写,虽然按原样输出就挺不错的,但加了这么多PDF的书签,最终还是选择统一单词的风格,结果如下图
-
页码偏移
? 超星的书签应该也是从目录这部分OCR提取的,见下图,但其中的页码和实际的页码有偏移(因为目录里面的页码是从正文开始算的,而实际的书签引用页码必须是从第一开始的绝对页码),第二章在目录里是页码是
6,而实际绝对页码是16,二者相差10,加书签时必须补上这个页码,见第二张图。
? 所有正文之后的页码必须
+10进行修正,如下图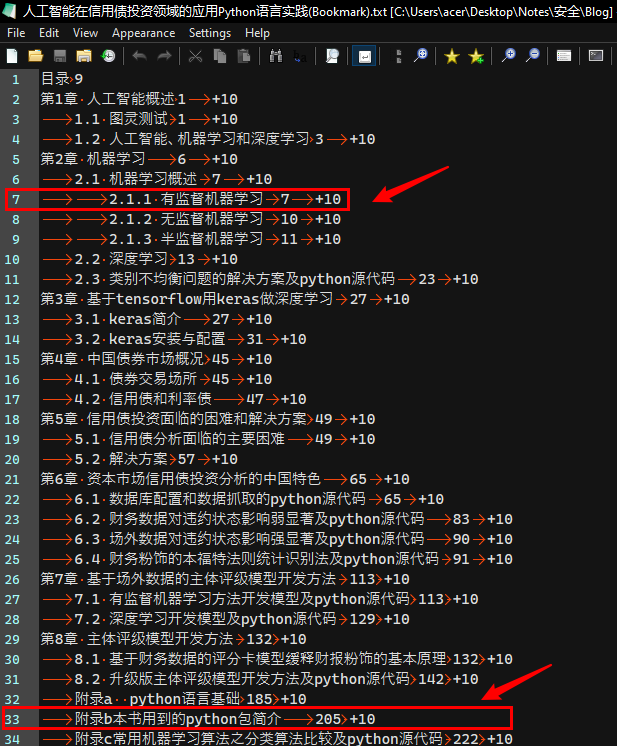
1.3 工具使用限制
? 在最开始已经介绍,本工具只能进行书签部分格式化,还有一部分是需要手工操作的,特别是对于从非书签获取小工具2015.05.05【晴天软件】获得的书签,程序处理会有很大问题,,,
-
从
书签获取小工具2015.05.05【晴天软件】获取书签? 如下图红框,书签层级是通过数字标号来定位的,但如下图框中,书签部分前面没有标号,所以没办法分层级。最后的处理办法是对所有不能通过其特定标识分层级的,全部默认分到二级书签。之后就得自己去修正正确的层级。

-
从其它处获得的书签
? 如下图,一些新书是没有录入库的,只能从其它地方拿书签了。
? 下面是从京东商城的商品界面,可以看到目录,
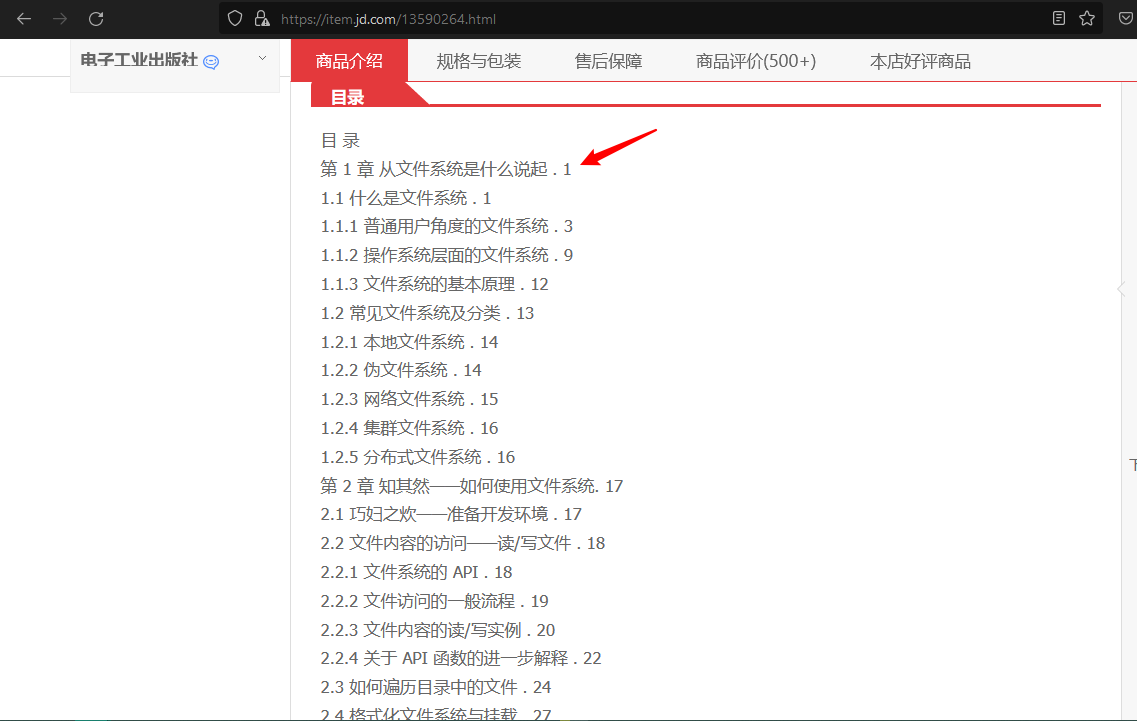
? 复制到TXT文档里面,可以发现其中标签与页码之间有
点符号,另外还有空行,如果需要用这个书签的话,这个需要把里面的点符号还有空行删了,这个需要用到正则表达式进行替换,不过注意别把书签的数字标号之间的点删除了。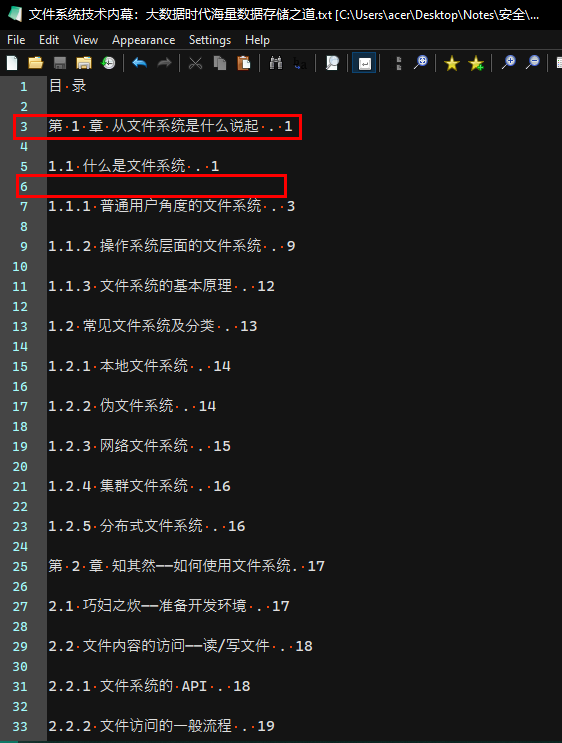
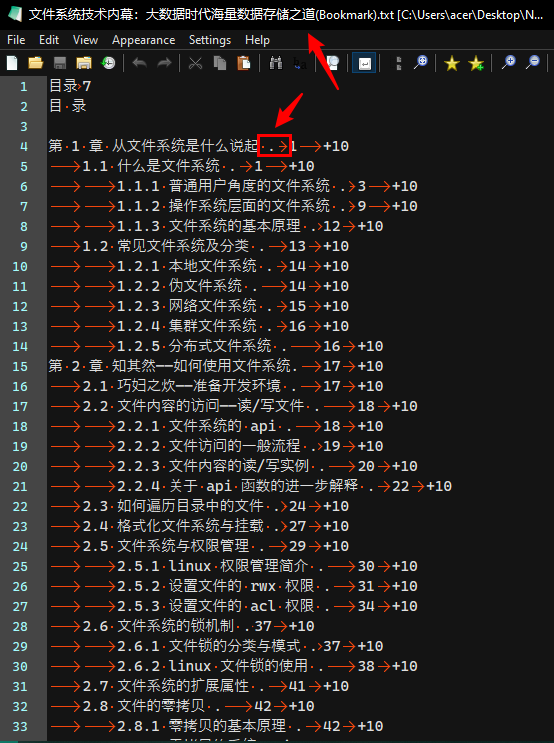
? 试着把这个txt格式化一下,如图,箭头所指的点没删除,后面有时间再优化这个问题了。
二、使用方式
2.1 工具介绍
-
工具结构
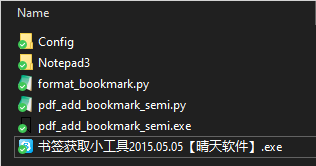
#目录树 . ├── Config │ └── config.yaml #配置文件 ├── Notepad3 │ ├── Notepad3.exe #协同工具-文本编辑器 │ ├── Notepad3.ini │ └── lng │ ├── np3lng.dll │ └── zh-CN │ └── np3lng.dll.mui ├── format_bookmark.py #代码-格式化书签 ├── pdf_add_bookmark_semi.exe #代码-打包的exe ├── pdf_add_bookmark_semi.py #代码-加书签 └── 书签获取小工具2015.05.05【晴天软件】.exe #协同工具-书签获取工具主要是三部分:代码(
format_bookmark.py、pdf_add_bookmark_semi.py、pdf_add_bookmark_semi.exe)、配置文件(Config/config.yaml)