首先声明,本文参照(7条消息) 【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第三周作业_何宽的博客-CSDN博客_吴恩达课后编程作业(https://blog.csdn.net/u013733326/article/details/79702148)
本文所使用的资料已上传到百度网盘**【点击下载】**,提取码:qifu,请在开始之前下载好所需资料。当然还是需要将数据集放置在与代码同一层次。
加上自己的理解,方便自己以后的学习
我们需要准备一些软件包:
import numpy as np import matplotlib.pyplot as plt from testCases import * import sklearn import sklearn.datasets import sklearn.linear_model from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets np.random.seed(1) #设置一个固定的随机种子,以保证接下来的步骤中我们的结果是一致的(所取的随机值是一样的)。
我们来看看我们将要使用的数据集, 下面的代码会将一个花的图案的2类数据集加载到变量X和Y中
X, Y = load_planar_dataset()
plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral) #绘制散点图 plt.show()

数据看起来像一朵红色(y = 0)和一些蓝色(y = 1)的数据点的花朵的图案。 我们的目标是建立一个模型来适应这些数据。现在,我们已经有了以下的东西:
X:一个numpy的矩阵,包含了这些数据点的数值
Y:一个numpy的向量,对应着的是X的标签【0 | 1】(红色:0 , 蓝色 :1)
我们继续来仔细地看数据:
shape_X = X.shape shape_Y = Y.shape m = Y.shape[1] # 训练集里面的数量 print ("X的维度为: " + str(shape_X)) print ("Y的维度为: " + str(shape_Y)) print ("数据集里面的数据有:" + str(m) + " 个")
X的维度为: (2, 400) Y的维度为: (1, 400) 数据集里面的数据有:400 个
在构建完整的神经网络之前,先让我们看看逻辑回归在这个问题上的表现如何,我们可以使用sklearn的内置函数来做到这一点, 运行下面的代码来训练数据集上的逻辑回归分类器。
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X.T,Y.T)
会打印出这样一段字:
E:\anaconda\lib\site-packages\sklearn\utils\validation.py:993: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True)
#原型plot_decision_boundary(modle,x,y)对x进行预测,大于0.5取红色,小于0.5取蓝色 plot_decision_boundary(lambda x: clf.predict(x), X, Y) #绘制决策边界 plt.title("Logistic Regression") #图标题 LR_predictions = clf.predict(X.T) #预测结果 #Y的取值只有(0,1)所以这里要用“+” print ("逻辑回归的准确性: %d " % float((np.dot(Y, LR_predictions) + np.dot(1 - Y,1 - LR_predictions)) / float(Y.size) * 100) + "% " + "(正确标记的数据点所占的百分比)")
逻辑回归的准确性: 47 % (正确标记的数据点所占的百分比)

准确性只有47%的原因是数据集不是线性可分的,所以逻辑回归表现不佳,现在我们正式开始构建神经网络。(跟没分类一样,50%是最不好的分类情况)
搭建神经网络
隐藏层我们采取的是tanh函数,其导数为1-(tanh)^2

对于x(i)而言
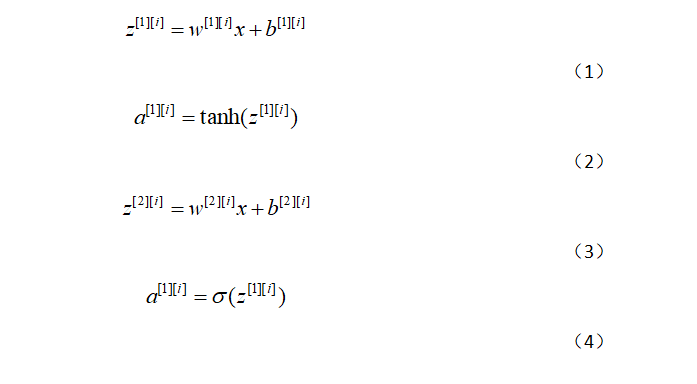
给出所有示例的预测结果,可以按如下方式计算成本J:

构建神经网络的一般方法是:
- 定义神经网络结构(输入单元的数量,隐藏单元的数量等)。
- 初始化模型的参数
- 循环:
- 实施前向传播
- 计算损失
- 实现向后传播
- 更新参数(梯度下降)
??我们要它们合并到一个nn_model() 函数中,当我们构建好了nn_model()并学习了正确的参数,我们就可以预测新的数据。
- n_x: 输入层的数量
- n_h: 隐藏层的数量(这里设置为4)当然可以设置为其他
- n_y: 输出层的数量
def layer_sizes(X , Y): """ 参数: X - 输入数据集,维度为(输入的数量,训练/测试的数量) Y - 标签,维度为(输出的数量,训练/测试数量) 返回: n_x - 输入层的数量 n_h - 隐藏层的数量 n_y - 输出层的数量 """ n_x = X.shape[0] #输入层 n_h = 4 #,隐藏层,硬编码为4 n_y = Y.shape[0] #输出层 return (n_x,n_h,n_y)
接下来,我们测试一下
#测试layer_sizes print("=========================测试layer_sizes=========================") X_asses , Y_asses = layer_sizes_test_case() (n_x,n_h,n_y) = layer_sizes(X_asses,Y_asses) print("输入层的节点数量为: n_x = " + str(n_x)) print("隐藏层的节点数量为: n_h = " + str(n_h)) print("输出层的节点数量为: n_y = " + str(n_y))
=========================测试layer_sizes========================= 输入层的节点数量为: n_x = 5 隐藏层的节点数量为: n_h = 4 输出层的节点数量为: n_y = 2
初始化模型的参数
在这里,我们要实现函数initialize_parameters()。我们要确保我们的参数大小合适,如果需要的话,请参考上面的神经网络图。
我们将会用随机值初始化权重矩阵。
- np.