node上的predicate functions计算过程。
好,下面看podFitsOnNode了,先略看函数声明:
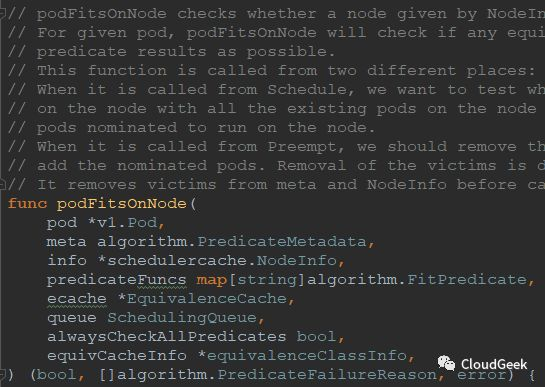
可以看到这里的注释不少,大致翻译过来是这个意思:podFitsOnNode检查一个以NodeInfo形式提供的node是否能够通过给定的predicate functions筛选;对于一个给定的pod,podFitsOnNode会检查node上是否有已经存在的等价的pod,如果存在则尝试尽量重用这个pod缓存的predicate结果信息。这个函数会从2个不同的入口被调用:Schedule and Preempt,当从Schedule进入时,本函数检测一个node在考虑所有已存在pods和被指定将跑到这个node上是所有更高优先级或者相同优先级(和当前要被调度的pod比较)的pod都跑起来的情况下能否跑现在这个被调度的pod.;;;就解释到这里,下面我们还是老规矩,看看入参和返回值:
入参:
- pod *v1.Pod,
- meta algorithm.PredicateMetadata,
- info *schedulercache.NodeInfo,
//上一个函数的nodeNameToInfo[nodeName]获取到的NodeInfo
- predicateFuncs map[string]algorithm.FitPredicate,
- ecache *EquivalenceCache,
- queue SchedulingQueue,
- alwaysCheckAllPredicates bool,
- equivCacheInfo *equivalenceClassInfo,
返回值:
- bool,
- []algorithm.PredicateFailureReason,
//上层函数返回值中的FailedPredicateMap是map[string][]algorithm.PredicateFailureReason类型
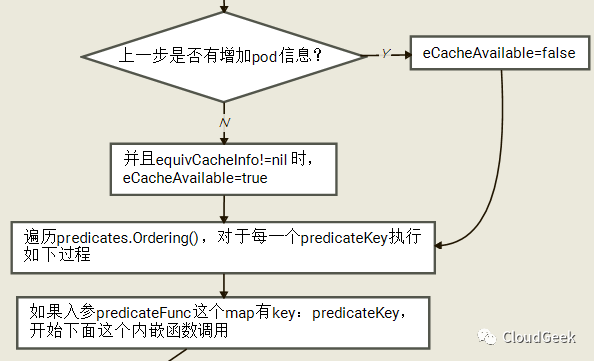
这里没有逐个解释,基本和上层函数的参数对应得上,findNodesThatFit解释哪些nodes能够跑给定的pod,而podFitsOnNode解释给定node能否跑给定pod.我们先看一下这个过程的简要流程图(2次循环考虑第一次的情况):

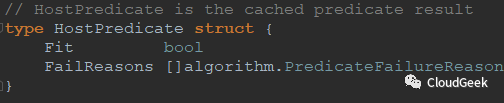
看一下代码:predicateResults := make(map[string]HostPredicate)这一行的string标识predicate名称,HostPredicate类型是:
这个i从0到1只跑2遍的for循环中分歧点只有如下这个if:
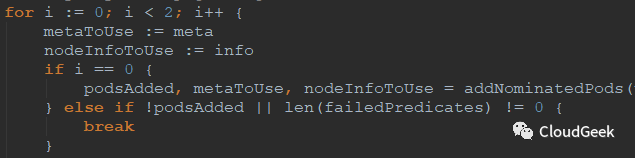
如上,在i为0时调用到了addNominatedPods函数,这个函数把更高或者相同优先级的pod(待运行到本node上的)信息增加到meta和nodeInfo中,也就是对应考虑这些nominated都Running的场景;后面i为1对应的就是不考虑这些pod的场景。对于这个2遍过程,注释里是这样解释的:
如果这个node上“指定”了更高或者相等优先级的pods(也就是优先级不低于本pod的一群pods将要跑在这个node上),我们运行predicates过程当这些pods信息全被加到meta和nodeInfo中的情况。如果所有的predicates过程成功了,我们再次运行这些predicates过程在这些pods信息没有被加到meta和nodeInfo的情况。这样第二次过程可能会因为一些pod间的亲和性策略过不了(因为这些计划要跑的pods没有跑,所以可能亲和性被破坏)。这里其实基于2点考虑:1、有亲和性要求的pod如果认为这些nominated pods在,则在这些nominated pods不在的情况下会异常;2、有反亲和性要求的pod如果认为这些nominated pods不在,则在这些nominated pods在的情况下会异常。
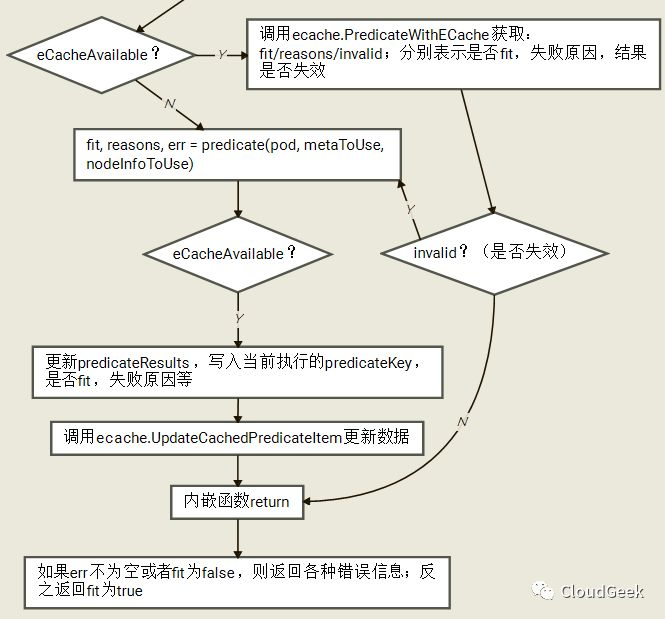
我们接着看predicate函数主要是怎样被调用的:
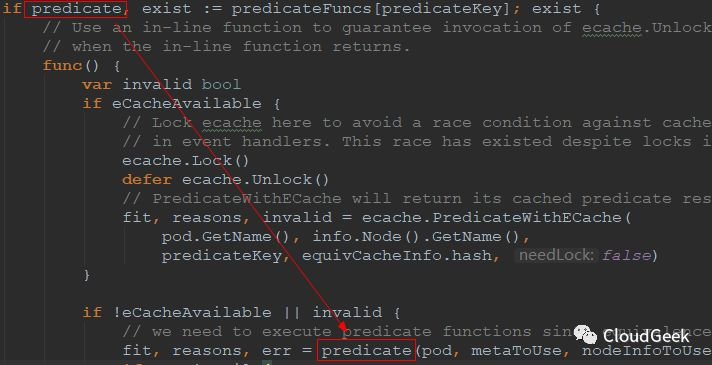
如上,predicate是FitPredicate类型的一个对象,也就是对应具体的predicate函数,所以下面的predicate(pod, metaToUse, nodeInfoToUse)也就对应一个具体的predicate函数的执行。
最后我们瞄一眼具体的predicate函数是怎么定义的:
一个predicate函数类似这样:
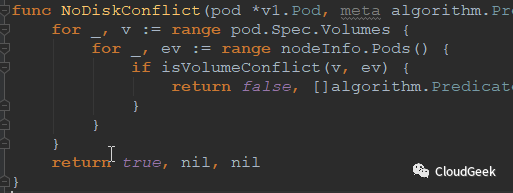
这样被注册:

紫色部分的常量对应一个个字符串描述:
行,剩下的我们下回分解~