fork/join作为一个并发框架在jdk7的时候就加入到了我们的java并发包java.util.concurrent中,并且在java 8 的lambda并行流中充当着底层框架的角色。这样一个优秀的框架设计,我自己想了解一下它的底层代码是如何实现的,所以我尝试的去阅读了JDK相关的源码。下面我打算分享一下阅读完之后的心得~。
1、fork/join的设计思路
了解一个框架的第一件事,就是先了解别人的设计思路!
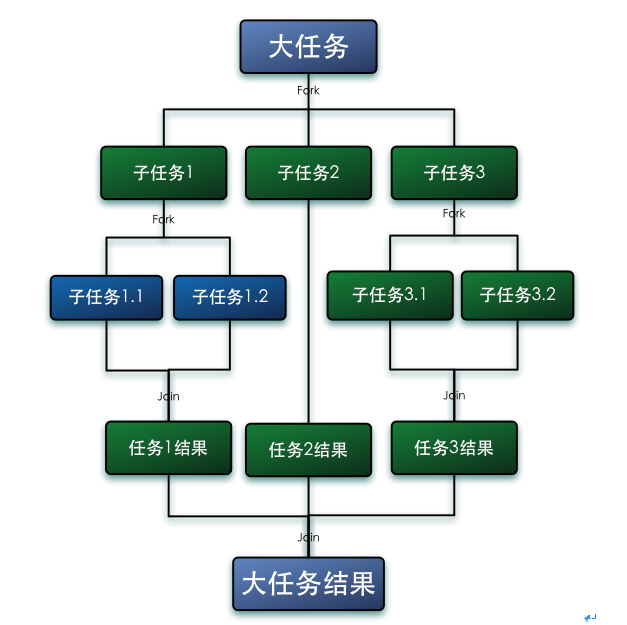
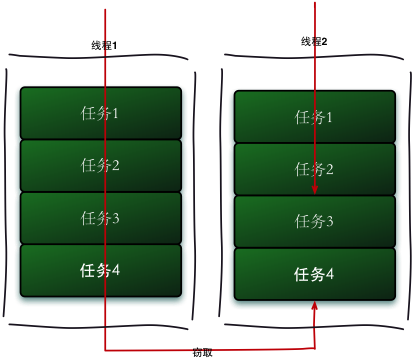
fork/join大体的执行过程就如上图所示,先把一个大任务分解(fork)成许多个独立的小任务,然后起多线程并行去处理这些小任务。处理完得到结果后再进行合并(join)就得到我们的最终结果。显而易见的这个框架是借助了现代计算机多核的优势并行去处理数据。这看起来好像没有什么特别之处,这个套路很多人都会,并且工作中也会经常运用~。其实fork/join的最特别之处在于它还运用了一种叫work-stealing(工作窃取)的算法,这种算法的设计思路在于把分解出来的小任务放在多个双端队列中,而线程在队列的头和尾部都可获取任务。当有线程把当前负责队列的任务处理完之后,它还可以从那些还没有处理完的队列的尾部窃取任务来处理,这连线程的空余时间也充分利用了!。work-stealing原理图如下:
2、实现fork/join 定义了哪些角色?。
了解设计原理,这仅仅是第一步!要了解别人整个的实现思路, 还需要了解别人为了实现这个框架定义了哪些角色,并了解这些角色的职责范围是什么的。因为知道谁负责了什么,谁做什么,这样整个逻辑才能串起来!在JAVA里面角色是以类的形式定义的,而了解类的行为最直接的方式就是看定义的公共方法~。
这里介绍JDK里面与fork/join相关的主要几个类:
ForkJoinPool:充当fork/join框架里面的管理者,最原始的任务都要交给它才能处理。它负责控制整个fork/join有多少个workerThread,workerThread的创建,激活都是由它来掌控。它还负责workQueue队列的创建和分配,每当创建一个workerThread,它负责分配相应的workQueue。然后它把接到的活都交给workerThread去处理,它可以说是整个frok/join的容器。
ForkJoinWorkerThread:fork/join里面真正干活的"工人",本质是一个线程。里面有一个ForkJoinPool.WorkQueue的队列存放着它要干的活,接活之前它要向ForkJoinPool注册(registerWorker),拿到相应的workQueue。然后就从workQueue里面拿任务出来处理。它是依附于ForkJoinPool而存活,如果ForkJoinPool的销毁了,它也会跟着结束。
ForkJoinPool.WorkQueue: 双端队列就是它,它负责存储接收的任务。
ForkJoinTask:代表fork/join里面任务类型,我们一般用它的两个子类RecursiveTask、RecursiveAction。这两个区别在于RecursiveTask任务是有返回值,RecursiveAction没有返回值。任务的处理逻辑包括任务的切分都集中在compute()方法里面。
3、fork/join初始化时做了什么
大到一个系统,小到一个框架,初始化工作往往是体现逻辑的一个重要地方!因为这是开始的地方,后面的逻辑会有依赖!所以把初始化看明白了,后面很多逻辑就容易理解多了。
下面上一段代码,(ps:这段代码是在网上找到的,并做了一小部分的修改)
public class CountTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2; //阀值
private int start;
private int end;
public CountTask(int start,int end){
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
if(canCompute){
for(int i = start; i <= end; i++){
sum += i;
}
}else{
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start,middle);
CountTask rightTask = new CountTask(middle + 1,end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到其结果
Integer rightResult = rightTask.join();
Integer leftResult = leftTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask countTask = new CountTask(1,200);
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(countTask);
System.out.println(forkJoinTask.get());
}
}
代码的执行过程解释起来也是很简单就是把[1,200],分成[1,100],[101,200],然后再对每个部分进行一个递归分解最终分解成[1,2],[3,4],[5,6].....[199,200]独