前言
在上一篇中介绍了ElasticSearch集群和kinaba的安装教程,本篇文章就来讲解下 ElasticSearch的DSL语句使用。
ElasticSearch DSL 介绍
Elasticsearch提供了基于JSON的完整查询DSL(特定于域的语言)来定义查询。将查询DSL视为查询的AST(抽象语法树),它由两种子句组成:
- 叶子查询子句:
叶查询子句中寻找一个特定的值在某一特定领域,如 match,term或 range查询。这些查询可以自己使用。 - 复合查询子句
复合查询子句包装其他叶查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或dis_max查询),或更改其行为(例如 constant_score查询)。
查询子句的行为会有所不同,具体取决于它们是在 查询上下文中还是在过滤器上下文中使用。
我们在使用ElasticSearch的时候,避免不了使用DSL语句去查询,就像使用关系型数据库的时候要学会SQL语法一样。如果我们学习好了DSL语法的使用,那么在日后使用和使用Java Client调用时候也会变得非常简单。
ElasticSearch DSL 语句使用
这里我们先来介绍下DSL 语句简单的使用,从最常用的增删改查开始!
一、新增数据
ElasticSearch可以直接新增数据,只要你指定了index(索引库名称)和type(类型)即可。在新增的时候你可以自己指定主键ID,也可以不指定,由 ElasticSearch自身生成。
新增数据命令示例:
POST test1/_doc/1
{
"uid" : "1234",
"phone" : "12345678909",
"message" : "qq",
"msgcode" : "1",
"sendtime" : "2019-03-14 01:57:04"
}kinaba示例图:
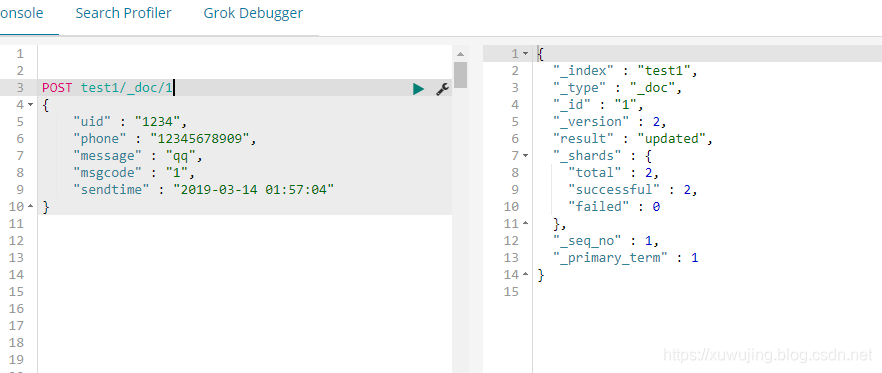
**注: POST test1/_doc/1 这是指定主键ID为1,如果POST test1/_doc 的话,那么便是es自身生成ES语句。**
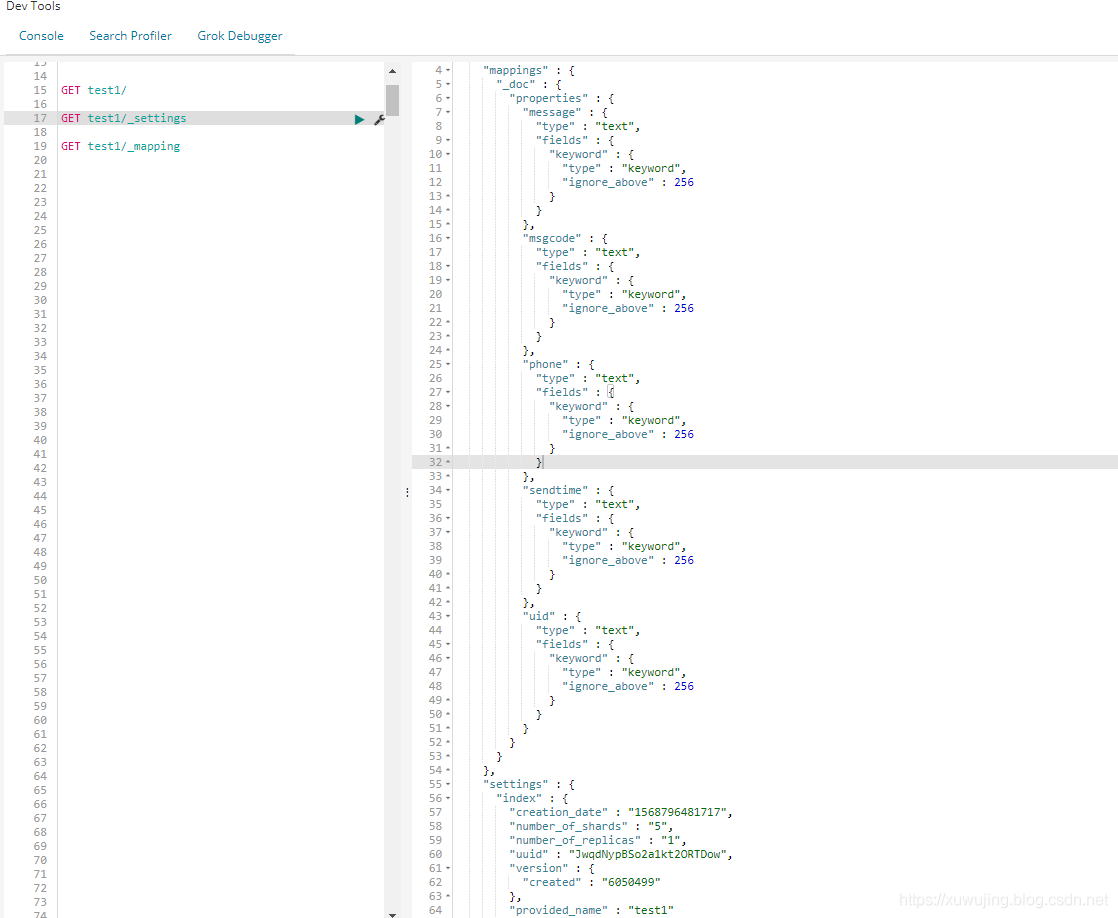
这里我们还可以通过 GET test1/ 或 GET test1/_settings和GET test1/_mapping查看该index的状态,也就是 setting(设置选项) 和mapping(数据结构)。
二、创建索引库
在上述示例中,我们通过直接通过创建数据从而创建了索引库,但是没有创建索引库而通过ES自身生成的这种并不友好,因为它会使用默认的配置,字段结构都是text(text的数据会分词,在存储的时候也会额外的占用空间),分片和索引副本采用默认值,默认是5和1,ES的分片数在创建之后就不能修改,除非reindex(下面会讲到),所以这里我们还是指定数据模板进行创建。
这里先简单介绍一下ES的数据结构,以下的数据结构为ES的6.x版本。
- 核心数据类型
text 和 keyword - 数值数据类型
long,integer,short,byte,double,float,half_float,scaled_float - 日期数据类型
date - 布尔数据类型
boolean - 二进制数据类型
binary 范围数据类型
integer_range,float_range,long_range,double_range,date_range- 复杂数据类型编辑
- 对象数据类型
object 用于单个JSON对象 嵌套数据类型
nested 用于JSON对象数组- 地理数据类型编辑
- 地理位置数据类型
geo_point 纬度/经度积分 地理形状数据类型
geo_shape 用于多边形等复杂形状- 专业数据类型编辑
- IP数据类型
ip 用于IPv4和IPv6地址 - 完成数据类型
completion 提供自动完成建议 - 令牌计数数据类型
token_count 计算字符串中令牌的数量
mapper-murmur3
murmur3 在索引时计算值的哈希并将其存储在索引中
mapper-annotated-text
annotated-text 索引包含特殊标记的文本(通常用于标识命名实体) - 渗滤器类型
接受来自query-dsl的查询 - join 数据类型
为同一索引内的文档定义父/子关系 别名数据类型
为现有字段定义别名。多字段编辑
为不同的目的以不同的方式对同一字段建立索引通常很有用。例如,一个string字段可以映射为text用于全文搜索的字段,也可以映射为keyword用于排序或聚合的字段。或者,您可以使用standard分析仪, english分析仪和 french分析仪索引文本字段。
这是多领域的目的。大多数数据类型通过fields参数支持多字段。
上面介绍的字段介绍虽然比较复杂,但是我们常用的几个类型也就是这几种 text、keyword、byte、short、integer、long、float、double、boolean、date,其中text和keyword都是string类型,选择区分很简单,需要进行分词用text,不需要并且进行排序或聚合的可以用keyword。
关于ES的数据结构就到这里了,我们来进行索引库的创建吧!
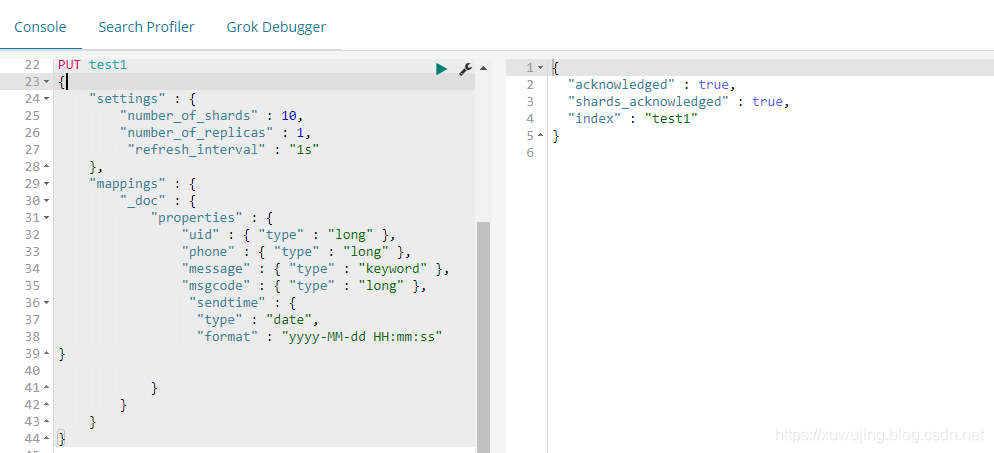
新增索引库的命令示例:
PUT test1
{
"settings" : {
"number_of_shards" : 10,
"number_of_replicas" : 1,
"refresh_interval" : "1s"
},
"mappings" : {
"_doc" : {
"properties" : {
"uid" : { "type" : "long" },
"phone" : { "type" : "long" },
"message" : { "type" : "keyword" },
"msgcode" : { "type" : "long" },
"sendtime" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss"
}
}
}
}
}示例图:
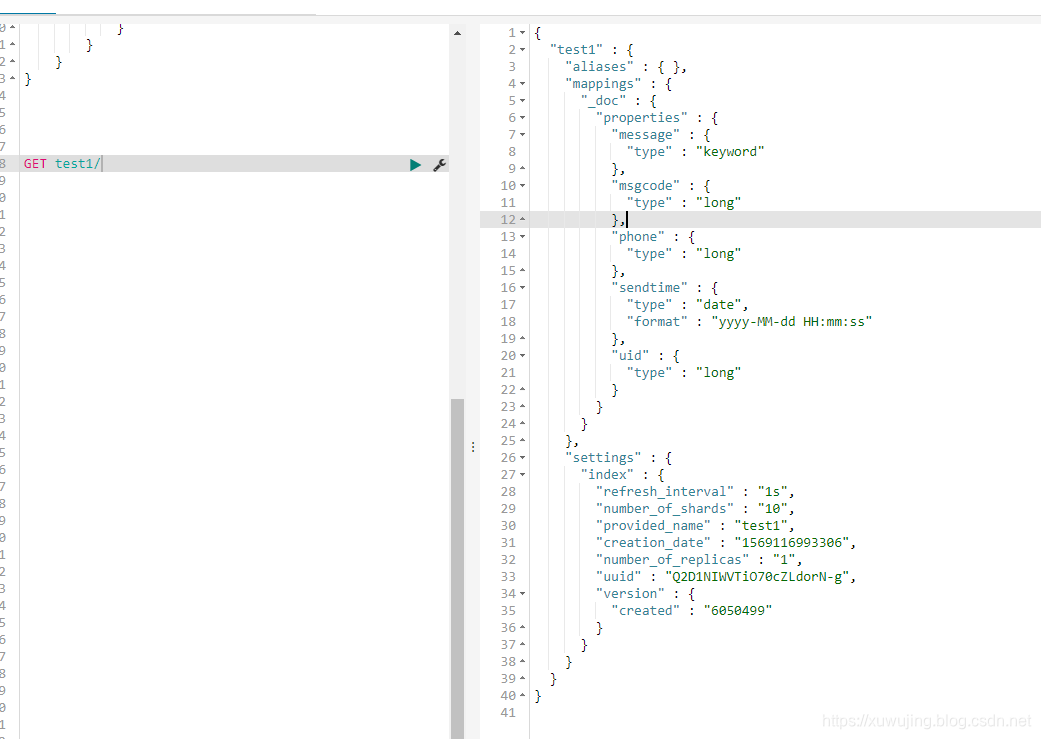
注:
- number_of_shards: 是设置的分片数,设置之后无法更改!
- refresh_interval: 是设置es缓存的刷新时间,如果写入较为频繁,但是查询对实时性要求不那么高的话,可以设置高一些来提升性能。可以更改
- number_of_replicas : 是设置该索引库的副本数,建议设置为1以上。
其中这里还有几个重要参数也顺便说一下:
- store: true/false 表示该字段是否存储,默认存储。
- doc_values: true/false 表示该字段是否参与聚合和排