当应用开始脱离单机运行和访问时,服务发现就诞生了。目前的网络架构是每个主机都有?个独立的 IP 地址,服务发现基本都是通过某种方式获取到服务所部署的 IP 地址。
DNS 协议是最早将?个网络名称翻译为网络 IP 的协议,在最初的架构选型中,DNS+LVS+Nginx 基本满足所有 RESTful 服务的发现,此时服务的 IP 列表通常配置在 nginx 或 LVS。后来出现 RPC 服务,服务的上下线更加频繁,人们开始寻求?种能够支持动态上下线并且推送 IP 列表变化的注册中心产品。
互联网软件行业普遍热捧开源产品,因为开源产品代码透明、可以参与共建、有社区进行交流和学习,当然更重要是免费。个人开发者或者中小型公司往往会将开源产品作为选型首选。
1 开源产品
1.1 Zookeeper
经典服务注册中心产品(虽然它最初的定位并不在于此),在很长?段时间里,是国人在提起 RPC 服务注册中心时心里想到的唯?选择,这很大程度上与 Dubbo 在中国的普及程度有关。
1.2 Consul 和 Eureka
都出现于 2014 年:
- Consul 在设计上把很多分布式服务治理上要用到的功能都包含在内,可以支持服务注册、健康检查、配置管理、Service Mesh 等
- Eureka借微服务概念流行,与 SpringCloud 生态的深度结合,也获取了大量的用户
1.3 Nacos
则携带着阿里巴巴大规模服务生产经验,试图在服务注册和配置管理这个市场上,提供给用户?个新的选择。
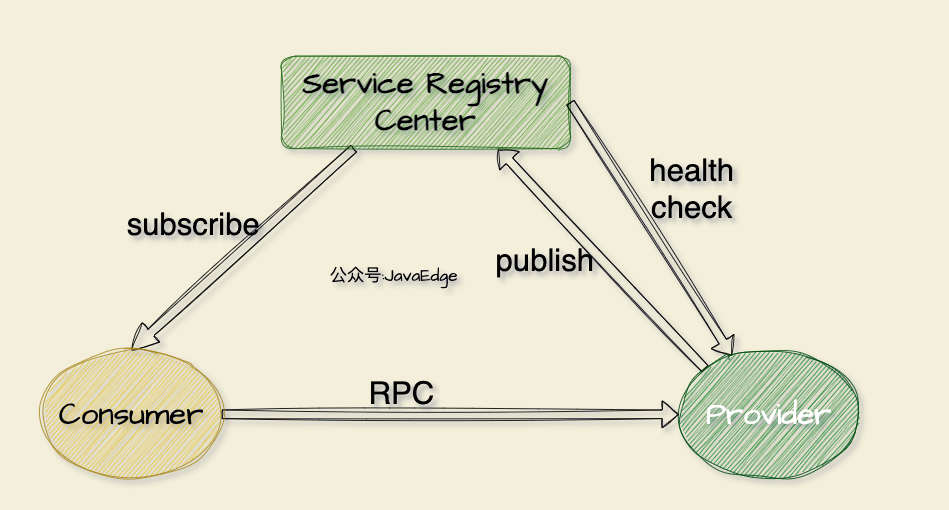
图 1 服务发现:
1.4 开源产品的优势
开发人员可以去阅读源代码,理解产品的功能设计和架构设计,同时也可以通过本地部署来测试性能,随之而来的是各种产品的对比文章。
不过当前关于注册中心的对比,往往停留在表面的功能对比上,对架构或者性能并没深入探讨。
1.5 痛点
是服务注册中心往往隐藏在服务框架背后,作为默默支持的产品。优秀的服务框架往往支持多种配置中心,但是注册中心的选择依然强关联与服务框架,?种普遍的情况是?种服务框架会带?个默认的服务注册中心。这样虽然免去了用户在选型上的烦恼,但是单个注册中心的局限性,导致用户使用多个服务框架时,必须部署多套完全不同的注册中心,这些注册中心之间的数据协同也是?个问题。
本文从各个角度深度介绍 Nacos 注册中心的设计原理,并试图从我们的经验和调研中总结和阐述服务注册中心产品设计上应该去遵循和考虑的要点。
2 数据模型
注册中心的核心数据:
- 服务的名字
- 它对应的网络地址
当服务注册了多个实例时,我们需要对不健康的实例过滤或针对实例的?些特征进行流量分配,就需要在实例存储?些如健康状态、权重等属性。随服务规模扩大,渐渐的又需要在整个服务级别设定?些权限规则、以及对所有实例都生效的?些开关,于是在服务级别又会设立?些属性。再往后,我们又发现单个服务的实例又会有划分为多个子集的需求,例如?个服务是多机房部署的,那么可能需要对每个机房的实例做不同的配置,这样又需要在服务和实例之间再设定?个数据级别。
对比
- Zookeeper 没有针对服务发现设计数据模型,它的数据是以?种更加抽象的树形 K-V 组织的,因此理论上可以存储任何语义的数据
- Eureka 或者 Consul 都做到实例级的数据扩展,可满足大部分的场景,不过无法满足大规模和多环境的服务数据存储
- Nacos 在经过内部多年生产经验后提炼出的数据模型,则是?种服务-集群-实例的三层模型。基本满足服务在所有场景下的数据存储和管理。
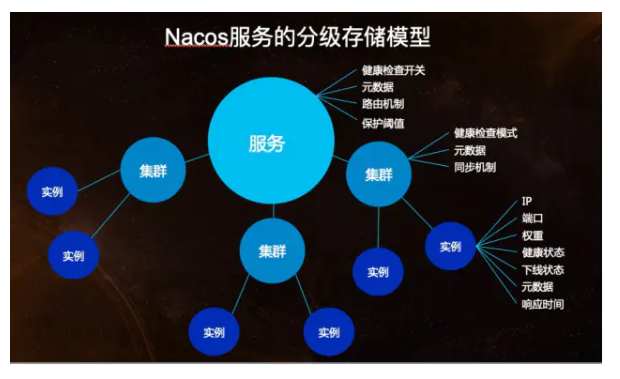
Nacos 的数据模型虽然相对复杂,但它不强制你使用它里面的所有数据,在大多数场景下,你可以选择忽略这些数据属性,此时可降维成和 Eureka 和 Consul ?样的数据模型。
数据的隔离模型
作为?个共享服务型的组件,需要能够在多个用户或者业务方使用情况下,保证数据的隔离和安全,这在稍微大?点的业务场景中非常常见。另?方面服务注册中心往往会支持云上部署,此时就要求服务注册中心的数据模型能够适配云上的通用模型。
Zookeeper、Consul 和 Eureka 在开源层面都没有很明确的针对服务隔离的模型,Nacos 则在?开始就考虑到如何让用户能够以多种维度进行数据隔离,同时能够平滑的迁移到阿里云上对应的商业化产品。
图 3 服务的四层的数据逻辑隔离模型:
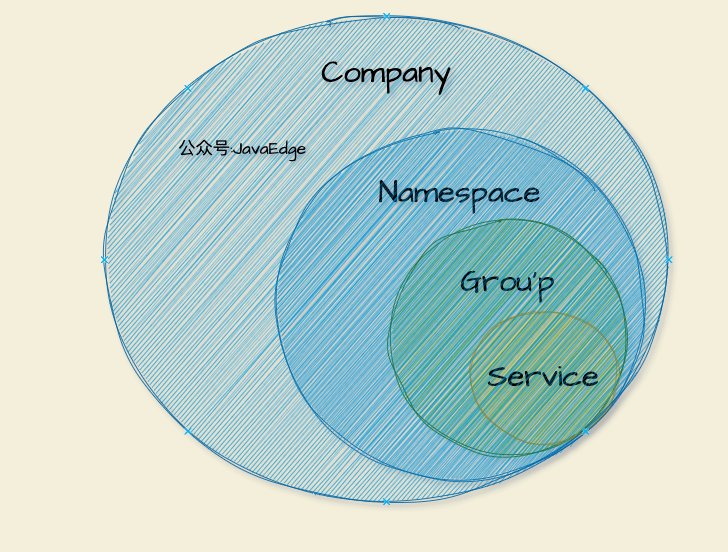
用户账号对应可能是?个企业或独立的个体,这个数据?般情况不会透传到服务注册中心。?个用户账号可新建多个命名空间,每个命名空间对应?个客户端实例,这个命名空间对应的注册中心物理集群是可以根据规则进行路由的,这样可以让注册中心内部的升级和迁移对用户无感知,同时根据用户的级别,为用户提供不同服务级别的物理集群。
再往下是服务分组和服务名组成的二维服务标识,可以满足接口级别的服务隔离。
Nacos 1.0.0 介绍的另外?个新特性是:临时实例和持久化实例。在定义上区分临时实例和持久化实例的关键是健康检查的方式。临时实例使用客户端上报模式,而持久化实例使用服务端反向探测模式。临时实例需要能够自动摘除不健康实例,而且无需持久化存储实例,那么这种实例就适用于类 Gossip 的协议。右边的持久化实例使用服务端探测的健康检查方式,因为客户端不会上报心跳,那么自然就不能去自动摘除下线的实例。
图 4 临时实例和持久化实例:
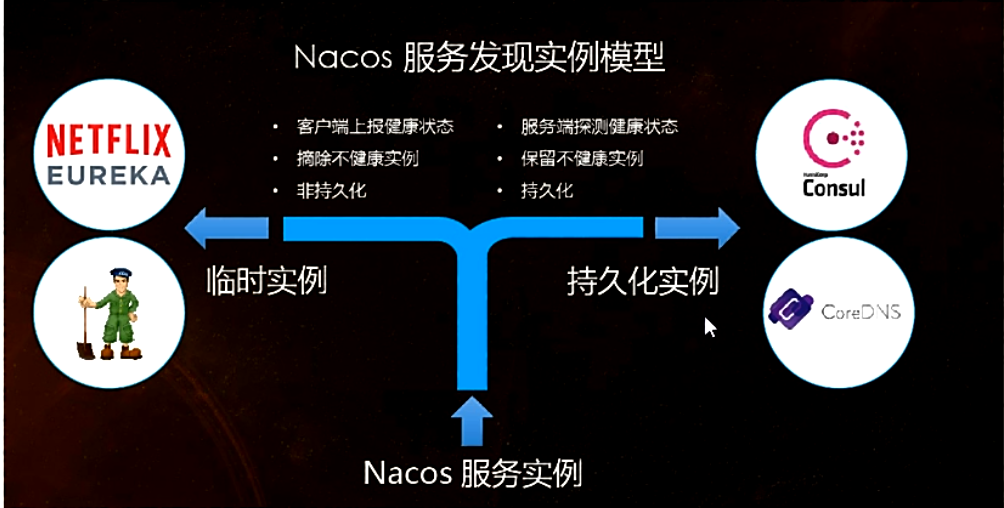
大中型公司,这两种类型的服务都有:
- ?些基础组件如数据库、缓存等,这些往往不能上报心跳,这种类型的服务在注册时,就需要作为持久化实例注册
- 上层的业务服务,例如微服务或者 Dubbo 服务,服务的 Provider 端支持添加汇报心跳的逻辑,可使用动态服务的注册方式
Nacos 2.0 沿用持久化及非持久化的设定,但有调整。Nacos 1.0 中持久化及非持久化的属性是作为实例的?个元数据进行存储和识别。导致同?个服务下可同时存在持久化实例和非持久化实例。但实际使用中,这种模式:
- 会给运维人员带来极大的困惑和运维复杂度
- 从系统架构来看,?个服务同时存在持久化及非持久化实例的场景也是存在?定矛盾
导致该能力事实上未被广泛使用。为简化 Nacos 的服务数据模型,降低运维复杂度,提升 Nacos 易用性,在 Nacos2.0 中:
- 是否持久化的数据抽象至服务级别
- 不再允许?个服务同时存在持久化实例和非持久化实例,实例的持久化属性继承自服务的持久化属性
3 数据?致性
分布式系统永恒话题,协议层面上看,?致性的选型已经很长时间没有新的成员加入了。目前来看基本
可归两家:
- 基于 Leader 的非对等部署的单点写?致性
- 对等部署的多写?致性
选用服务注册中心,没有?种协议能覆盖所有场景,如:
- 当注册的服务节点不会定时发送心跳到注册中心时,强?致协议看起来是唯?的选择,因为无法通过心跳来进行数据的补偿注册,第?次注册就必须保证数据不会丢失
- 而当客户端会定时发送心跳来汇报健康状态时,第?次的注册的成功率并不是非常关键(当然也很关键,只是相对来说我们容忍数据的少量写失败),因为后续还可以通过心跳再把数据补偿上来,此时 Paxos 协议的单点瓶颈就会不太划算了,这也是Eureka 为什么不采用 Paxos 协议而采用自定义的 Renew 机制
这两种数据?致性协议有各自使用场景,对服务注册需求不同,就会导致使用不同协议。Zookeeper 在 Dubbo 体系下表现出的行为,其实采用 Eureka 的 Renew 机制