%+% param_reshape(params_lbfgsbnm) + ggtitle("L-BFGS-B Optimization with Nelder-Mead"))
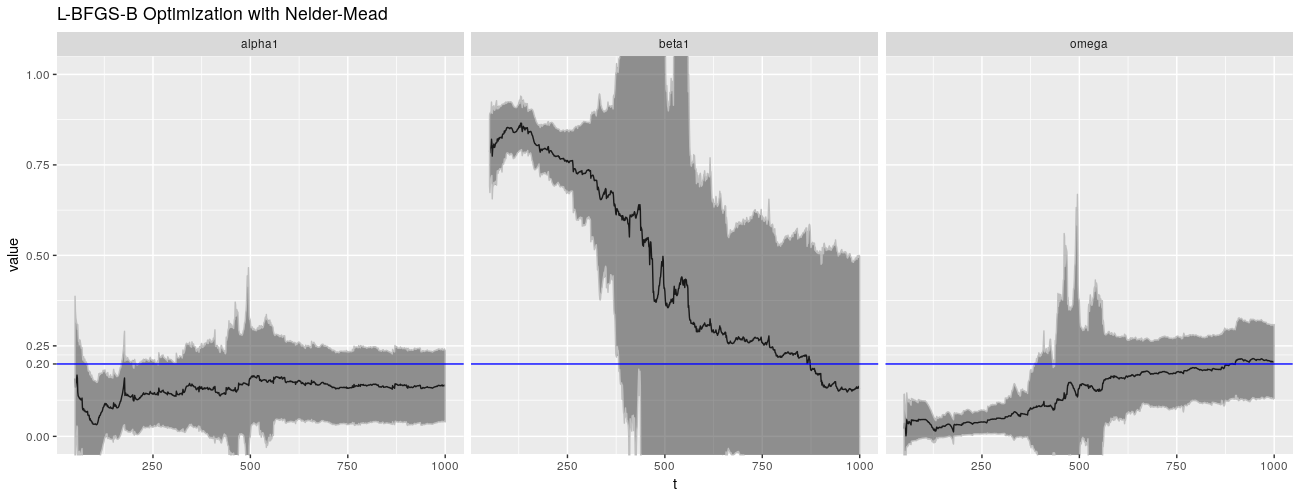
诚然,QMLE 并非 garchFit() 的默认估计方法,默认的是正态分布。不幸的是,这没有带来更好的结果。
print(ggp %+% param_reshape(params_norm) + ggtitle("cond.dist = 'norm'"))
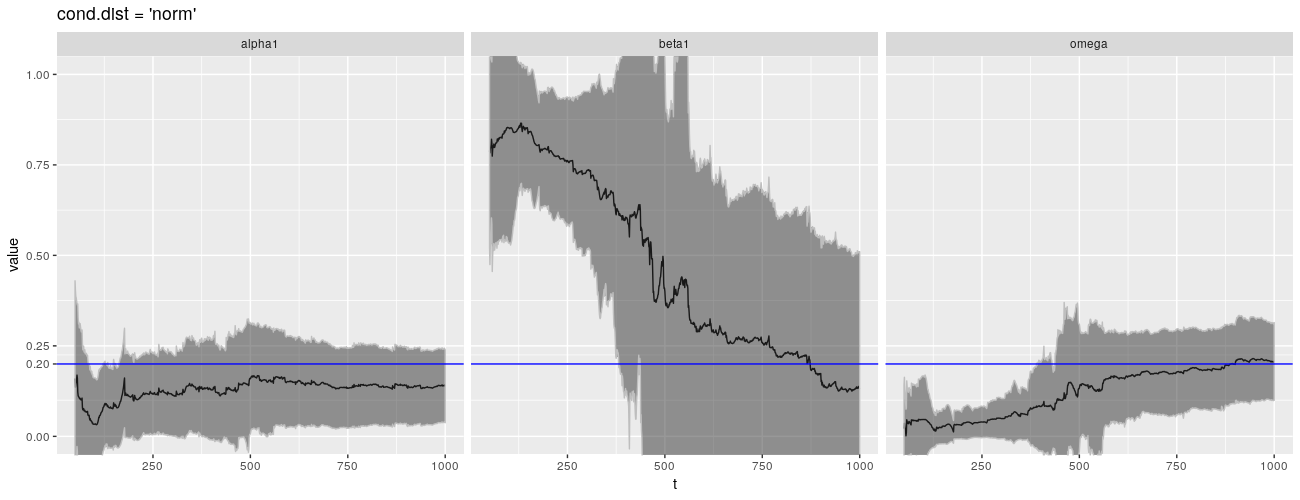
在 CRAN,fGarch 自 2013 年以来没有看到更新!有可能 fGarch 开始显现出它的落伍老迈,新的包装已经解决了我在这里强调的一些问题。包 tseries 提供了一个函数 garch(),它也通过 QMLE 拟合 \(\text{GARCH}(1,1)\) 模型,并且比 fGarch 更新。它是我所知道的唯一可以拟合 \(\text{GARCH}(1,1)\) 模型的其他包。
不幸的是,garch() 没有做得更好。事实上,它似乎更糟糕。问题再一次出现在 \(\beta\) 身上。
library(tseries)
getFitDatagarch <- function(x)
{
garch(x)$coef
}
params_tseries <- foreach(
t = 50:1000,
.combine = rbind,
.packages = c("tseries")) %dopar%
{
getFitDatagarch(x[1:t])
}
rownames(params_tseries) <- 50:1000
param_reshape_tseries <- function(p)
{
p <- as.data.frame(p)
p$t <- as.integer(rownames(p))
pnew <- melt(
p, id.vars = "t", variable.name = "parameter")
pnew$parameter <- as.character(pnew$parameter)
return(pnew)
}
ggplot(
param_reshape_tseries(params_tseries),
aes(x = t, y = value)) +
geom_line() +
geom_hline(
yintercept = 0.2, color = "blue") +
scale_y_continuous(
breaks = c(0, 0.2, 0.25, 0.5, 0.75, 1)) +
coord_cartesian(ylim = c(0, 1)) +
facet_grid(. ~ parameter)

所有这些实验均在固定(但随机选择)的序列上进行。实验显示,对于样本量小于 300(可能更大的数字)的情况,\(\text{GARCH}(1,1)\) 参数估计的分布是可疑的。当我们模拟许多过程并查看参数的分布时会发生什么?
我模拟了 10000 个样本大小为 100、500 和 1000 的 \(\text{GARCH}(1,1)\) 过程(使用与之前相同的参数)。以下是参数估计的经验分布。
experiments2 <- foreach(
n = c(100, 500, 1000)) %do%
{
mat <- foreach(
i = 1:10000,
.combine = rbind,
.packages = c("fGarch")) %dopar%
{
x <- garchSim(
garchSpec(
model = list(
omega = 0.2, alpha = 0.2, beta = 0.2)),
n.start = 1000,
n = n)
getFitData(x)
}
rownames(mat) <- NULL
mat
}
names(experiments2) <- c(100, 500, 1000)
save(params, x, experiments1,
xarch, params_arch, params_lbfgsb,
params_nlminbnm, params_lbfgsbnm,
params_norm, params_tseries,
experiments2,
file = "garchfitexperiments.Rda")
param_sim <- lapply(
experiments2,
function(mat)
{
df <- as.data.frame(mat)
df <- df[c("omega", "alpha1", "beta1")]
return(df)
}) %>%
ldply(.id = "n")
param_sim <- param_sim %>%
melt(id.vars = "n", variable.name = "parameter")
head(param_sim)
## n parameter value
## 1 100 omega 8.015968e-02
## 2 100 omega 2.493595e-01
## 3 100 omega 2.300699e-01
## 4 100 omega 3.674244e-07
## 5 100 omega 2.697577e-03
## 6 100 omega 2.071737e-01
ggplot(
param_sim,
aes(x = value)) +
geom_density(
fill = "grey", alpha = 0.7) +
geom_vline(
xintercept = 0.2, color = "blue") +
facet_grid(
n ~ parameter)
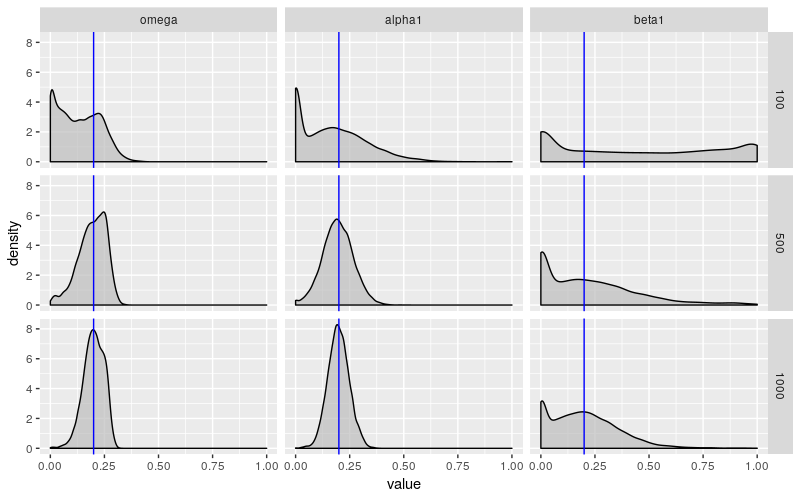
当样本量为 100 时,这些估计远非可靠。\(\omega\) 和 \(\alpha\) 以一种令人不安的倾向趋近于 0,而 \(\beta\) 几乎可以说是任何东西。如上所述,garchFit() 报告的标准差不会捕获这种行为。对于较大的样本量,\(\omega\) 和 \(\alpha\) 表现得更好,但 \(\beta\) 仍显示出令人不安的行为。它的变化幅度几乎没有变化,并且它仍然有过小的倾向。
最让我困扰的是样本量为 1000 让我感觉很大。如果一个人正在查看股票价格的每日数据,那么此样本大小大致相当于 4 年的数据。这告诉我,这种病态行为正在影响人们现在试图估计并在模型中使用的 GARCH 模型。
结论
由 John C. Nash 撰写的题为《On best practice optimization methods in R》的文章,发表于 2014 年 9 月的 Journal of Statistical Software,讨论了 R 需要更好的优化计算实践。特别是,他强调了 garchFit() 使用了过时的方法(或至少它们的 R 实现)。他主张在社区中提高对优化问题的认识,并提高包的灵活性,而不仅仅是使用 optim() 提供的不同算法。
我在本文中强调的问题让我更加意识到选择在优化方法中的重要性。我最初的目标是