hive中执行了select count(1) from table 后,一直无反应。
我部署了一个节点的hadoop(2.6.0)伪分布式系统,然后部署了hive,启动了hadoop和hive之后,通过命令
# hive --service cli 进入hive的客户端,
然后执行一个查询 show tables;
hive_focus
显示有这个表,然后我执行 select * from hive_tables;
可以查出数据
但是,当我执行 select count(1) from hive_tables;之后,查询一直停留在这里
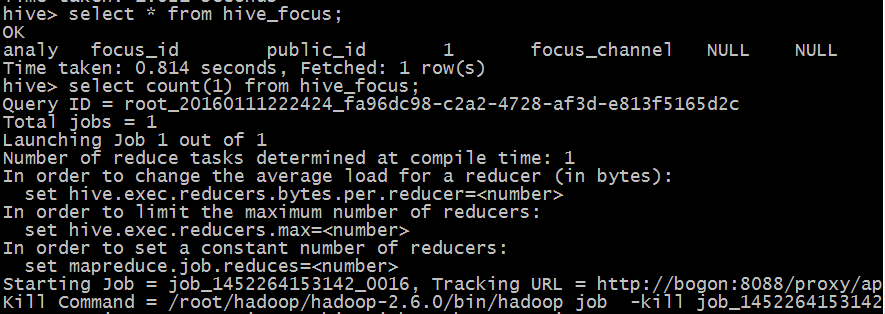
我只有一个节点,一条数据,按理说不可能一直不往下执行啊,求各位大神指点一下,刚研究hadoop,不太明白
解决方案:
启动了hadoop后,启动了hive,
进入hive-cli,执行 select count(1) from table,屏幕显示到kill command后不继续执行,
经过问题排查,解决思路如下:
1. select * from table 没有问题,但一旦执行select count(1) from table 后就不继续执行,原因是
select * from table 是直接在hive数据库中直接执行的,select count(1) from table 确实调用了mapreduce来执行。
2. 那么调用了mapreduce 之后为什么就停留在那里了呢,直接执行了官网的mapreduce的wordcount后发现相同的情况。
3. 经过上述排查,那么肯定是hadoop配置不对了,由于mapreduce的都是在datanode上执行的,所以初步认定为namenode
和datanode之间没有联通。
4. 于是检查 namenode的hosts文件和slave文件,修改为对应的主机名及ip之后,重新运行wordcount,成功。
5. 重新运行hive select count(1) from table 后,成功。
故,由此得出结论,当mapduce运行不下去的情况,则主要检查namenode和datanode之间的通信情况,包括但不限于以下几种:
1. hosts配置问题,没有把datanode的主机名写入namenode主机的hosts文件中。
2. slave配置问题, 没有把datanode的主机名写入namenode主机的slave文件中。
3. ssh无密码访问没有配置。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
下面是其他解决思路:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2016/01/11 15:13
当select * from 全表时候 不会执行mapreduce 也就不会消耗内存与CPU,count(1)的时候就在创建job 如果一直卡在那里不动的话~先看下你jps的几个进程是否正确。在就是你机器配置不够~~亲~~
2016/09/14 13:40
其实看你的描述,应该是你前期的检查不足导致的。
1)hadoop伪分布式搭建好后,使用hadoop dfsadmin -report可以查看,是否所有的节点都已经成功启动。
2)使用jps查看进程,应该会有datanode,nodemanger,namenode,secondrynamenode,resourcemanger这些进程,如果缺少那一个的话,那证明hadoop环境没有成功启动
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如图,hive提交查询的时候,在这步卡主不动假死,也不报错,log也查不出来。
查了各种办法也没解决。
最后反思
1.不借助hive进行分析时候,仅仅是提交job跑mr没有问题
2.到hive上却假死
怀疑是Hive没有连接上mapreduce。一检查hive-env.sh果然是这样。
配置hive-env.sh:
HADOOP_HOME=/apps/hadoop
export HIVE_CONF_DIR=/apps/hive/conf
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
I was finally able to get this to work by increasing theyarn.nodemanager.resource.memory-mb value from 1 GB (the default) to 6 GB. Apparently this is a resource issue, but there are no warnings that I could find that state this clearly.
---------------------
参考自:
https://www.oschina.net/question/1386516_2148428
https://blog.csdn.net/wmlove_hqy/article/details/78819023
https://community.cloudera.com/t5/Cloudera-Manager-Installation/Hive-hangs-at-kill-job-command/td-p/26248