在上一节中我们介绍了 数组和切片的实现原理,这一节会介绍 Golang 中的另一个集合元素 ― 哈希,也就是 Map 的实现原理;哈希表是除了数组之外,最常见的数据结构,几乎所有的语言都会有数组和哈希表这两种集合元素,有的语言将数组实现成列表,有的语言将哈希表称作结构体或者字典,但是它们其实就是两种设计集合元素的思路,数组用于表示一个元素的序列,而哈希表示的是键值对之间映射关系,只是不同语言的叫法和实现稍微有些不同。
概述
哈希表 是一种古老的数据结构,在 1953 年就有人使用拉链法实现了哈希表,它能够根据键(Key)直接访问内存中的存储位置,也就是说我们能够直接通过键找到该键对应的一个值,哈希表名称的来源是因为它使用了哈希函数将一个键映射到一个桶中,这个桶中就可能包含该键对应的值。
哈希函数
哈希表的实现关键在于如何选择哈希函数,哈希函数的选择和在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键映射到唯一的索引上,但是键集合的数量会远远大于映射的范围,不同的键经过哈希函数的处理应该会返回唯一的值,这要求哈希函数的输出范围大于输入范围,所以在实际使用时,这个理想状态是不可能实现的。

比较实际的方式是让哈希函数的结果能够均匀分布,这样虽然哈希会发生碰撞和冲突,但是我们只需要解决哈希碰撞的问题就可以在工程上去使用这种更实际的方案,结果不均匀的哈希函数会造成更多的冲并带来更差的性能。
在一个使用结果较为均匀的哈希函数中,哈希的增删改查都需要 O(1) 的时间复杂度,但是非常不均匀的哈希函数会导致所有的操作都会占用最差 O(n) 的复杂度,所以在哈希表中使用好的哈希函数是至关重要的。
冲突解决
就像我们之前所提到的,在通常情况下,哈希函数输入的范围一定会远远大于输出的范围,所以我们一定会在使用哈希表的过程中遇到冲突,如果有一个不会出现冲突的完美哈希函数,那么我们其实只需要将所有的值都存储在一个一维的数组中就可以了。
就像上面提到的,这种场景在现实中基本上是不会存在的,我们的哈希函数往往都是不完美的并且输出的范围也都是有限的,这也一定会发生哈希的碰撞,我们就需要使用一些方法解决哈希的碰撞问题,常见的就是开放寻址法和拉链法两种。
开放寻址法
开放寻址法 是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是在一维数组对元素进行探测和比较以判断待查找的目标键是否存在于当前的哈希表中,如果我们使用开放寻址法来实现哈希表,那么在初始化哈希表时就会创建一个新的数组,如果当我们向当前『哈希表』写入新的数据时发生了冲突,就会将键值对写入到下一个不为空的位置:
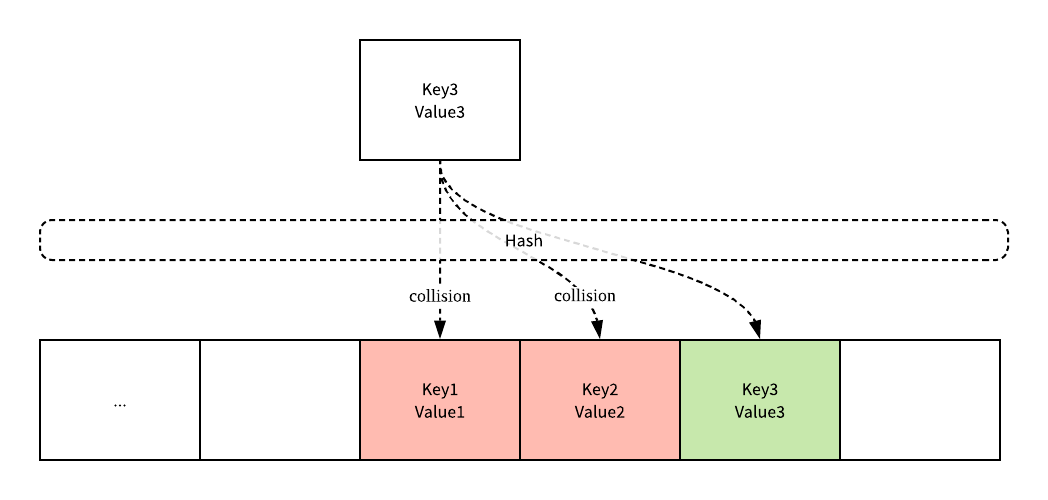
上图展示了键 Key3 与已经存入『哈希表』中的两个键 Key1 和 Key2 发生冲突时,Key3 会被自动写入到 Key2 后面的空闲内存上,在这时我们再去读取 Key3 对应的值时就会先对键进行哈希并所索引到 Key1 上,对比了目标键与 Key1 发现不匹配就会读取后面的元素,直到内存为空或者找到目标元素。
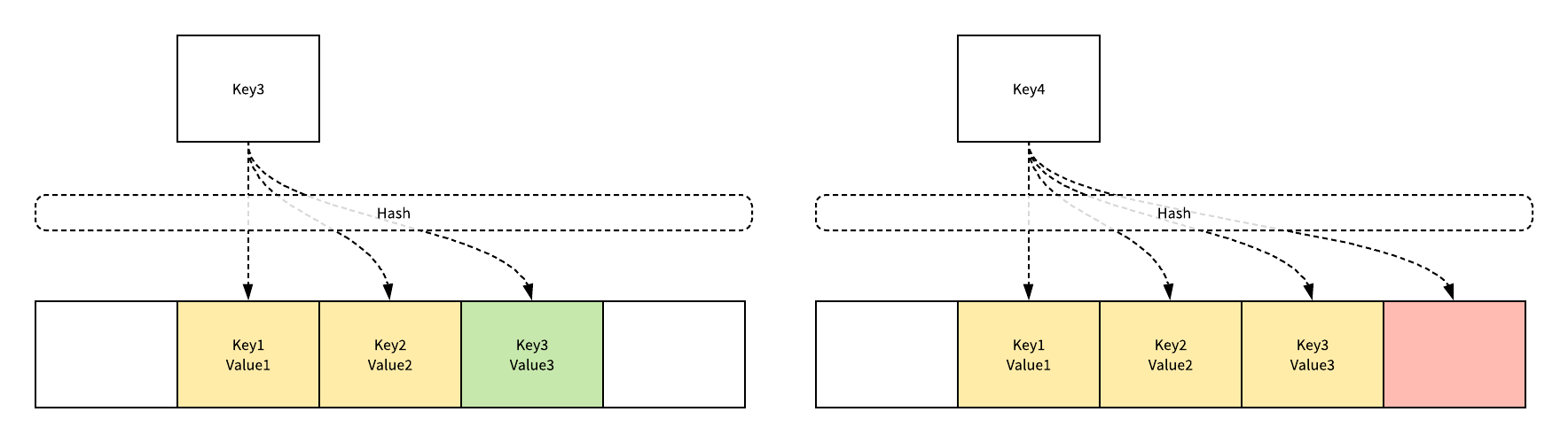
当我们查找某个键对应的数据时,就会对哈希命中的内存进行线性探测,找到目标键值对或者空内存就意味着这一次查询操作的结束。
开放寻址法中对性能影响最大的就是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会同时影响哈希表的查找和插入性能,当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,所以在实现哈希表时一定要时刻关注装载因子的变化。
拉链法
与开放地址法相比,拉链法是哈希表中最常见的实现方法,大多数的编程语言都是用拉链法实现哈希表,它的实现相对比较简单,平均查找的长度也比较短,而且各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
拉链法的实现其实就是使用数组加上链表组合起来实现哈希表,数组中的每一个元素其实都是一个链表,我们可以将它看成一个可以扩展的二维数组:
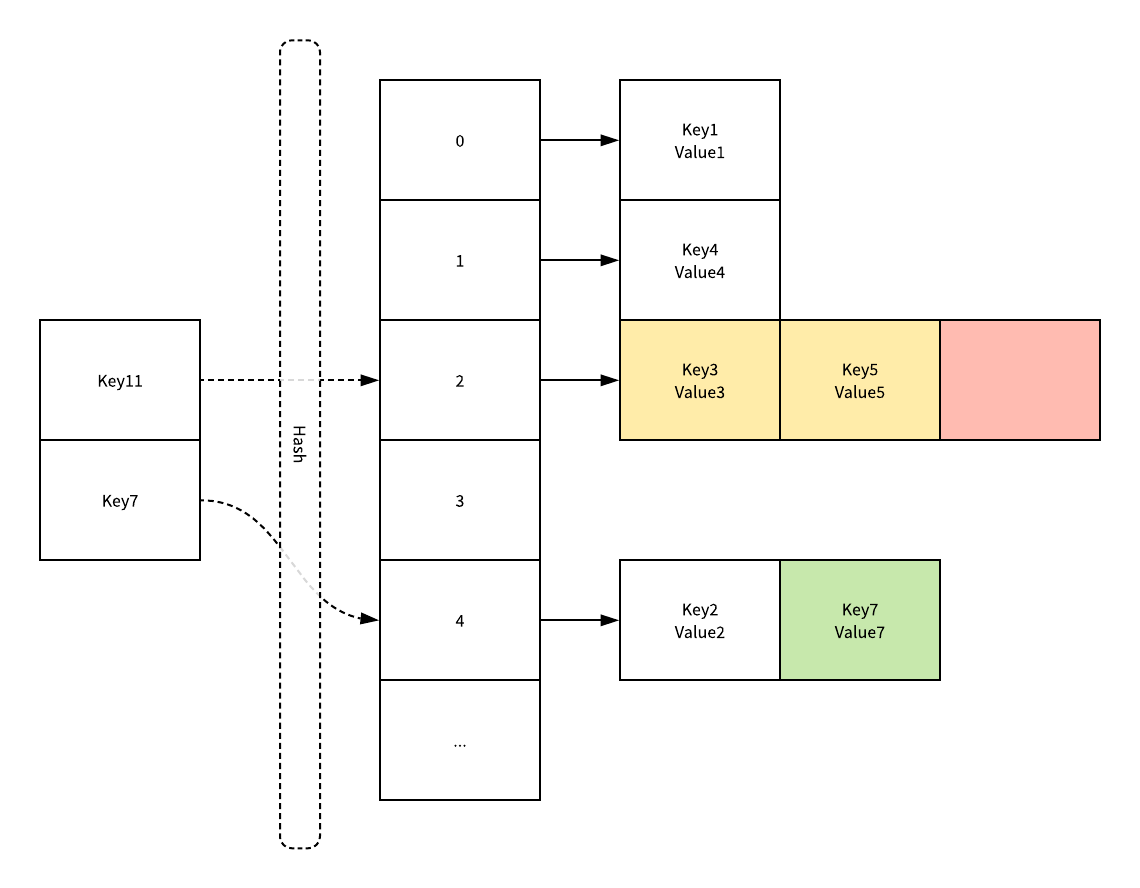
当我们需要将一个键值对加入一个哈希表时,键值对中的键都会先经过一个哈希函数,哈希函数返回的哈希会帮助我们『选择』一个桶,然后遍历当前桶中持有的链表,找到键相同的键值对执行更新操作或者遍历到链表的末尾追加一个新的键值对。
如果要通过某个键在哈希表中获取对应的值,就会经历如下的过程:
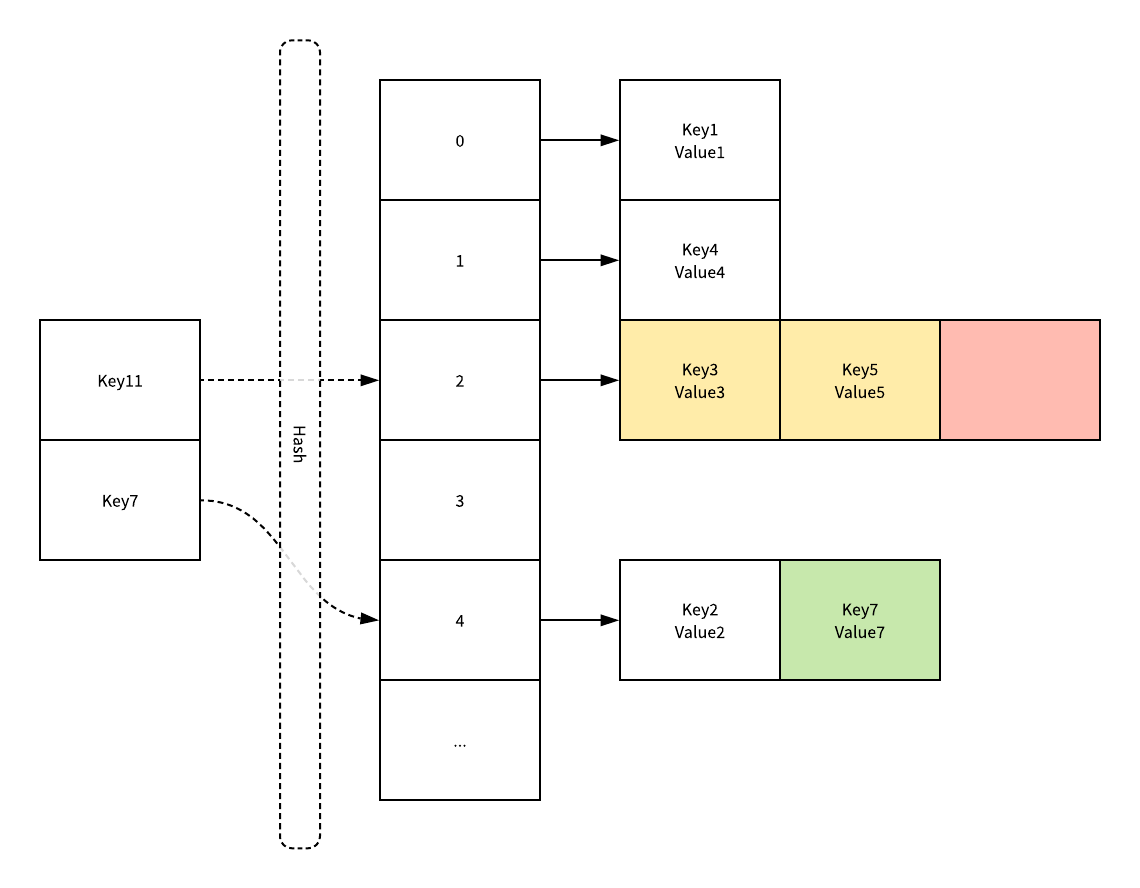
Key11 就是展示了一个键在哈希表中不存在的例子,当哈希表发现它命中 2 号桶时,它会依次遍历桶中的链表,解决遍历到链表的末尾也没有找到期望的键,所以该键对应的值就是空。
在一个性能比较好的哈希表中,每一个桶中都应该有 0 或者 1 个元素,有时会有 2~3 个元素,很少会发生遇到超过这个数量的情况,每一次读写哈希表的时间基本上都花在了定位桶和遍历链表这两个过程,有 1000 个桶的哈希表如果保存了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比一个链表的性能好 1000 倍。
初始化
我们既然已经介绍了常见哈希表的一些基本原理和实现方法,那么可以开始介绍文章正题,也就是 Go 语言中哈希表的实现原理,首先要讲的就是哈希在 Go 中的表示以及初始化哈希的两种方法 ― 通过字面量和运行时。
结构体
Golang 中哈希表是在 src/runtime/map.go 文件中定义的,哈希的结构体 hmap 是这样的,其中有几个比较关键的参数:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}count用于记录当前哈希表元素数量,这个字段让我们不再需要去遍历整个哈希表来获取长度;B表示了当前哈希表持有的buckets数量,但是因为哈希表的扩容是以 2 倍数进行的,所以这里会使用对数来存储,我们可以简单理解成len(buckets) == 2^B;hash0是哈希的种子,这个值会在调用哈希函数的时候作为参数传进去,它的主要作用就是为哈希函数的结果引入一定的随机性;oldbuckets是哈希在扩容时用于保存之前buckets的字段,它的大小都是当前buckets的一半;
这份 hmap 的结构体其实会同时在编译期间和运行时存在,编译期间会使用 hmap 函数构建一个完全相同结构体:
func hmap(t *types.Type) *types.Type {
bmap := bmap(t)
fields := []*types.Field{
makefield("count", types.Types[TINT]),
makefield("flags", types.Types[TUINT8]),
makefield("B", types.Types[TUINT8]),
makefield("noverflow", types.Types[TUINT16]),
makefield("hash0", types.Types[TUINT32]),
makefield("buckets", types.NewPt