符串(本质上是一个字节数组),那么就可以直接通过 c := []bytes(s) 来获取一个字节的切片 c。另外,您还可以通过 copy 函数来达到相同的目的: copy(dst []byte, src string) 。
同样的,还可以使用 for-range 来获得每个元素
package main
import "fmt"
func main() {
s := "我爱你中国"
for _, value := range s {
fmt.Printf("%c ", value)
}
}
输出:
我 爱 你 中 国
我们知道,Unicode 字符会占用 2 个字节,有些甚至需要 3 个或者 4 个字节来进行表示。如果发现错误的 UTF8 字符,则该字符会被设置为 U+FFFD 并且索引向前移动一个字节。和字符串转换一样,您同样可以使用 c := []int(s) 语法,这样切片中的每个 int 都会包含对应的 Unicode 代码,因为字符串中的每次字符都会对应一个整数。类似的,您也可以将字符串转换为元素类型为 rune 的切片: r := []rune(s) 。
可以通过代码 len([]rune(s)) 来获得字符串中字符的数量,但使用 utf8.RuneCountInString(s) 效率会更高一点。
您还可以将一个字符串追加到某一个字符数组的尾部:
import "fmt"
func main() {
var r []byte
//比较适合ascii字符串,用汉字的话输出会乱码
var s string = "I love you"
r = append(r, s...)
for _, v := range r {
fmt.Printf("%c ", v)
}
}
字符串和切片的内存结构
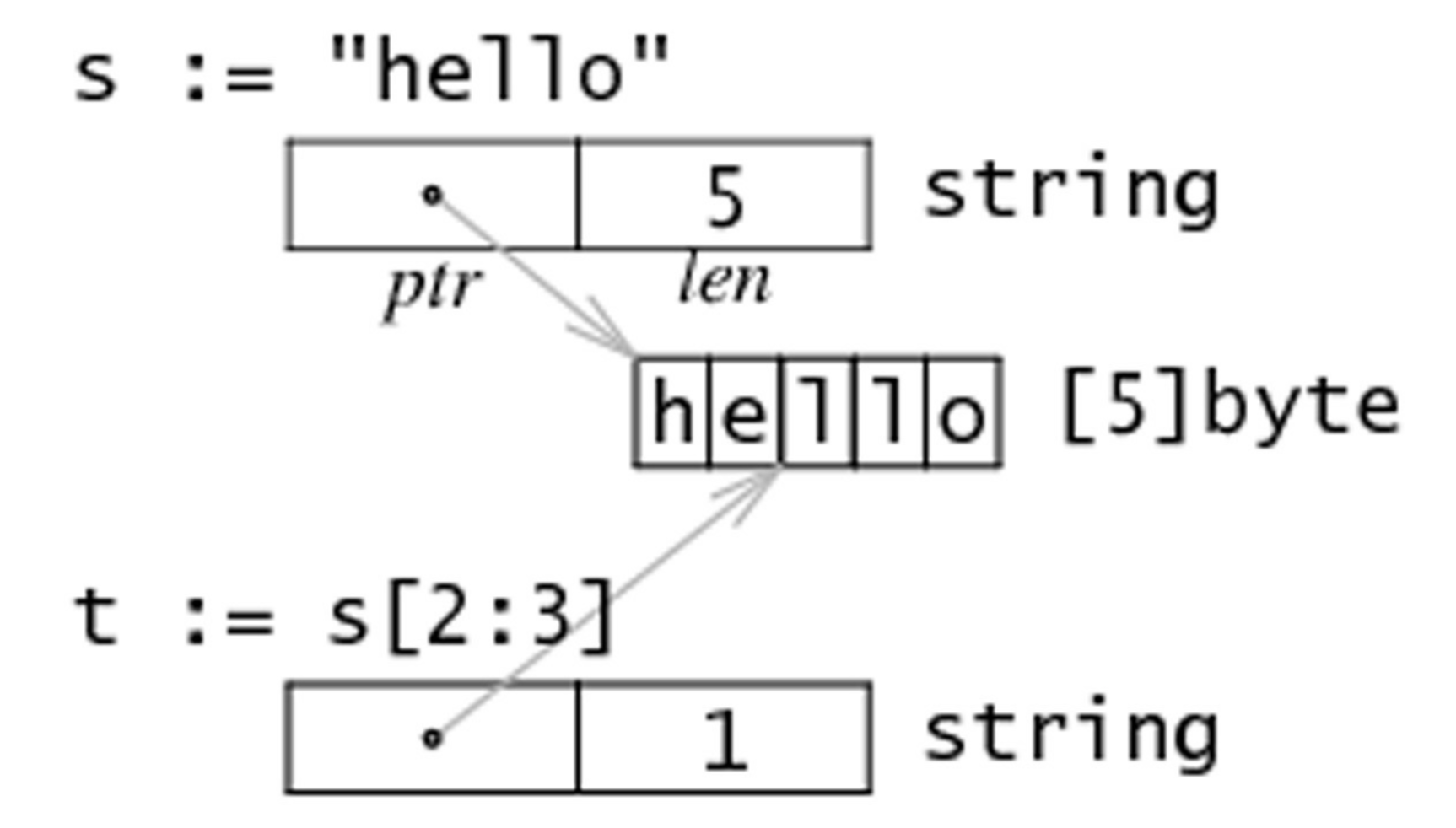
在内存中,一个字符串实际上是一个双字结构,即一个指向实际数据的指针和记录字符串长度的整数。因为指针对用户来说是完全不可见,因此我们可以依旧把字符串看做是一个值类型,也就是一个字符数组。
字符串 string s = "hello" 和子字符串 t = s[2:3] 在内存中的结构可以用下图表示:
修改字符串中的某个字符
Go 语言中的字符串是不可变的,也就是说 str[index] 这样的表达式是不可以被放在等号左侧的。如果尝试运行 str[i] = 'D' 会得到错误: cannot assign to str[i] 。
因此,您必须先将字符串转换成字节数组,然后再通过修改数组中的元素值来达到修改字符串的目的,最后将字节数组转换回字符串格式。
例如,将字符串 "hello" 转换为 "cello":
s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) //s2 == "cello"
所以,您可以通过操作切片来完成对字符串的操作。