有这样一个场景,在HBase中需要分页查询,同时根据某一列的值进行过滤。
不同于RDBMS天然支持分页查询,HBase要进行分页必须由自己实现。据我了解的,目前有两种方案, 一是《HBase权威指南》中提到的用PageFilter加循环动态设置startRow实现,详细见这里。但这种方法效率比较低,且有冗余查询。因此京东研发了一种用额外的一张表来保存行序号的方案。 该种方案效率较高,但实现麻烦些,需要维护一张额外的表。
不管是方案也好,人也好,没有最好的,只有最适合的。
在我司的使用场景中,对于性能的要求并不高,所以采取了第一种方案。本来使用的美滋滋,但有一天需要在分页查询的同时根据某一列的值进行过滤。根据列值过滤,自然是用SingleColumnValueFilter(下文简称SCVFilter)。代码大致如下,只列出了本文主题相关的逻辑,
Scan scan = initScan(xxx); FilterList filterList=new FilterList(); scan.setFilter(filterList); filterList.addFilter(new PageFilter(1)); filterList.addFilter(new SingleColumnValueFilter(FAMILY,ISDELETED, CompareFilter.CompareOp.EQUAL, Bytes.toBytes(false)));
数据如下
row1 column=f:content, timestamp=1513953705613, value=content1 row1 column=f:isDel, timestamp=1513953705613, value=1 row1 column=f:name, timestamp=1513953725029, value=name1 row2 column=f:content, timestamp=1513953705613, value=content2 row2 column=f:isDel, timestamp=1513953744613, value=0 row2 column=f:name, timestamp=1513953730348, value=name2 row3 column=f:content, timestamp=1513953705613, value=content3 row3 column=f:isDel, timestamp=1513953751332, value=0 row3 column=f:name, timestamp=1513953734698, value=name3
在上面的代码中。向scan添加了两个filter:首先添加了PageFilter,限制这次查询数量为1,然后添加了一个SCVFilter,限制了只返回isDeleted=false的行。
上面的代码,看上去无懈可击,但在运行时却没有查询到数据!
刚好最近在看HBase的代码,就在本地debug了下HBase服务端Filter相关的查询流程。
Filter流程
首先看下HBase Filter的流程,见图:
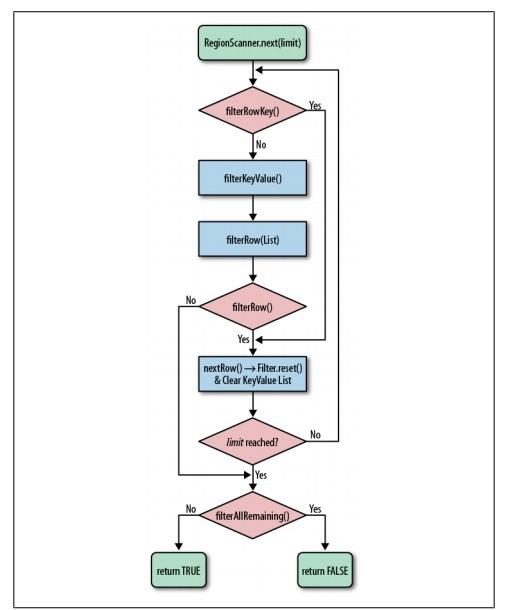
然后再看PageFilter的实现逻辑。
public class PageFilter extends FilterBase { private long pageSize = Long.MAX_VALUE; private int rowsAccepted = 0; /** * Constructor that takes a maximum page size. * * @param pageSize Maximum result size. */ public PageFilter(final long pageSize) { Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize); this.pageSize = pageSize; } public long getPageSize() { return pageSize; } @Override public ReturnCode filterKeyValue(Cell ignored) throws IOException { return ReturnCode.INCLUDE; } public boolean filterAllRemaining() { return this.rowsAccepted >= this.pageSize; } public boolean filterRow() { this.rowsAccepted++; return this.rowsAccepted > this.pageSize; } }
其实很简单,内部有一个计数器,每次调用filterRow的时候,计数器都会+1,如果计数器值大于pageSize,filterrow就会返回true,那之后的行就会被过滤掉。
再看SCVFilter的实现逻辑。
public class SingleColumnValueFilter extends FilterBase { private static final Log LOG = LogFactory.getLog(SingleColumnValueFilter.class); protected byte [] columnFamily; protected byte [] columnQualifier; protected CompareOp compareOp; protected ByteArrayComparable comparator; protected boolean foundColumn = false; protected boolean matchedColumn = false; protected boolean filterIfMissing = false; protected boolean latestVersionOnly = true; /** * Constructor for binary compare of the value of a single column. If the * column is found and the condition passes, all columns of the row will be * emitted. If the condition fails, the row will not be emitted. * <p> * Use the filterIfColumnMissing flag to set whether the rest of the columns * in a row will be emitted if the specified column to check is not found in * the row. * * @param family name of column family * @param qualif