worker pool简介
worker pool其实就是线程池thread pool。对于go来说,直接使用的是goroutine而非线程,不过这里仍然以线程来解释线程池。
在线程池模型中,有2个队列一个池子:任务队列、已完成任务队列和线程池。其中已完成任务队列可能存在也可能不存在,依据实际需求而定。
只要有任务进来,就会放进任务队列中。只要线程执行完了一个任务,就将任务放进已完成任务队列,有时候还会将任务的处理结果也放进已完成队列中。
worker pool中包含了一堆的线程(worker,对go而言每个worker就是一个goroutine),这些线程嗷嗷待哺,等待着为它们分配任务,或者自己去任务队列中取任务。取得任务后更新任务队列,然后执行任务,并将执行完成的任务放进已完成队列。
下图来自wiki:
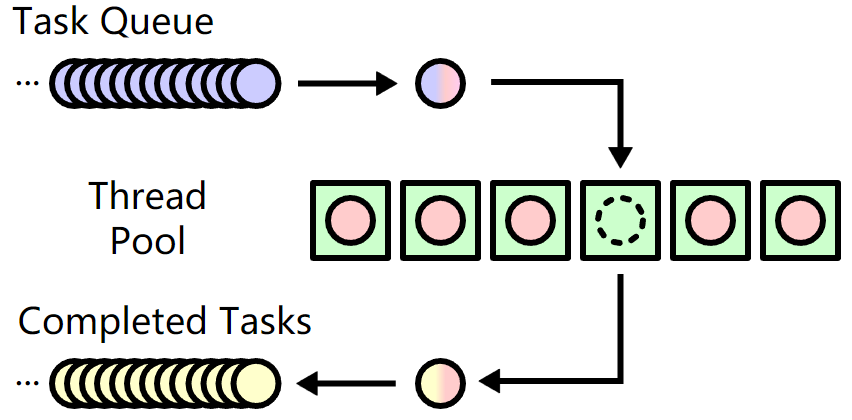
在Go中有两种方式可以实现工作池:传统的互斥锁、channel。
传统互斥锁机制的工作池
假设Go中的任务的定义形式为:
type Task struct {
...
}每次有任务进来时,都将任务放在任务队列中。
使用传统的互斥锁方式实现,任务队列的定义结构大概如下:
type Queue struct{
M sync.Mutex
Tasks []Task
}然后在执行任务的函数中加上Lock()和Unlock()。例如:
func Worker(queue *Queue) {
for {
// Lock()和Unlock()之间的是critical section
queue.M.Lock()
// 取出任务
task := queue.Tasks[0]
// 更新任务队列
queue.Tasks = queue.Tasks[1:]
queue.M.Unlock()
// 在此goroutine中执行任务
process(task)
}
}假如在线程池中激活了100个goroutine来执行Worker()。Lock()和Unlock()保证了在同一时间点只能有一个goroutine取得任务并随之更新任务列表,取任务和更新任务队列都是critical section中的代码,它们是具有原子性。然后这个goroutine可以执行自己取得的任务。于此同时,其它goroutine可以争夺互斥锁,只要争抢到互斥锁,就可以取得任务并更新任务列表。当某个goroutine执行完process(task),它将因为for循环再次参与互斥锁的争抢。
上面只是给出了一点主要的代码段,要实现完整的线程池,还有很多额外的代码。
通过互斥锁,上面的一切操作都是线程安全的。但问题在于加锁/解锁的机制比较重量级,当worker(即goroutine)的数量足够多,锁机制的实现将出现瓶颈。
通过buffered channel实现工作池
在Go中,也能用buffered channel实现工作池。
示例代码很长,所以这里先拆分解释每一部分,最后给出完整的代码段。
在下面的示例中,每个worker的工作都是计算每个数值的位数相加之和。例如给定一个数值234,worker则计算2+3+4=9。这里交给worker的数值是随机生成的[0,999)范围内的数值。
这个示例有几个核心功能需要先解释,也是通过channel实现线程池的一般功能:
- 创建一个task buffered channel,并通过allocate()函数将生成的任务存放到task buffered channel中
- 创建一个goroutine pool,每个goroutine监听task buffered channel,并从中取出任务
- goroutine执行任务后,将结果写入到result buffered channel中
- 从result buffered channel中取出计算结果并输出
首先,创建Task和Result两个结构,并创建它们的通道:
type Task struct {
ID int
randnum int
}
type Result struct {
task Task
result int
}
var tasks = make(chan Task, 10)
var results = make(chan Result, 10)这里,每个Task都有自己的ID,以及该任务将要被worker计算的随机数。每个Result都包含了worker的计算结果result以及这个结果对应的task,这样从Result中就可以取出任务信息以及计算结果。
另外,两个通道都是buffered channel,容量都是10。每个worker都会监听tasks通道,并取出其中的任务进行计算,然后将计算结果和任务自身放进results通道中。
然后是计算位数之和的函数process(),它将作为worker的工作任务之一。
func process(num int) int {
sum := 0
for num != 0 {
digit := num % 10
sum += digit
num /= 10
}
time.Sleep(2 * time.Second)
return sum
}这个计算过程其实很简单,但随后还睡眠了2秒,用来假装执行一个计算任务是需要一点时间的。
然后是worker(),它监听tasks通道并取出任务进行计算,并将结果放进results通道。
func worker(wg *WaitGroup){
defer wg.Done()
for task := range tasks {
result := Result{task, process(task.randnum)}
results <- result
}
}上面的代码很容易理解,只要tasks channel不关闭,就会一直监听该channel。需要注意的是,该函数使用指针类型的*WaitGroup作为参数,不能直接使用值类型的WaitGroup作为参数,这样会使得每个worker都有一个自己的WaitGroup。
然后是创建工作池的函数createWorkerPool(),它有一个数值参数,表示要创建多少个worker。
func createWorkerPool(numOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < numOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}创建工作池时,首先创建一个WaitGroup的值wg,这个wg被工作池中的所有goroutine共享,每创建一个goroutine都wg.Add(1)。创建完所有的goroutine后等待所有的groutine都执行完它们的任务,只要有一个任务还没有执行完,这个函数就会被Wait()阻塞。当所有任务都执行完成后,关闭results通道,因为没有结果再需要向该通道写了。
当然,这里是否需要关闭results通道,是由稍后的range迭代这个通道决定的,不关闭这个通道会一直阻塞range,最终导致死锁。
工作池部分已经完成了。现在需要使用allocate()函数分配任务:生成一大堆的随机数,然后将Task放进tasks通道。该函数有一个代表创建任务数量的数值参数:
func allocate(numOfTasks int