近期公司在做架构梳理已经项目架构方向,不知不觉就引起了使用“work”跑数据还是用“MQ”进行跑数据的争论!
对于争论这件事在各行各业都有,其实我觉得针对“争论”这个词的根源在于一件事情有很多解决方案,每个人的认知不同,
给出的解决方案也不同。然而如果有一个对实际情况都了解和对解决问题有充足认知的情况下,我想他是会权衡利弊的。
我们先列举几个已经算是比较成熟的开源框架:
WORK:TBschedule、Quartz、spring schedule、JDK的time ,线程池定时等;
MQ:RocketMQ、RabbitMQ、Kafka、ActiveMQ、MSMQ、ZeroMQ等等;
好,废话不多说,我们就事论事,我们就单纯的从以下几个角度来评论以下到底谁(work/mq)更有优势:
1、易用性
2、可扩展性
3、可监控性
4、性能
5、可堆积数据量
6、稳定性
以上是我列出的几个对比选项,我们将逐一解说。(对于work和MQ的选型不是本人讨论的范围不做深入讨论)
我们就拿上面列出的work系列的第一个与MQ系列的第一个进行比较:
Tbshcedule与RocketMQ,这两个都是阿里开发并开源的比较起来可能会更好一点。擂台开始

1、易用性
WORK:TBSchedule最新版本使用zookeeper作为注册一致性等功能的调和器,zookeeper本身很稳定不用怎么管理,
开发代码是直接继承接口,然后自己实现业务逻辑,处理完成之后需要做状态回传处理(比如更新数据状态)
处理失败,会多次重复处理可能会因为一条数据的失败而导致后面数据处理不了(除非自己做优先级策略)
定义数据平均分发策略。
读取数据会平均分发到对应的处理器类,可批量,部署的时候需要调整策略,最小时间间隔是1s
RocketMQ:开源的架构模式为多个节点注册到命名服务,生产者与消费者以及broker的分发负载通过命名服务来管理。
开发代码同样是继承接口实现,然后数据分发到对应的处理器类,最后成功与否返回对应的ack,处理失败不影响
后续数据处理,失败数据会延迟重复处理多次。同样可批量,没有定时执行的概念,有数据就处理,几乎不会等待。
小结:处理数据同样都依赖数据状态标记,但是RocketMQ已经为我们实现了基本失败处理的简单机制,不是特别的情况,
已经足够用了,这是优势之一,数据处理状态不用与第三方系统交互,这是优势之二。其中有TBSchedule有一点就是
自己定义数据平均分发策略,目前不能评判是缺点还是优点,文章后面会说明
2、可扩展性
可扩展性从两个方面讲,一个是基础服务,一个是消费服务。
基础服务就是我用这两个框架的时候肯定需要相关的基础作为支撑,比如TBSchedule需要zookeeper,RocketMQ需要borker等
基础服务:
WORK:TBSchedule需要zookeeper,zookeeper的可扩展性比较一般,是CP型的,不过zookeeper非常稳定可以互相抵消
RocketMQ:需要架设broker和namespace两种服务,两种服务都是可以平行横向扩展的,
然而RocketMQ的主要数据交换服务broker是可以在线透明扩展的,不用重启生产和消费客户端
小结:基础服务说实话可比性不是很强烈,都比较稳定,没有相差太大。
消费服务:
WORK:TBSchedule任务处理客户端可以直接copy一份然后运行起来,注册一下,调整一下线程分配,虽然有步骤但是还算简单
RocketMQ:直接copy处理程序运行包启动运行就OK了,线程会自动调节(开发的时候会根据服务器配置业务量等调整一个合理的范围)
小结:是不是感觉RocketMQ更方便那,大家了解了架构之后自然会知道两个的区别。
3、可监控性
WORK:TBSchedule只有任务主机及线程存活监控监控,数据挤压以及处理速度需要自己额外开发
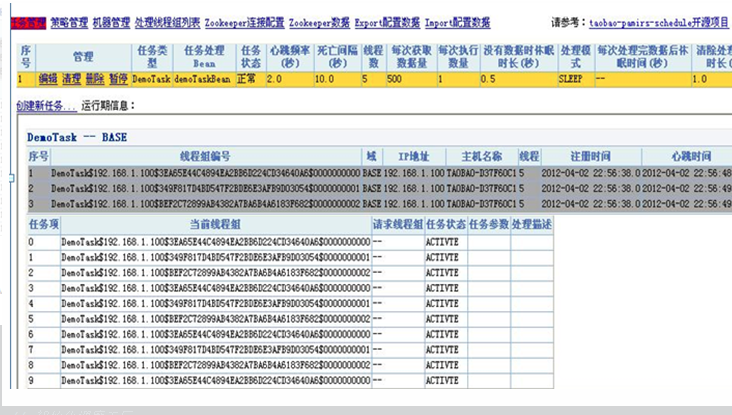
RocketMQ:对数据处理实例(消费端)等都有数据处理速度和待处理积压量相关显示。
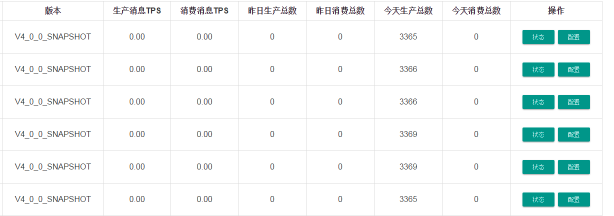
小结:不知道大家更需要哪个,哪个更好,自己斟酌选择吧!这个不多说
4、性能
其实对于性能我就不展开说了没什么可比性,关键是取决于业务处理的速度,如果非要较真的话,
TBSchedule每个线程执行有1秒的停顿,不过这个可以忽略(不要告诉我说你就处理10几条数据,每条几毫秒就处理完了)
虽然不较真但是从第一点易用性看还是有差别的,因为RocketMQ做数据状态回传的时候应该会更快,因为不依赖其他数据载体,
因为数据载体就是broker本身,优化的更好。
5、可堆积数量
两个框架的堆积数量也不太好比较,因为TBSchedule依赖的是其他数据载体(比如数据库),
RocketMQ使用的是索引加文件几乎是无限堆积(为什么是“几乎”,自行查资料,关键取决于磁盘大小)
这里反过来对第四点做一点补充就是,堆积量上来之后对于RocketMQ性能几乎没什么影响,
但是对于TBSchedule可能就取决于数据载体了
6、稳定性
这个也不展开讨论,直接说实际使用情况
TBSchedule会有时不时的莫名其妙的假死现象
RocketMQ最多是因为硬件承载量不够而拒绝服务,但是还是能提供服务的。
大家自己心里评判吧!
可能有很多人说这两个东西是没有可比性的,因为根本就是不同的框架,一个是定时任务一个是消息传输,说的很对,但是你反过来想
都是为了处理业务数据,都是将数据从一种状态或结构转换成另一种。很多情况下两者都可以做完同样的事情,所以就带来了争论和选择
如果你那RocketMQ和操作系统linux比较我想这真的是没有可比性的。
最后还是简单总结一下
Work和MQ都是随时代或者说是技术发展的过程逐渐演变的,work是定时任务的高级扩展,MQ是伴随着业务发展而逐渐流行起来的框架设计
两者都在企业信息化发展中起到关键的作用,然而work却在逐渐慢慢消退,但是不太可能会被替代(这里不是指被MQ替代),当然更不会被MQ替代
MQ框架现在发展非常迅猛,虽然在一段时间内还会非常迅猛,同样时代在变化,技术在发展,慢慢陨落是不可避免的,只是时间问题而已。
两个框架都有自己更适合的使用场景(使用场景包括人和业务这里就不具体举例说明了),脱离业务的设计都是耍流氓。
希望本篇文章对你有帮助。