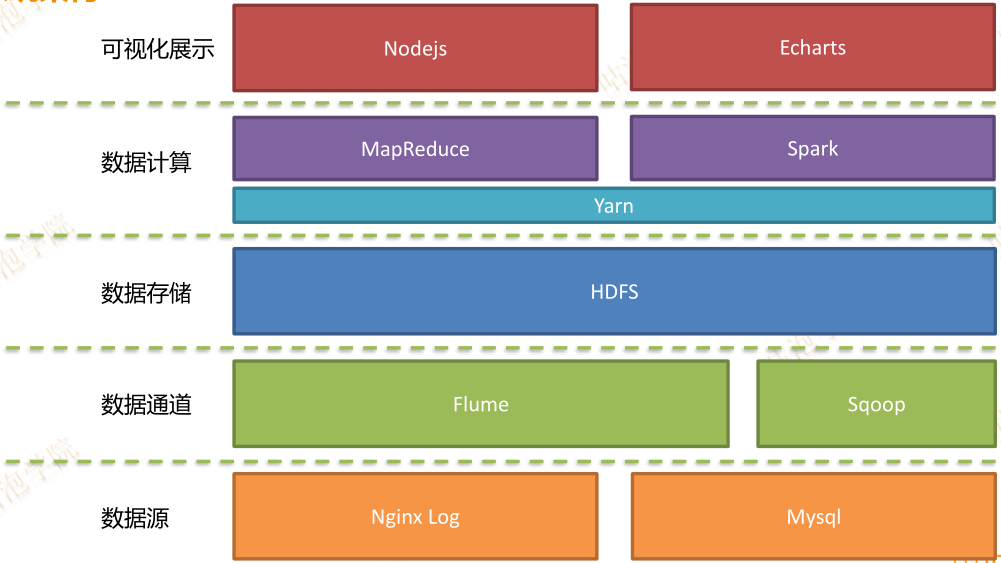
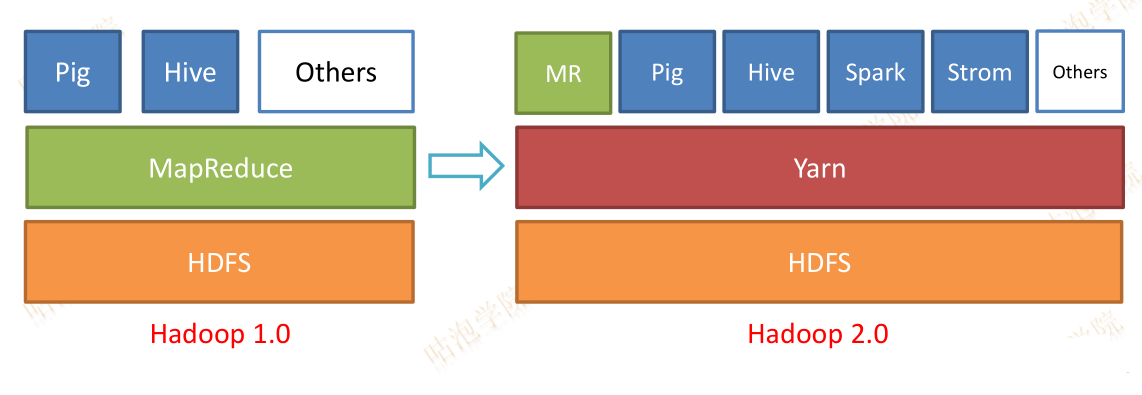
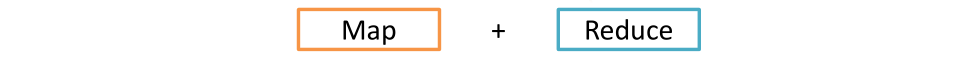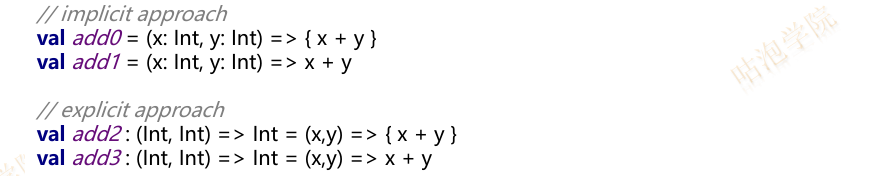版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bingdianone/article/details/88013827
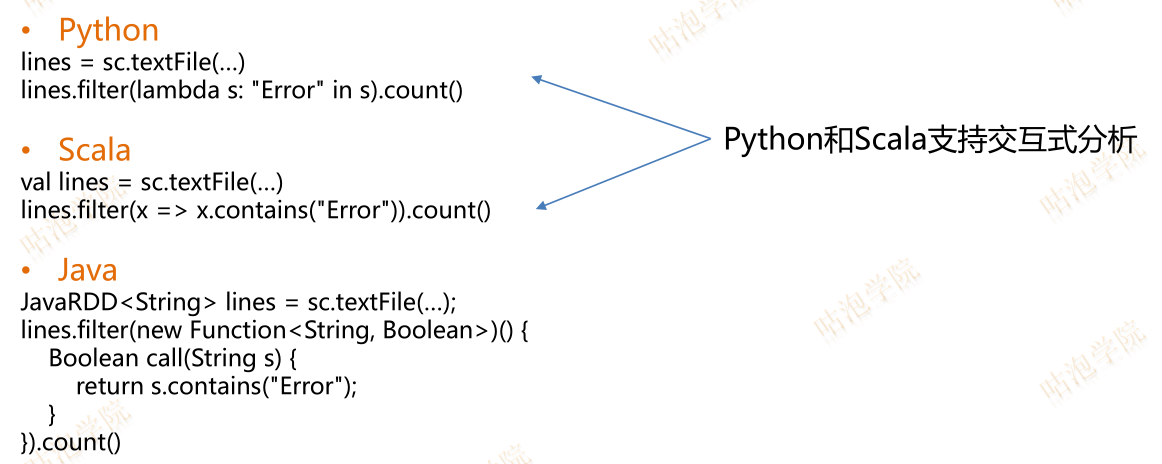
什么是Spark?
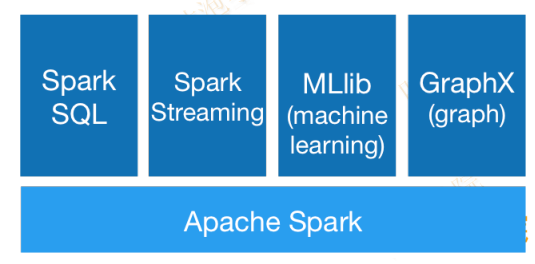
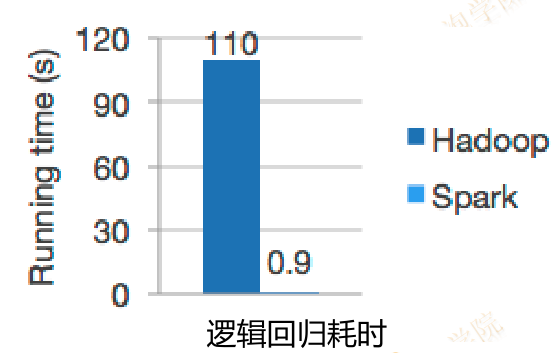
Spark是基于内存计算的通用大规模数据处理框架
Spark已经融入了Hadoop生态系统,可支持的作业类型和应用场景比MapReduce更为广泛,并且具备了MapReduce所有的高容错性和高伸缩性特点。
回顾MapReduce
并不是所有的问题都可以简单的分解成Map和Reduce两步模型处理
MapReduce缺点
Spark
一站式解决
离线批处理
流式计算
在线实时分析
MapReduce
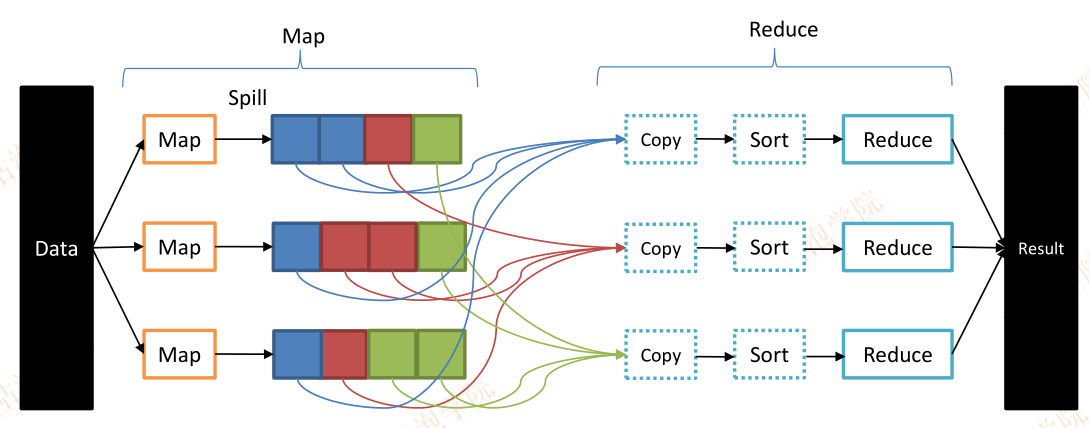
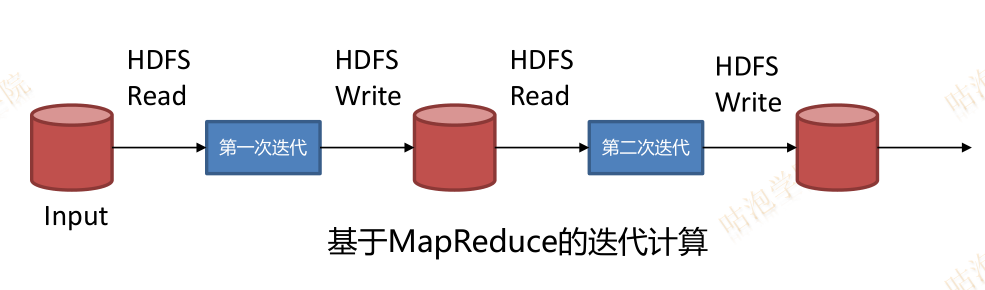
MapReduce会将中间结果输出到本地磁盘
例如Shuffle时Map输出的中间结果
有多个MapReduce任务串联时,依赖HDFS存储中间结果的输出
例如执行Hive查询
MapReduce在处理复杂DAG时会带来大量的数据copy、序列化和磁盘I/O开销
Spark
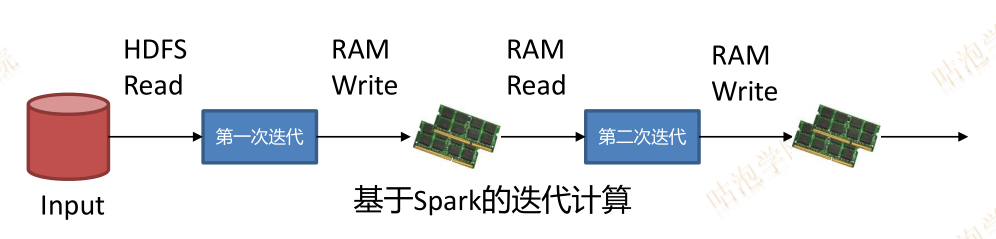
Spark尽可能减少中间结果写入磁盘
尽可能减少不必要的Sort/Shuffle
反复用到的数据进行Cache
对于DAG进行高度优化
划分不同的Stage
使用延迟计算技术
内存计算
融入Hadoop生态圈
核心代码由Scala编写
发展速度快
社区活跃
最新版本2.4.0 (截止2018年2月)
快速实验
一致性
面向对象
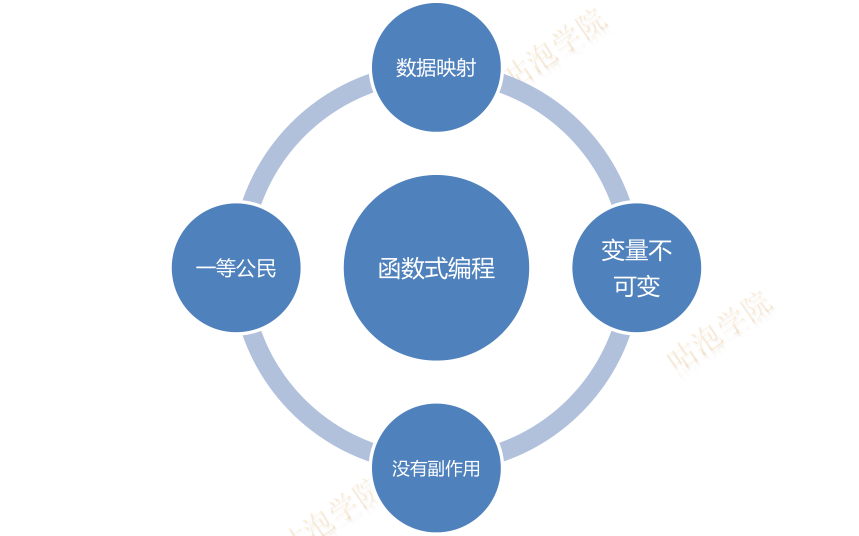
函数式编程
函数可以独立存在,可以定义一个函数作为另外一个函数的返回值,也可以接受函数作为函数的参数
异步编程
函数式编程提倡变量不可变,使得异步编程变得十分容易
基于JVM
Scala会被编译成为Bytecode,所以Scala能无缝集成已有的Java类库
val变量和var变量
val声明的变量不可变,相当于java 中的final
var声明的变量可变
在scala的类中,val会自动带有getter方法,var会自动带有getter和setter方法
Scala没有区分基本类型和包装类型,统一定义为class类。
7种数值类型+1种Boolean类型
Byte -> RichByte
Char -> RichChar
Short -> RichShort
Int -> RichInt
Long -> RichLong
Float -> RichFloat
Double -> RichDouble
在基本数据类型上使用那些没有提供的方法时,scala会尝试“隐式转换”转换成增强类型
Example
1.to (10) // 生成出Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
方法定义
格式
def 方法名(参数名: 参数类型): 返回值类型 = {
return xxx // return可省略
}
当返回值为unit时
def 方法名(参数名: 参数类型) {
// 方法体
}
无参数函数定义
def 方法名 {
// 方法体
}
Example
def m1(a: Int, b: Int): Int = {
a + b
}
def m2() = 100
def m3 = 100
函数定义
函数在scala中是一等公民
val 函数名:(参数类型1, … , 参数类型n)=>返回值类型 = (T1,…, Tn) => 函数体
val 函数名 = (参数名1: 参数类型1, … , 参数名n: 参数类型n) =>函数体
函数必须有参数列表,否则报错
方法不可以赋值给变量但是函数可以
对于一个无参数的方法是没有参数列表的,而对于函数是有一个空参数列表。
函数名后必须加括号才代表函数调用,否则为该函数本身,而方法名后不加括号为方法调用
C 操作时间为常数
eC 操作时间在满足某些假设的前提下为常数
aC该操作的均摊运行时间为常数。某些调用的可能耗时较长,但多次调用之下,每次调用的平均耗时是常数。
L 操作是线性的,耗时与容器的大小成正比。
如果在.map, .flatMap中遇到异常如何处理?
Scala提供了scala.util.Try 类型更加优雅的处理异常
如果成功返回Success
如果抛出异常返回Failure并携带异常信息
Scala继承类和java 一样使用extends关键字
可以将类、字段或者方法声明为final,确保它们不能被重写
重写一个非抽象方法必须使用override关键词
可以将类定义为abstract作为抽象类,子类中重写超类的抽象方法时不
调用超类与Java一致使用super关键词
只有主构造器才能调用超类的构造器
函数式编程关心的是数据的映射而命令式编程关心的是解决问题的步骤
函数式编程提倡
没有可变的变量
例如无论sqrt(x),这个函数的值只取决于函数的输入的值
没有类似于命令式编程中循环元素
好处
不依赖于外部的状态,也不修改外部的状态,使得代码容易推理,
由于多个线程之前不共享状态,因此不会造成资源的竞争,可以更
Spark将数据缓存在分布式内存中
如何实现?RDD
Spark的核心
分布式内存抽象
提供了一个高度受限的共享内存模型
逻辑上集中但是物理上是存储在集群的多台机器上
只读
通过HDFS或者其它持久化系统创建RDD
通过transformation将父RDD转化得到新的RDD
RDD上保存着前后之间依赖关系
Partition
基本组成单位,RDD在逻辑上按照Partition分块
分布在各个节点上
分片数量决定并行计算的粒度
RDD中保存如何计算每一个分区的函数
容错
失败自动重建
如果发生部分分区数据丢失,可以通过依赖关系重新计算
RDD.scala是所有RDD的总得抽象
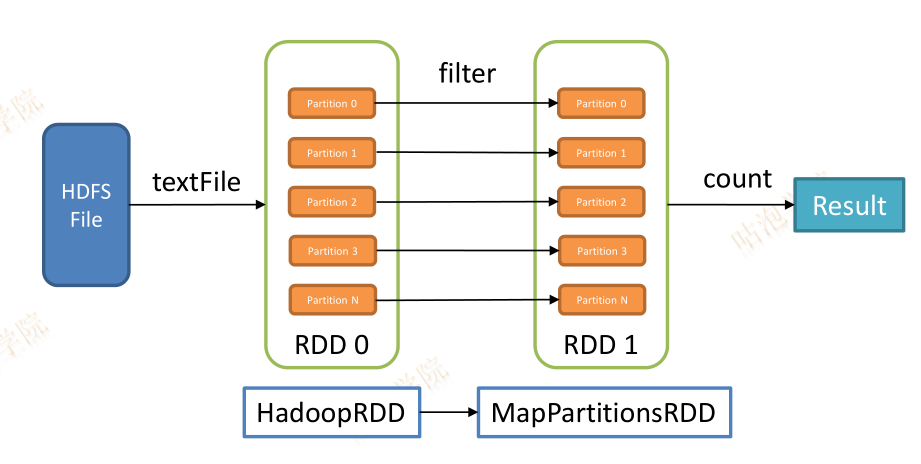
val lines = sc.textFile(…)
窄依赖
没有数据shuffling
所有父RDD中的Partition均会和子RDD的Partition关系是一对一
宽依赖
有数据shuffling
所有父RDD中的Partition会被切分,根据key的不同划分到子RDD的Partition中
什么是Stage
一个Job会被拆分为多组Task,每组Task被称为一个Stage
划分依据
以shuffle操作作为边界,遇到一个宽依赖就分一个stage
对窄依赖可以进行流水线(pipeline)优化
不互相依赖的Stage可以并行执行
存在依赖的Stage必须在依赖的Stage执行完之后才能执行
Stage并行执行程度取决于资源数
用户创建Spark程序并提交
每个Action会生成一个Job
包含了一系列RDD以及如何对其进行转换transformation
对每个Job生成DAG
Directed Acyclic Graph
对根据宽窄依赖对DAG进行划分Stage
对每一个Stage生成一组Task
一个Partition对应一个Task
Spark会以一组Task为单位进行执行计算
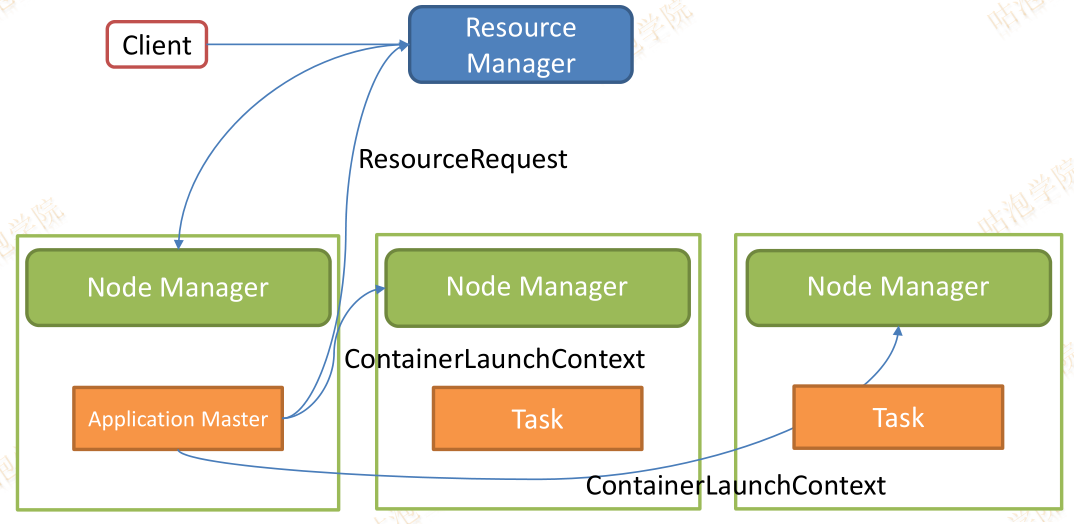
Yarn
ResourceManager:负责整个集群资源管理和分配
ApplicationMaster:Yarn中每个Application对应一个AM,负责与
NodeManager:每个节点的资源和任务管理器,负责启动Container,并监视资源使用情况
Container:资源抽象
Spark
Application:用户自己编写的Spark程序
Driver:运行Application的main函数并创建SparkContext,和ClusterManager通信申请资源,任务分配并监控运行情况
ClusterManager:指的是Yarn
DAGScheduler:对DAG图划分Stage
TaskScheduler:把TaskSet分配给具体的Executor
Spark支持三种运行模式
standalon, yarn-cluster, yarn-client
核心思想:
对于RDD有四种类型的算子
Create
SparkContext.textFile()
SparkContext.parallelize()
Transformation
作用于一个或者多个RDD,输出转换后的RDD
例如:map, filter, groupBy
Action
会触发Spark提交作业,并将结果返回Driver Program
例如:reduce, countByKey
Cache
惰性运算:遇到Action时才会真正的执行。
Example
运行Spark方式
CDH 集群上运行Spark-Shell
在Shell中输入spark-shell --master yarn-client
使用Zeppelin
使用Spark-Submit递交作业
访问官方文档:https://spark.apache.org/docs/latest/
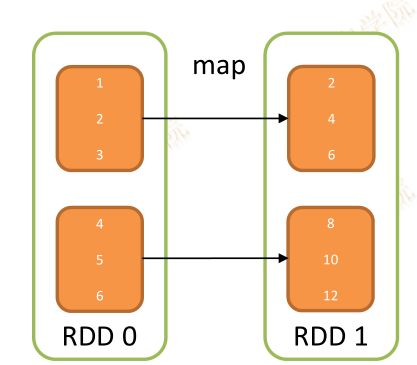
map
def map[U](f: (T) U)(implicit arg0: ClassTag[U]):RDD[U]
生成一个新的RDD,新的RDD中每个元素均有父RDD通过作用func函数映射变换而来
新的RDD叫做MappedRDD
val rd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6), 2)
val rd2 = rd1.map(x => x * 2)
rd2.collect()
rd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at
parallelize
rd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map
res1: Array[Int] = Array(2, 4, 6, 8, 10, 12)
mapPartitions
def mapPartitions[U](f: (Iterator[T]) => Iterator[U],
获取到每个分区的迭代器
对每个分区中每个元素进行操作
Example
val rd1 = sc.parallelize(List("20180101", "20180102", "20180103", "20180104", "20180105",
"20180106"), 2)
val rd2 = rd1.mapPartitions(iter => {
val dateFormat = new java.text.SimpleDateFormat("yyyyMMdd")
iter.map(dateStr => dateFormat.parse(dateStr))
})
rd2.collect()
res1: Array[java.util.Date] = Array(Mon Jan 01 00:00:00 UTC 2018, Tue Jan 02 00:00:00 UTC 2018, Wed Jan 03
00:00:00 UTC 2018, Thu Jan 04 00:00:00 UTC 2018, Fri Jan 05 00:00:00 UTC 2018, Sat Jan 06 00:00:00 UTC 2018)
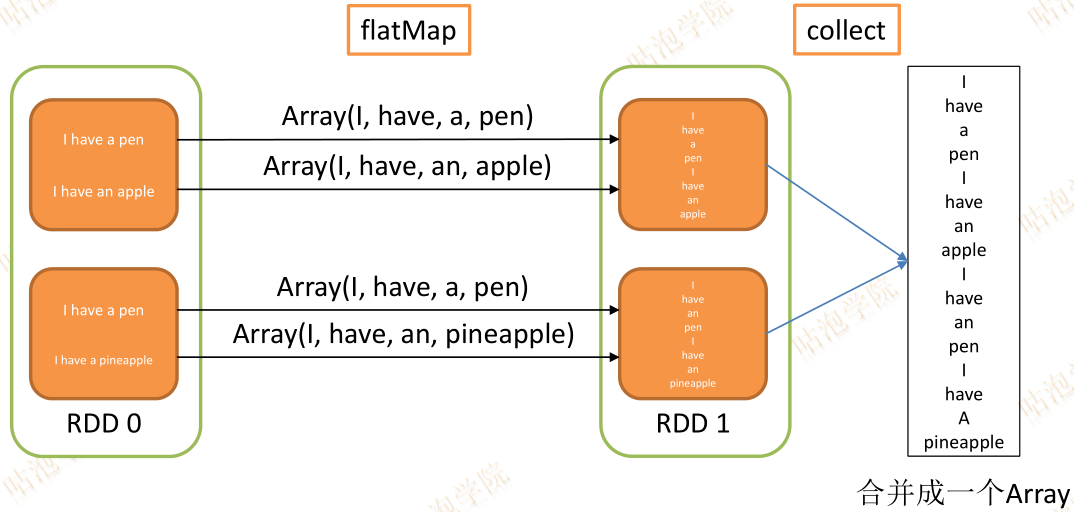
flatMap
def flatMap[U](f: (T) TraversableOnce[U])(implicit arg0: ClassTag[U]): RDD[U]
将RDD中的每个元素通过func转换为新的元素
进行扁平化:合并所有的集合为一个新集合
新的RDD叫做FlatMappedRDD
Example
val rd1 = sc.parallelize(Seq("I have a pen",
"I have an apple",
"I have a pen",
"I have a pineapple"), 2)
val rd2 = rd1.map(s => s.split(" "))
rd2.collect()
val rd3 = rd1.flatMap(s => s.split(" "))
rd3.collect()
rd3.partitions
res136: Array[Array[String]] = Array(Array(I, have, a, pen), Array(I, have, an, apple), Array(I, have, a, pen), Array(I, have,
a, pineapple))
res137: Array[String] = Array(I, have, a, pen, I, have, an, apple, I, have, a, pen, I, have, a, pineapple)
union
def union(other: RDD[T]): RDD[T]
合并两个RDD
元素数据类型需要相同,并不进行去重操作
Example
val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
val rdd3 = sc.parallelize(Seq("Durian"))
val rddUnion = rdd1.union(rdd2).union(rdd3)
rddUnion.collect.foreach(println)
res1: Array[String] = Array(Apple, Banana, Orange, Banana, Pineapple, Durian)
distinct
def distinct(): RDD[T]
对RDD中的元素进行去重操作
Example
val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
val rdd3 = sc.parallelize(Seq("Durian"))
val rddUnion = rdd1.union(rdd2).union(rdd3)
val rddDistinct = rddUnion.distinct()
rddDistinct.collect()
res1: Array[String] = Array(Orange, Apple, Banana, Pineapple, Durian)
filter
def filter(f: (T) Boolean): RDD[T]
对RDD元素的数据进行过滤
当满足f返回值为true时保留元素,否则丢弃
Example
val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
val filteredRDD = rdd1.filter(item => item.length() >= 6)
filteredRDD.collect()
res1: Array[String] = Array(Banana, Orange)
interesction
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]
对两个RDD元素取交集
Example
val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
val rddIntersection = rdd1.intersection(rdd2)
rddIntersection.collect()
res1: Array[String] = Array(Banana)
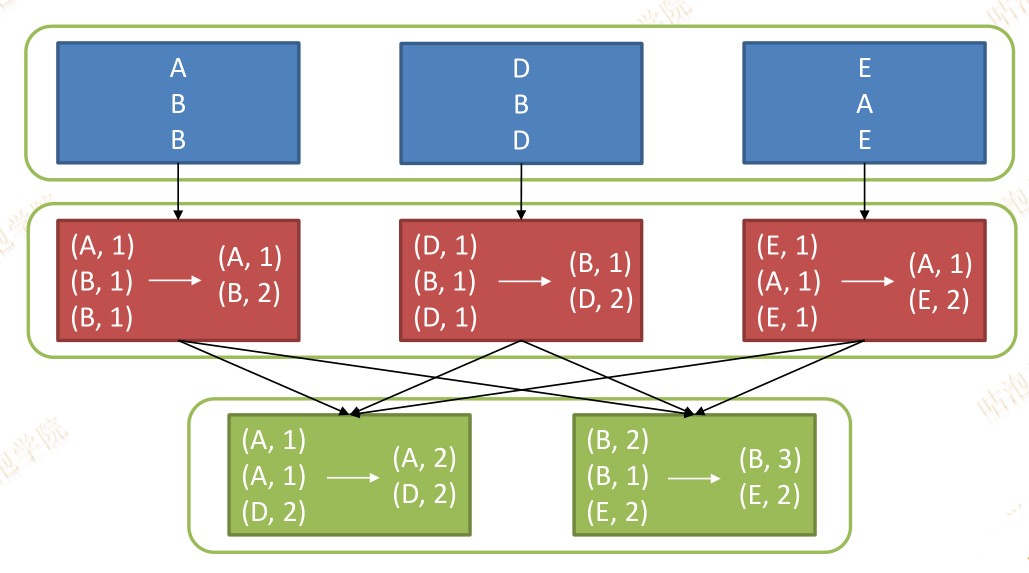
groupByKey
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
对RDD[Key, Value]按照相同的key进行分组
Example
val scoreDetail = sc.parallelize(List(("xiaoming","A"), ("xiaodong","B"),
("peter","B"), ("liuhua","C"), ("xiaofeng","A")), 3)
scoreDetail.map(score_info => (score_info._2, score_info._1))
.groupByKey()
.collect()
.foreach(println(_))
scoreDetail: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[110] at parallelize
(A,CompactBuffer(xiaoming, xiaofeng))
(B,CompactBuffer(xiaodong, peter))
(C,CompactBuffer(lihua))
reduceByKey
Example
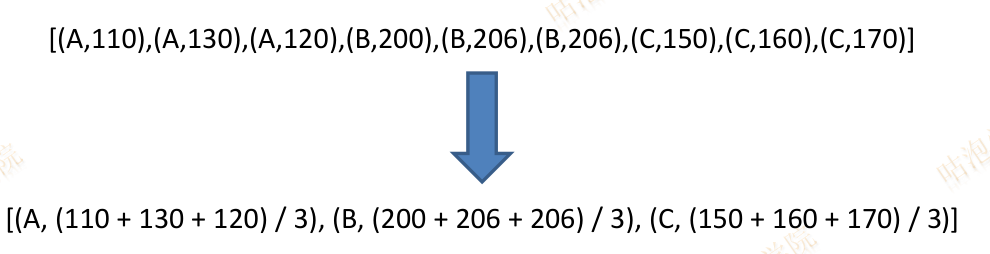
如何分组计算平均值?
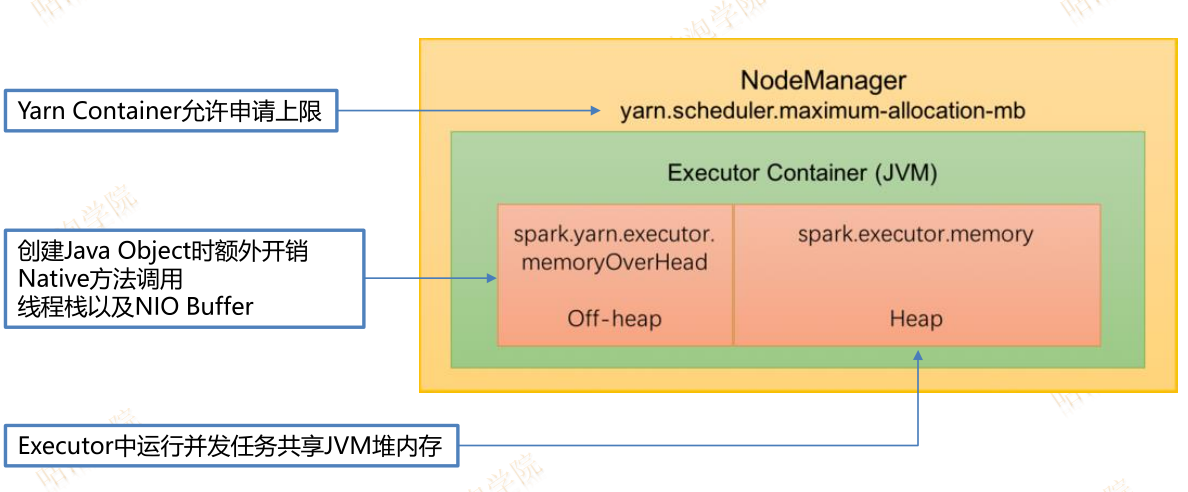
Executor最大任务并行度
TP = N/C
其中N=spark.executor.cores, C=spark.task.cpus
任务以Thread方式执行
活跃线程可使用内存范围(1/2n, 1/n) why?
出现Executor OOM错误(错误代码137,143等)
原因:Executor Memory达到上限
解决办法:
增加每个Task内存使用量
增大最大Heap值
降低spark.executor.cores数量
或者降低单个Task内存消耗量
每个partition对应一个任务
非SQL类应用 spark.default.parallism
SQL类应用 spark.sql.shuffle.partition
通过sc.textFile()读入日志文件
按分隔符切分每行日志文件提取元素
filter无法识别的URL
以pageId为Key,并使用reduceByKey进行聚合操作
通过sc.textFile()读入日志文件
按分隔符切分每行日志文件提取元素
filter无法识别的URL,以pageId和uid作为联合Key
对Key进行去重操作,使用reduceByKey进行聚合操作
步骤1:map+filter
过滤无效日志
解析product_id和uid
步骤2:mapPartitions
解析日志中的时间
Date String Format -> Long
步骤3:groupByKey + flatMap
根据uid进行分组
组内对于(product_id, visit_time)集合按照时间升序排序
依次计算时间差作为页面停留时间
步骤4:map + aggregateByKey + mapValues
(uid, (product_id, duration)) 转换成 (product_id, duration)
计算平均值
什么是DataFrame
以RDD为基础的分布式数据集,类似于传统数据库中的表
在RDD基础上引入了Schema元信息
DataFrame所表示的二位数据集每一列都带有名称和类型
借助DataFrame API提供了jdbc方法保存数据