t = 1000, n = 1000)
params <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
getFitData(x[1:t])
}
rownames(params) <- 50:1000
params
}
names(experiments1) <- seeds
experiments1 <- lapply(experiments1, param_reshape)
names(experiments1) <- c(
103117, 123456, 987654, 101010,
8675309, 81891, 222222, 999999, 110011)
experiments1_df <- ldply(experiments1, .id = "seed")
head(experiments1_df)
## seed t parameter value se
## 1 103117 50 omega 0.1043139 0.9830089
## 2 103117 51 omega 0.1037479 4.8441246
## 3 103117 52 omega 0.1032197 4.6421147
## 4 103117 53 omega 0.1026722 1.3041128
## 5 103117 54 omega 0.1020266 0.5334988
## 6 103117 55 omega 0.2725939 0.6089607
ggplot(
experiments1_df,
aes(x = t, y = value)) +
geom_line() +
geom_ribbon(
aes(ymin = value - 2 * se,
ymax = value + 2 * se),
color = "grey", alpha = 0.5) +
geom_hline(yintercept = 0.2, color = "blue") +
scale_y_continuous(
breaks = c(0, 0.2, 0.25, 0.5, 0.75, 1)) +
coord_cartesian(ylim = c(0, 1)) +
facet_grid(seed ~ parameter) +
ggtitle(
"Successive parameter estimates using NLMINB optimization")
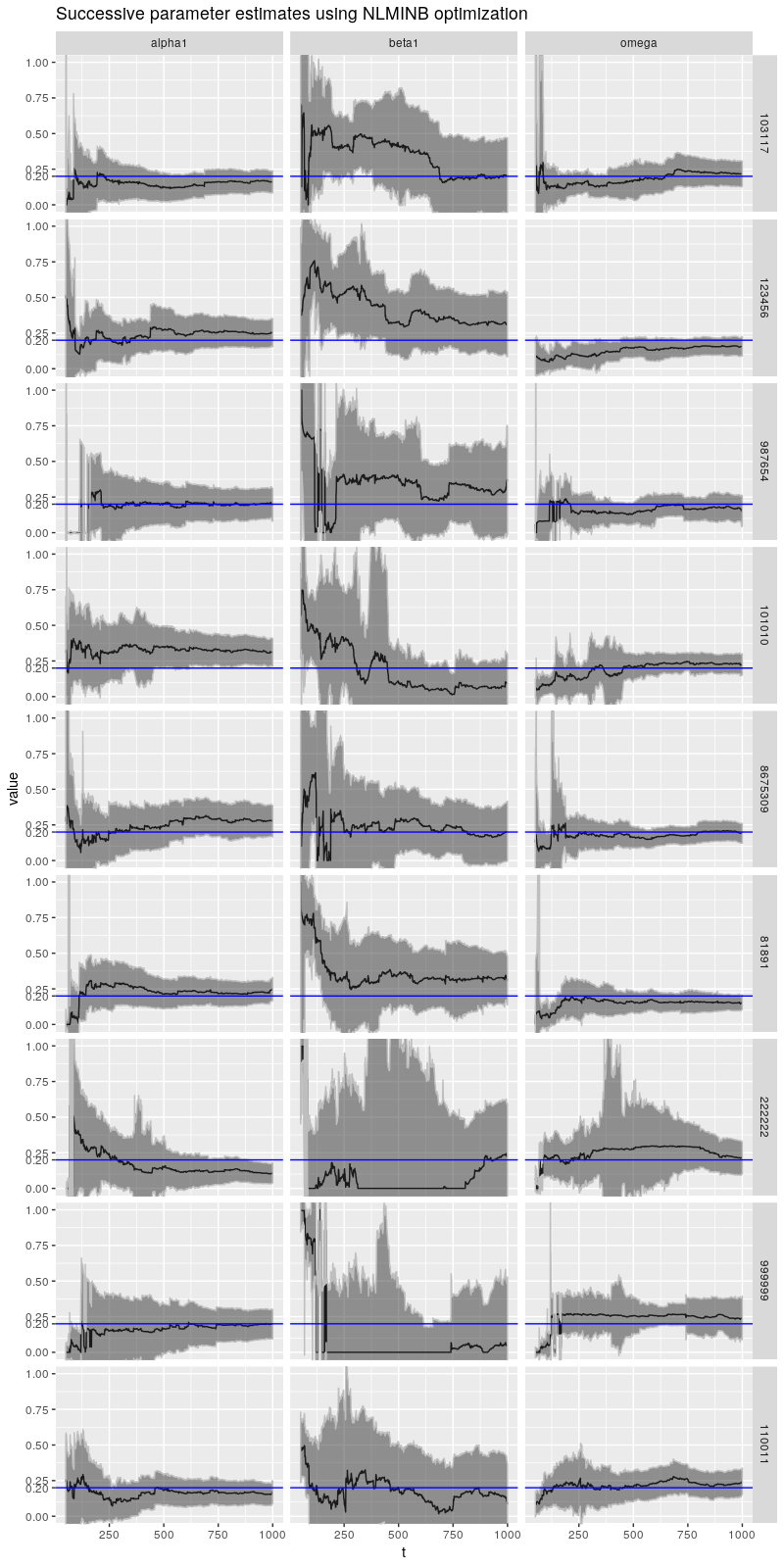
在这个图中我们看到了 \(\beta\) 的其他类型的病态行为,特别是种子是 222222 和 999999 的情况,其中 \(\beta\) 长期远低于正确值。对于所有这些模拟,\(\beta\) 开始比正确的值大得多,接近 1,对于前面提到的两个种子,\(\beta\) 从非常高的水平突然跳到非常低的水平。(此处未显示种子 110131 和 110137 的结果,它们甚至更糟!)
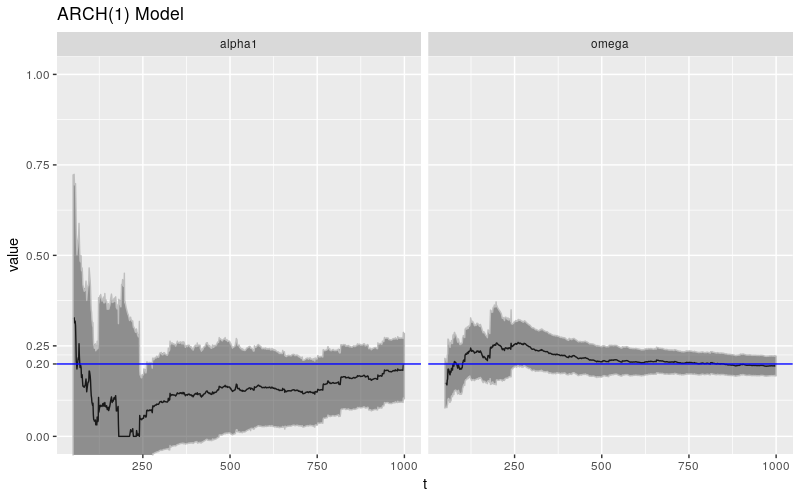
其他参数也存在自己的病态行为,但情况似乎并不那么严峻。我们看到的病态行为可能与 \(\beta\) 的估计有关。实际上,如果我们看一下 \(\text{ARCH}(1)\) 过程的类似实验(这是一个 \(\text{GARCH}(1,0)\) 过程,相当于设置 \(\beta = 0\)),我们会看到更好的行为。
set.seed(110117)
x <- garchSim(
garchSpec(
model = list(alpha = 0.2, beta = 0.2, omega = 0.2)),
n.start = 1000, n = 1000)
xarch <- garchSim(
garchSpec(
model = list(omega = 0.2, alpha = 0.2, beta = 0)),
n.start = 1000, n = 1000)
params_arch <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
getFitData(
xarch[1:t], formula = ~ garch(1, 0))
}
rownames(params_arch) <- 50:1000
print(ggp %+% param_reshape(params_arch) + ggtitle("ARCH(1) Model"))
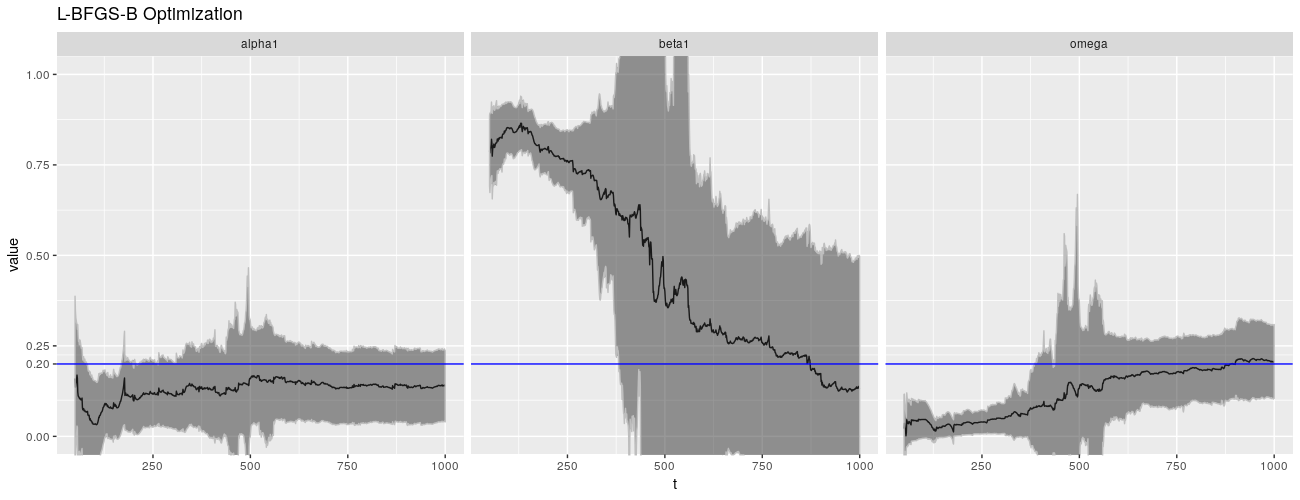
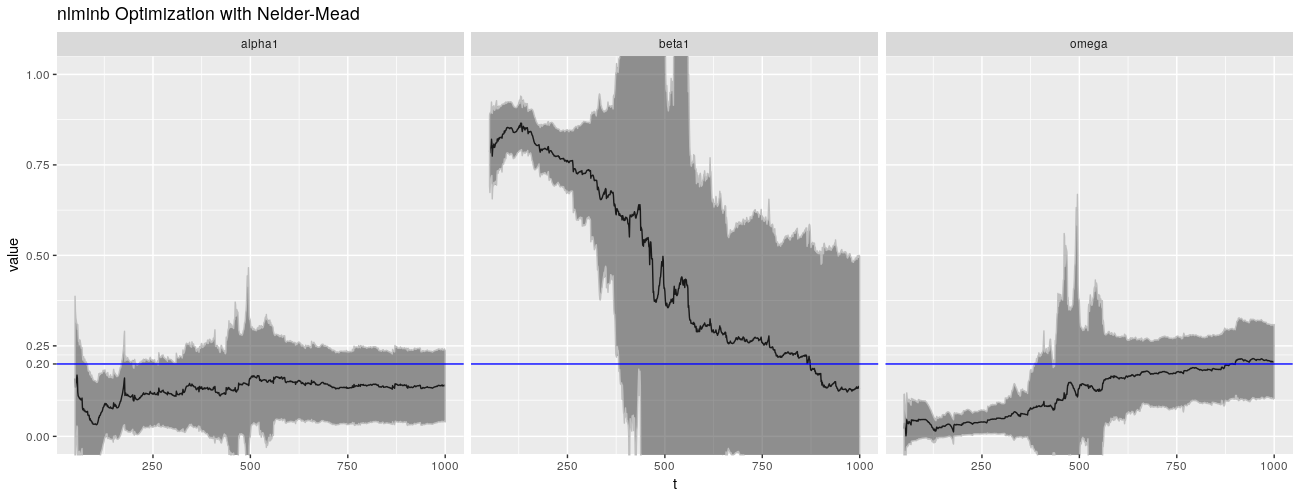
病态行为似乎是数值性的,并且与 \(\beta\) 密切相关。默认情况下,garchFit() 使用 nlminb()(带约束的拟牛顿方法)来解决优化问题,使用数值计算出的梯度。不过,我们可以选择其他方法。我们可以使用 L-BFGS-B 方法,以及 Nelder-Mead 方法。
不幸的是,这些替代优化算法没有做得更好,他们甚至可能会做得更糟。
# lbfgsb algorithm
params_lbfgsb <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
getFitData(x[1:t], algorithm = "lbfgsb")
}
rownames(params_lbfgsb) <- 50:1000
# nlminb+nm algorithm
params_nlminbnm <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
getFitData(x[1:t], algorithm = "nlminb+nm")
}
rownames(params_nlminbnm) <- 50:1000
# lbfgsb+nm algorithm
params_lbfgsbnm <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
getFitData(x[1:t], algorithm = "lbfgsb+nm")
}
rownames(params_lbfgsbnm) <- 50:1000
# cond.dist is norm (default)
params_norm <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
getFitData(x[1:t], cond.dist = "norm")
}
rownames(params_norm) <- 50:1000
print(ggp %+% param_reshape(params_lbfgsb) + ggtitle("L-BFGS-B Optimization"))
print(ggp %+% param_reshape(params_nlminbnm) + ggtitle("nlminb Optimization with Nelder-Mead"))
print(ggp