1.下载编译flume-ng-sql-source 下载地址:https://github.com/keedio/flume-ng-sql-source.git
安装说明文档编译和拷贝jar包
2.编写flume-ng 配置文件
1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://172.16.43.21:3306/test
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = hadoop
a1.sources.src-1.hibernate.connection.password = hadoop
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path = /home/hadoop/export/server/apache-flume-1.7.0-bin
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query = select `id`, `str` from json_str where id > $@$ order by id asc
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testuser
a1.sinks.k1.brokerList = test0:9092,test1:9092,test2:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1
a1.sinks.k1.channel = ch-1
a1.sources.src-1.channels=ch-1
3.遇到的问题
mysql中的内容采集到kafka中之后会多出来很多双引号
mysql数据格式:
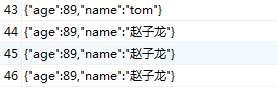
kafka数据格式:
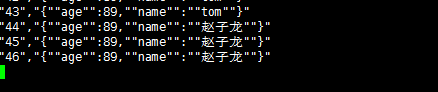
用storm对kafka中的数据进行格子整理
