r(bmap)),
makefield("oldbuckets", types.NewPtr(bmap)),
makefield("nevacuate", types.Types[TUINTPTR]),
makefield("extra", types.Types[TUNSAFEPTR]),
}
hmap := types.New(TSTRUCT)
hmap.SetNoalg(true)
hmap.SetFields(fields)
dowidth(hmap)
t.MapType().Hmap = hmap
hmap.StructType().Map = t
return hmap
}
因为在编译期间运行时的很多代码还不能执行,所以我们需要模拟一个 hmap 结构体为一些哈希表在编译期间的初始化提供『容器』,所以虽然说哈希表是一种比较特殊的数据结构,但是底层在实现时还是需要使用结构体来存储一些用于管理和记录的变量。
字面量
如果我们在 Go 语言中使用字面量的方式初始化哈希表,与其他的语言非常类似,一般都会使用如下所示的格式:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
我们需要在使用哈希时标记其中键值的类型信息,这种使用字面量初始化的方式最终都会通过 maplit 函数对该变量进行初始化,接下来我们就开始分析一下上述的代码是如何在编译期间通过 maplit 函数初始化的:
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
var stat, dyn []*Node
for _, r := range n.List.Slice() {
stat = append(stat, r)
}
if len(stat) > 25 {
// ...
} else {
addMapEntries(m, stat, init)
}
}
当哈希表中的元素数量少于或者等于 25 个时,编译器会直接调用 addMapEntries 将字面量初始化的结构体转换成以下的代码,单独将所有的键值对加入到哈希表中:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
而如果哈希表中元素的数量超过了 25 个,就会在编译期间创建两个数组分别存储键和值的信息,这些键值对会通过一个如下所示的 for 循环加入目标的哈希:
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
但是无论使用哪种方法,使用字面量初始化的过程都会使用 Go 语言中的关键字来初始化一个新的哈希并通过 [] 语法设置哈希中的键值,当然这里生成的用于初始化数组的字面量也会被编译器展开,具体的展开和实现方式可以阅读上一节 数组和切片 了解相关内容。
运行时
无论我们是在 Go 语言中直接使用 make 还是由编译器生成 make 其实都会在 类型检查 期间被转换成 makemap函数来创建哈希表:
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
这个函数会通过 fastrand 创建一个随机的哈希种子,然后根据传入的 hint 计算出需要的最小需要的桶的数量,最后再使用 makeBucketArray创建用于保存桶的数组,这个方法其实就是根据传入的 B 计算出的需要创建的桶数量在内存中分配一片连续的空间用于存储数据,在创建桶的过程中还会额外创建一些用于保存溢出数据的桶,数量是 2^(B-4) 个。
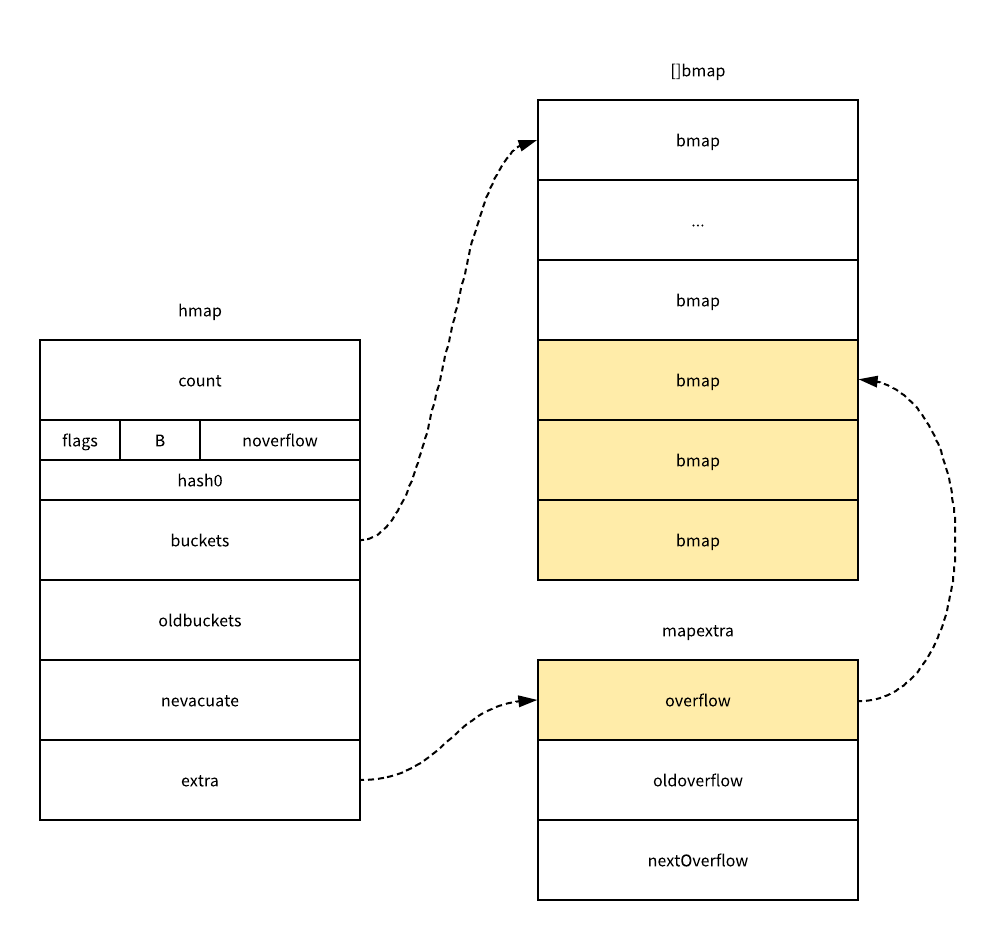
哈希表的类型其实都存储在每一个桶中,这个桶的结构体 bmap 其实在 Go 语言源代码中的定义只包含一个简单的 tophash 字段:
type bmap struct {
tophash [bucketCnt]uint8
}
哈希表中桶的真正结构其实是在编译期间运行的函数 bmap 中被『动态』创建的:
func bmap(t *types.Type) *types.Type {
bucket := types.New(TSTRUCT)
keytype := t.Key()
valtype := t.Elem()
dowidth(keytype)
dowidth(valtype)
field := make([]*types.Field, 0, 5)
arr := types.NewArray(types.Types[TUINT8], BUCKETSIZE)
field = append(field, makefield("topbits", arr))
arr = types.NewArray(keytype, BUCKETSIZE)
keys := makefield("keys", arr)
field = append(field, keys)
arr = types.NewArray(valtype, BUCKETSIZE)
values := makefield("values", arr)
field = append(field, values)
if int(valtype.Align) > Widthptr || int(keytype.Align) > Widthptr {
field = append(field, makefield("pad", types.Types[TUINTPTR]))
}
otyp := types.NewPtr(bucket)
if !types.Haspointers(valtype) && !types.Hasp