ShadingSphere
?ShardingSphere是一款起源于当当网内部的应用框架,2015年在当当网内部诞生,2016年由主要开发人员张亮带入京东数科,在国内经历了当当网、电信翼支付、京东数科等多家大型互联网企业的考验,在2017年开源。
并逐渐由原本只关注于关系型数据库增强工具的ShardingJDBC升级成为一整套以数据分片为基础的数据生态圈,更名为ShardingSphere;在2020年4月,成为Apache软件基金会顶级项目
Apache ShardingSphere 产品定位为 Database Plus,旨在构建多模数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere 站在数据库的上层视角,关注他们之间的协作多于数据库自身。
连接、增量 和 可插拔 是 Apache ShardingSphere` 的核心概念。
-
连接:通过对数据库协议、SQL方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库; -
增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能; -
可插拔:项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。

Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
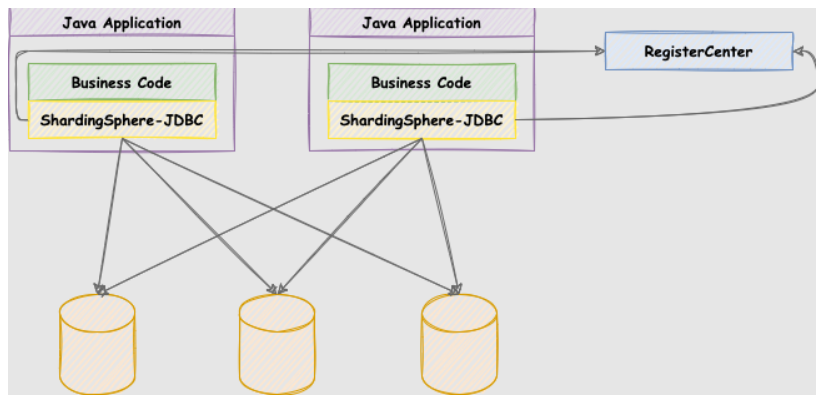
ShardingSphere-JDBC
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
-
适用于任何基于
JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用JDBC; -
支持任何第三方的数据库连接池,如:
DBCP,C3P0,BoneCP,HikariCP等; -
支持任意实现
JDBC规范的数据库,目前支持MySQL,PostgreSQL,Oracle,SQLServer以及任何可使用JDBC访问的数据库。
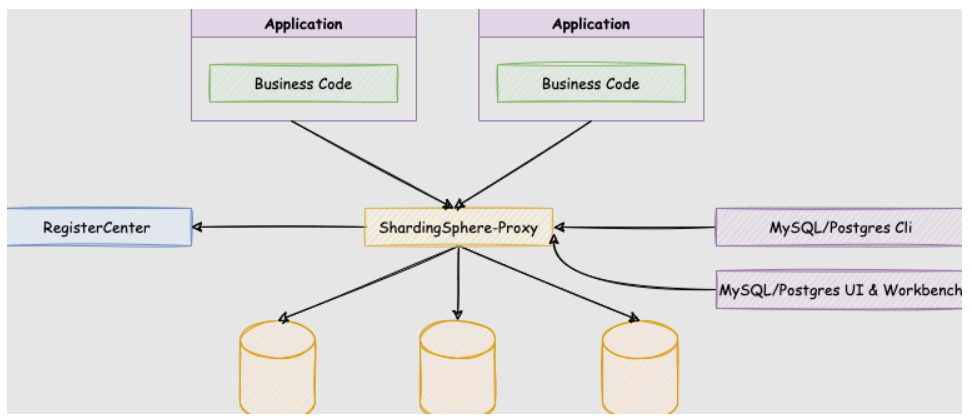
ShardingSphere-Proxy
ShardingSphere-Proxy 是 Apache ShardingSphere 的第二个产品。 它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
-
向应用程序完全透明,可直接当做
MySQL/PostgreSQL使用。 -
适用于任何兼容
MySQL/PostgreSQL协议的的客户端。
| 项目说明 | ShardingSphere-JDBC | ShardingSphere-Proxy |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
ShardingSphere-Proxy 的优势在于对异构语言的支持,以及为 DBA 提供可操作入口。
ShadingJDBC使用
① 分片
一般我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过 分库策略、分片策略 将数据分散到不同的数据库、表内。
② 数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
③ 逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。

④ 真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
⑤ 分片键
用于分片的数据库字段。我们将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。

⑥ 分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。

分片算法和分片策略的关系
sharding-jdbc 提供了4种分片算法:
1:精确分片算法
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
2:范围分片算法
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
3:复合分片算法
复合分片算法(ComplexKeysShardingAlgorith