1����װubuntu10.04
Ϊ�˲����ļ�㣬�����л����ϴ�����ͬ�û�������ͬ������û���������������ͬ���û�ibm��
�Ļ�������$ hostname��������(ע������ubuntu����hostname���Ϊԭ����Ĭ��ֵ�������������Ժ�ǵð�hostname�Ļ�����������������õ�/etc/hosts�ļ���һ�£�)
��/etc/hosts�����ӻ���������Ӧ��IP��
127.0.0.1 localhost
125.216.227.182 ibm
125.216.227.53 ibm00
2������ssh����
ע�⣺�Զ���װopenssh-serverʱ����Ҫ����sudo apt-get update������
��װopenssh-server��$ sudo apt-get install openssh-server
3������ssh�������¼
(1)��NameNode��ʵ���������¼������
$ ssh-keygen -t dsa -P ''-f ~/.ssh/id_dsa��
ֱ�ӻس�����ɺ����~/.ssh/���������ļ���id_dsa��id_dsa.pub���������dzɶԳ��֣�����Կ������
�ٰ�id_dsa.pub�ӵ���Ȩkey����(��ǰ��û��authorized_keys�ļ�)��
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys��
��ɺ����ʵ���������¼������$ ssh localhost��
(2)ʵ��NameNode�������¼����DataNode����������DataNode�������¼NameNode������
��NameNode�ϵ�id_dsa.pub�ļ��ӵ�dataNode��authorized_keys��(��125.216.227.182�ڵ�Ϊ��)��
a.����NameNode��id_dsa.pub�ļ���
$ scp id_dsa.pubibm@125.216.227.53:/home/ibm/
b.��¼125.216.227.53��ִ��$
cat id_dsa.pub >> .ssh/authorized_keys
������dataNodeִ��ͬ���IJ�����
4���رշ���ǽ
$ sudo ufw disable
ע�⣺�ⲽ�dz���Ҫ��������رգ�������Ҳ���datanode���⡣
5����װjdk1.6
��ubuntuĬ�ϵ�Դ�У������ҵ���jdkΪopenjdk����������1.6�ģ�����ʹ��
$sudo apt-cache search jdk��ѡ�б���Ȼ��װ
��װ����JAVA 1.6.20
$sudo apt-get install openjdk-6-jre openjdk-6-jdk
Ȼ�����û���������
vi/etc/profile
�������������£�
export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
�����˳���
����ubuntu��
ʹ��������ԣ�
$java -version
ע�⣺ÿ̨������java�������һ�¡�
6����װhadoop
����hadoop-0.20.2.tar.gz��
��ѹ��$ tar �Czvxf hadoop-0.20.2.tar.gz
��Hadoop�İ�װ·�����ӵ���/etc/profile��:
export HADOOP_HOME=/home/ibm/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
7������hadoop
hadoop����Ҫ���ö���hadoop-0.20.2/conf�¡�
(1)��conf/hadoop-env.sh������Java����(namenode��datanode��������ͬ)��
$ vim hadoop-env.sh
$ export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk
(2)����conf/masters��conf/slaves�ļ�:(ֻ��namenode������)
masters: 125.216.227.182
slaves:125.216.227.53
(3)����conf/core-site.xml, conf/hdfs-site.xml��conf/mapred-site.xml(�����ã�namenode��datanode��������ͬ)
core-site.xml:
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/ibm/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://125.216.227.182:9000</value>
</property>
</configuration>
hdfs-site.xml:( replicationĬ��Ϊ3��������ģ�datanode������̨�ͻᱨ��)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>125.216.227.182:9001</value>
</property>
</configuration>
{
namenode��datanode������һ����ֻ��datanode������master��slave,����core.xml��mapred-site.xml��valueֵ��Ҫ���namenode��ip��ַ��
��
8������hadoop
����hadoop-0.20.2/bin�����ȸ�ʽ���ļ�ϵͳ��$ hadoop namenode �Cformat
{
�����������������hadoop namenode �Cformat������bash: hadoop���Ҳ�������;�����hadoop�ļ�����������bin/hadoop
namenode -format�Ϳ��Ը�ʽ���ˡ�
��
����Hadoop��$ start-all.sh
ͨ��jps����鿴��ǰ��Ϣ��
��. zookeeper�İ�װ����
zookeeper�İ�װ���ñȽϼ����ء���ѹ��/home/ibm/zookeeperinstall����zookeeperinstallĿ¼�´���dataĿ¼�����zookeeper�����ݣ�������Ҫ���õľ���/zookeeper/conf�µ�zoo.cfg�����ļ���zookeeper���ֻ��zoo.sample.cfg���������Ϊzoo.cfg��Ȼ�����ã�
��ֻ�迼��dataDir��clientPort���ԣ�
�ο����˵Ľ̳�����Ϊ��
# the directory where the snapshot is stored.
dataDir=/home/ibm/zookeeperinstall/data
# the port at which the clients will connect
clientPort=2222
�����Ϊ����Ҫ���õ��Ǽ�Ⱥ��������Ҫ��zoo.cfg������
server.1=125.216.227.182:2888:3888
server.2=125.216.227.53:2888:3888
���еȺ����1,2�Ǵ������ǵڼ���zookeeper��Ҳ��������id�����ǻ���Ҫ��ÿ̨�����ϵ�dataĿ¼�´���һ���ļ�myid�������ݼ�Ϊ��ip��Ӧ��id���Ⱥ��ұ�����Ϊ����ip��ͨ�Ŷ˿ڣ�ѡ��leader�˿ڣ�ע����ϸ����û�о�����
��. HBase��װ����
����hbase-0.90.6.tar.gz����ѹ��/home/ibm������mv����Ŀ¼��Ϊhbase��
��ʼ��Ⱥ���ã�
1����conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk
export HBASE_CLASSPATH=/home/ibm/hadoop/conf
export HBASE_MANAGES_ZK=false
2����hbase-site.xml��������������
<property>
<name>hbase.rootdir</name>
<value>hdfs://ibm:9000/hbase</value>(ע��������hadoop-config/core-site.xml�е�fs.default.name����һ�£�����ò�Ʊ���Ҫ��ibm����������ip��ַ����ʼ����ip��ַ�����濴logs�ŷ��������������
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>(ע������Ķ˿���Ҫ��zookeeper�Ķ˿�����ֵһ����
<description>Property from ZooKeeper's config zoo.cfg.</description>
</property>
3����/home/frank/HadoopInstall/hadoop-config/hdfs-site.xml�ļ�������hbase��conf�ļ�����
4����${ZOOKEEPER_HOME}/conf/zoo.cfg������hbase��conf�ļ�����
5����conf/regionservers������hadoop-config/conf/slaves�����е�datanode�ڵ㡣
6��ɾ��/hbase-0.90.2/lib/hadoop-core-0.20-append-r1056497.jar
����/hadoop-0.20.2/hadoop-0.20.0-core.jar��/hbase-0.90.2/lib/
7��������úõ�hbase-0.20.2�������������ڵ�scp
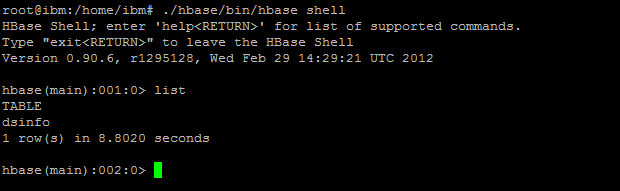
���������������þ�����ˣ���namenode������hadoop��Ⱥ��������ÿ̨����������zookeeper���������hbase����./hbase/conf/hbase shell����hbase��shell�����У�����status�鿴��ǰ��״̬������������������˵����Ⱥ���óɹ���
��. һ��HBase��Java�ͻ���ʵ��
������������window7��myeclipse��
��1������hbase-0.90.6-tar.gz
��2������һ��java project������HBaseClient��������ѹ�õ���hbase-0.90.6.jar,hbase-0.90.6-tests.jar���ӵ�build path��
��3���½�hbase-site.xml���������ͬ��hbase�����ļ�����Ҳ�У���Ҫ�������ӵ����̵�classpath�У�Ҳ����srcƽ�У�������Ϊ����Ĵ����г�ʼ������ʹ�õ���HBaseConfiguration.create()�����������hbase��apiʹ��˵��������ôһ��ע�ͣ���You
need a configuration object to tell the client where to connect.When you create a HBaseConfiguration, it reads in whatever you've setinto
your hbase-site.xml and in hbase-default.xml, as long as these canbe found on the CLASSPATH����
�����������ļ�Ϊ��
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://125.216.227.182:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
<description>property from zookeeper zoo.cfg.</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>125.216.227.182,125.216.227.53</value>
</property>
<property skipInDoc="true">
<name>hbase.defaults.for.version</name>
<value>0.90.6</value>
</property>
</configuration>
��4���½���MyHBaseClient����hbase�д���һ���ı�dsinfo����������Ϊ��
public class MyHBaseClient {
private static Configuration conf = null;
static {
conf = HBaseConfiguration.create();
}
/**
* create table
* @param args
*/
public static void createTable(String tablename,String []cfs)throws IOException{
HBaseAdmin admin = new HBaseAdmin(conf);
if(admin.tableExists(tablename)){
System.out.println("table has existed.");
}
else{
HTableDescriptor tableDesc = new HTableDescriptor(tablename);
for(int i=0;i<cfs.length;i++){
tableDesc.addFamily(new HColumnDescriptor(cfs[i]));
}
admin.createTable(tableDesc);
System.out.println("create table successfully.");
}
}
public static void main(String []args){
try{
createTable("dsinfo", new String[]{"publish","mark"});
}catch(IOException e){
e.printStackTrace();
}
}
}
�������hbase���dsinfo����
��������ܳ��ֵĴ����У���1��hbase-site.xml�ļ����ò��ԣ���������Ҫ����zookeeper�ĵ�ַ��Ϣ�ģ���Ȼ�Ҳ���hbase����2��dns������ibm��ibm00�����Ǽ�Ⱥ�е�hostname����Ϊ����window�ϱ�̣�������Ҫ��ip��hostname����Ϣ���ӵ�window��hosts�ļ��У��������dns�������Ĵ���