
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为网页解析库的使用。
概述
前几期的文章中讲到了网络请求库的使用,我们已经能够使用各种库对目标网址发起请求,并获取响应信息。本期我们会介绍各网页解析库的使用,讲解如何解析响应信息,提取所需数据。
XPath的使用
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。同样,XPath 也支持HTML文档的解析。
介绍
XPath 使用路径表达式来匹配HTML文档中的节点或节点集,路径表达式基于HTML文档树,因此在学习XPath 时需要对网页结构有一个初步了解,关于网页结构这些在之前的文章《网页基本结构》中已经介绍到了。
安装
使用XPath 需要安装Python的第三方库lxml,可以使用命令pip install lxml进行安装
使用
下文中,我们会通过一个示例来了解xpath的用法。
<div id="box">
<p name="test">这是一个测试网页1</p>
</div>
<p name="test">这是一个测试网页2</p>
<div id="city">
<ul>
<li id="u1">北京</li>
<li id="u2">上海</li>
<li id="u3">广州</li>
<li id="u4"><a name="sz" href="sz.html" target="_self">深圳</a></li>
</ul>
</div>
<div class="article"><h3>标题</h3></div>
<div class="article"><p>内容1</p></div>
<div class="article"><p>内容2</p></div>
<div class="article"><p>内容3</p></div>
这是一个简单的网页body结构。我们想要提取页面中的信息,就需要先分析它的结构,理清结构后,编写路径表达式就会更加方便。
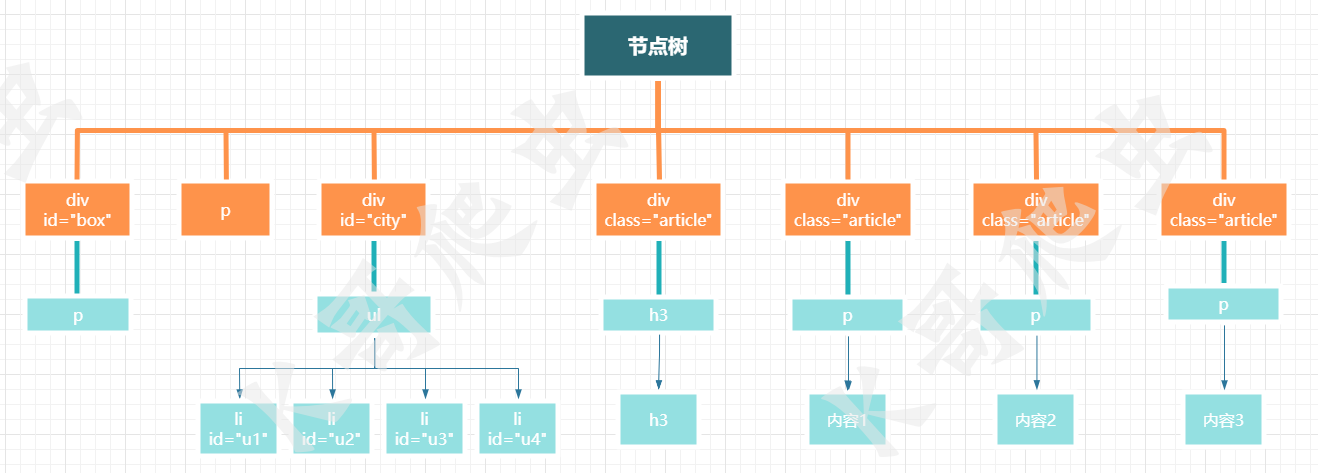
在前文对xpath的介绍中我们了解到xpath是对XML或HTML文档进行解析的功能,但在代码中,示例中的html文本只是一段字符串,所以在使用xpath进行匹配前首先要将字符串转成HTML对象。
from lxml import etree
element = '''
<div id="box">
<p name="test">这是一个测试网页1</p>
</div>
<p name="test">这是一个测试网页2</p>
<div id="city">
<ul>
<li id="u1">北京</li>
<li id="u2">上海</li>
<li id="u3">广州</li>
<li id="u4"><a name="sz" href="sz.html" target="_self">深圳</a></li>
</ul>
</div>
<div class="article"><h3>标题</h3></div>
<div class="article"><p>内容1</p></div>
<div class="article"><p>内容2</p></div>
<div class="article"><p>内容3</p></div>
'''
html = etree.HTML(element)
print(html)
#输出:<Element html at 0x1b642114388>
将文本转化为html对象后,就可以使用xpath进行匹配了。
路径表达式
| 表达式 | 描述 | 示例 | 示例描述 |
|---|---|---|---|
| nodename | 选取此节点下的所有子节点 | head | 获取当前head节点下的所有子节点 |
| / | 从根节点选取 | /html/head | 从根节点匹配head节点 |
| // | 从任意位置匹配节点 | //head | 匹配任意head节点 |
| . | 选取当前节点 | ||
| .. | 选取当前节点的父节点 | //head/.. | 匹配head节点的父节点 |
| @ | 选取属性 | //div[@id="box"] | 匹配任意id值为box的div标签 |
选取节点
以示例代码为例,我们想要匹配所有的li标签,可以这样实现:
html.xpath("//li")
#输出 [<Element li at 0x24c09d3e5c8>, <Element li at 0x24c09d3e588>, <Element li at 0x24c09d3e648>, <Element li at 0x24c09d3e688>]
谓语
获取id属性值为box的div标签信息
html.xpath('//div[@id="box"]')
#输出 [<Element div at 0x127672dc688>]
获取所有class属性值为article的标签信息
html.xpath('//*[@class="article"]')
#输出 [<Element div at 0x2898696e4c8>, <Element div at 0x2898696e588>, <Element div a