目录
发表日期:2019年9月18日
什么是ElasticSearch
ElasticSearch是一个集数据存储、数据搜索和数据分析为一体的系统。它是分布式的,所以能利用分布式来提高其处理能力,具有高可用性和高伸缩性。如果你需要一个能够提供高性能的搜索服务的系统,那么它或许是一个好的选择。
- 数据存储:是指它能够以JSON格式来存储数据。如果你不在意数据的搜索,你甚至可以像类似使用mongodb那样来单纯把它作为一个数据存储系统使用。
- 数据搜索:是指它能够对JSON格式的数据进行全文检索等搜索。
- 数据分析:是指它能够利用一些算法来对JSON文档数据进行分析,比如得出某个月的商品销售增长量。
核心能力
ElasticSearch是一个搜索系统,搜索就是从数据集合中搜索出我们想要的数据,例如从大量的商品数据中搜索出我们想要的某类商品。
现在提一个需求,例如我有一个“文章”的表,我想搜索文章表中字段content中包含有'java'的数据。
如果你不使用ES,那么从开发角度来说,平常我们都是使用关系型数据库系统来存储数据,然后使用类似select name,age,address from student where name like '%李%'的语句通过模糊匹配来搜索符合指定条件的数据的。(对应到上面的需求应该是select name,author,content from article where content like '%java%')但其实上面这种基于模糊匹配的搜索方式的效率是比较低的,因为数据库系统的搜索通常是逐一扫描的,也就是从头到尾的来尝试匹配,某个字段的数据越多,可能需要尝试匹配的次数就会越多(试想一下从4000字的文章中从上到下只为找到一个字),这种查找就好像最低级的遍历查找(当然并不是真的就是傻傻的遍历了,各个数据库系统都会采用各种算法来优化)。
而ElasticSearch由于其内部建立了每个词的索引表,当搜索某个词时,可以根据这个词从索引表中找到匹配的记录,所以效率比较高(就好像记录了某个词的坐标,有了坐标,就能根据坐标非常快地找到那个词)。
(这里举个类似的栗子:相信大家都用过字典,那么普通的数据库搜索就好像从第一页到最后一页找一个词,而ElasticSearch根据这个词的部首结构从“部首-字的对应表”中直接查找到那个字的页数,这个效率直接就是天差地别了!)另外,数据库的搜索是根据指定词直接查找的,它是很笨的!它不能查找到某些意义上“类似”的结果,比如我搜索“mother”,但如果某个记录中包含“mom”这个词,那这条记录也应该被展示出来,而数据库的普通搜索做不到。
而这个操作ElasticSearch就可以做到,由于它内部有分词器,在建立索引的过程中,分词器可以把数据中的某些词都认为是指定的某一个词(比如把mother,mom通通都使用mom作为索引词),再用这个词来建立索引,然后在进行搜索的时候,将输入的词也进行同样的转化,再根据这个词从索引表中查找到符合的记录结果,这样就可以把那些意义相近的结果也搜索出来。所以说,ElasticSearch解决了普通全文搜索的搜索效率低下和搜索不智能的问题。
ES的搜索核心
介绍两个搜索方法:顺序扫描查找、全文搜索
上面有说到数据库的搜索和ElasticSearch的搜索。
常见的关系型数据库的针对某个字段中的数据的搜索是顺序扫描查找,从头到尾去尝试匹配,也就是所谓的遍历查找,当然算法可能没有那么低级。(现在一些数据库系统也在尝试优化全文搜索功能。)而ElasticSearch的搜索是全文搜索,而什么是全文搜索?
全文搜索可以根据一定方式把非结构化的数据对应到一种结构化的标识,从而可以通过标识来检索到指定的非结构化的数据记录。
这句话可能有点难以理解,举个例子理解,比如有一大堆食物你需要去认识,食物本身可以被认作是非结构化的数据,因为他们都是独特的,但如果我们利用他们的颜色来划分的话就可以初步地将他们进行结构化划分,这个就是一种简单的将数据结构化的手段。在ElasticSearch中,这个把非结构化的数据对应到一种结构化的标识的方式就是倒排索引,下面介绍倒排索引来理解这个概念。在ElasticSearch中,处理这些非结构化的数据的方式就是建立倒排索引(Inverted Index)。
什么是倒排索引呢?
倒排索引把数据进行了拆分(比如某个字段的数据为hello world,那么就会被拆分成hello和world),我们使用这些拆分的词来作为索引词来建立索引表,在以hello为索引词的记录中,有对hello world的指向,world也是如此。
当然,这里的拆分并不是真实的拆分,原始的数据依然存储在elasticsearch中,我们另外创建了一个索引文件来存储。下面是一个使用倒排索引搜索的示例
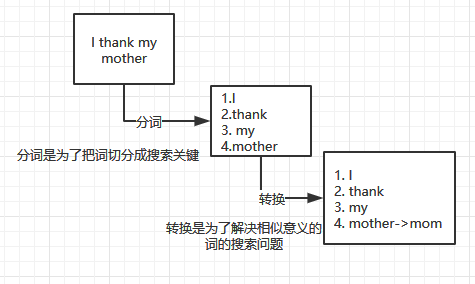
1.首先,假设我们有一个字段的数据是"I thank my mother",当我们把这个数据存储到ElasticSearch中,ElasticSearch内部使用分词器进行处理数据,分词器用于将非结构化数据中的词进行拆分和转换,于是把"I thank my mother"拆解成了"I"、"thank"、"my"、"mother"。
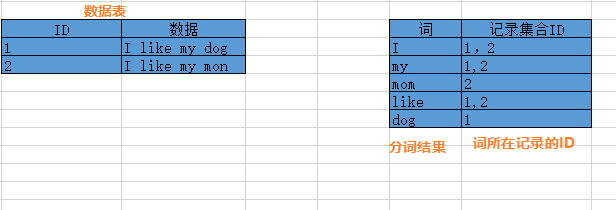
2.当把数据拆分出来后(拆分成的数据单位我们称为“词”),就会把这些词建立索引,ElasticSearch内部有一个索引表,用于建立词与数据的对应,结构类似如下(真实格式还会有词的频率、数据长度等信息),索引表存储了词和词所在记录的ID集合,所以可以通过某个词来快速搜索出相关的记录,比如搜索"I",那么会返回1和2,然后可以快速根据ID来获取对应的数据。【请注意,下图只是方便理解,并不是真实的格式】
3.然后我们搜索的时候,分词器也先把我们输入的内容处理(为了与索引表的词统一),然后再从索引表中查找,返回对应的数据记录集合。
例如我输入mother,mother会先转成mom,然后从索引表中找到mom,返回包含mom的记录的ID,然后根据ID获取对应数据,也就是“I like my mom”
搜索引擎选择
Lucene也是一种搜索引擎,为什么不直接使用Lucene?
ElasticSearch实际上底层使用的就是Lucene,虽然Lucene也有很多功能,但Lucene的使用难度较大(也正是使用难度高所以ElasticSearch才对Lucene进行封装),而且ElasticSearc的高级功能也很强大,ES支持了多样的数据分析。除了基本的功能,集群能力也是一个问题,Lucene一开始没