ic = json.load(f)
print('%s查询结果 : %s张余票'%(user,dic['count']))
def buy_ticket(user,lock):
# with lock: # 相当于lock.acquire() + lock.release()
# lock.acquire() # 给这段代码加上一把锁
time.sleep(0.02)
with open('ticket_count') as f:
dic = json.load(f)
if dic['count'] > 0:
print('%s买到票了'%(user))
dic['count'] -= 1
else:
print('%s没买到票' % (user))
time.sleep(0.02)
with open('ticket_count','w') as f:
json.dump(dic,f)
# lock.release() # 给这段代码解锁
def task(user, lock):
search_ticket(user)
with lock:
buy_ticket(user, lock)
if __name__ == '__main__':
lock = Lock()
for i in range(10):
p = Process(target=task,args=('user%s'%i,lock))
p.start()
在进程中需要加锁的场景:
- 共享的数据资源(文件、数据库)
- 对资源进行修改、删除操作
加锁之后能够保证数据的安全性 但是也降低了程序的执行效率
9. 进程之间的通信
进程之间的数据是隔离的
from multiprocessing import Process
n = 100
def func():
global n
n -= 1
if __name__ == '__main__':
p_l = []
for i in range(10):
p = Process(target=func)
p.start()
p_l.append(p)
for p in p_l:p.join()
print(n)
# 主进程数据中的变量的值 不会随着 子进程数据中变量值的修改而改变
进程之间的通信 - IPC(inter process communication)
Queue 队列
Queue 天生就是数据安全的
Queue 基于文件家族的socket执行的,基于 pickle操作的,基于 lock实现的。
from multiprocessing import Queue,Process
# 先进先出
def func(exp,q):
ret = eva l(exp)
q.put({ret,2,3})
q.put(ret*2)
q.put(ret*4)
if __name__ == '__main__':
q = Queue()
Process(target=func,args=('1+2+3',q)).start()
print(q.get())
print(q.get())
print(q.get())
Pipe 管道
队列 = 管道 + 锁
import queue
from multiprocessing import Queue
q = Queue(5)
q.put(1)
q.put(2)
q.put(3)
q.put(4)
q.put(5) # 当队列为满的时候再向队列中放数据 队列会阻塞
print('5555555')
try:
q.put_nowait(6) # 当队列为满的时候再向队列中放数据,会报错并且会丢失数据(不安全,不建议使用)
except queue.Full:
pass
print('6666666')
print(q.get())
print(q.get())
print(q.get()) # 在队列为空的时候会发生阻塞
print(q.get()) # 在队列为空的时候会发生阻塞
print(q.get()) # 在队列为空的时候会发生阻塞
try:
print(q.get_nowait()) # 在队列为空的时候 直接报错
except queue.Empty:pass
IPC机制:
- 内置模块(基于文件):Queue队列、Pipe管道
- 第三方工具(软件)提供给我们的IPC机制(基于网络):redis / memcache / kafka / rabbitmq 发挥的都是消息中间件的功能
第三方IPC的优点:
队列:进程之间数据安全
管道:进程之间数据不安全
10. 解耦
解耦 :修改 复用 可读性
程序的解耦:把写在一起的大的功能分开成多个小的功能处理(如:登陆 注册)
生产者消费者模型:
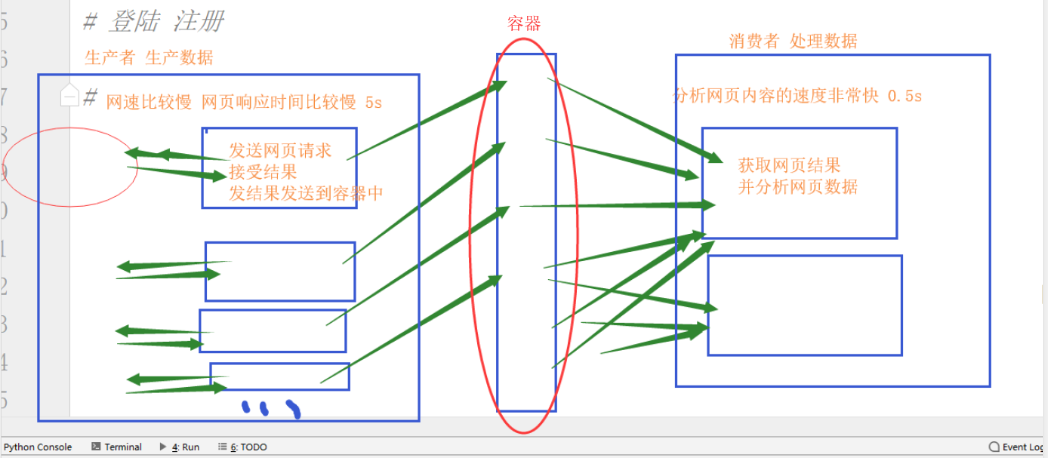
什么是生产者消费者模型?
把一个产生数据并且处理数据的过程解耦,让生产数据的过程和处理数据的过程达到一个工作效率上的平衡。
中间的容器,在多进程中我们使用队列或者可被join的队列,做到控制数据的量:
- 当数据过剩的时候,队列的大小会控制这生产者的行为
- 当数据严重不足的时候,队列会控制消费者的行为
- 并且我们还可以通过定期检查队列中元素的个数来调节生产者消费者的个数
比如说:一个爬虫或者一个web程序的server端
import time
import random
from multiprocessing import Process,Queue
def producer(q,name,food):
for i in range(10):
time.sleep(random.random())
fd = '%s%s'%(food,i)
q.put(fd)
print('%s生产了一个%s'%(name,food))
def consumer(q,name):
while True:
food = q.get()
if not food:break
time.sleep(random.randint(1,3))
print('%s吃了%s'%(name,food))
def cp(c_count,p_count):
q = Queue(10)
for i in range(c_count):
Process(target=consumer, args=(q, 'alex')).start()
p_l = []
for i in range(p_count):
p1 = Process(target=producer, args=(q, 'wusir', '烧饼'))
p1.start()
p_l.append(p1)
for p in p_l:p.join()
for i in range(c_count):
q.put(None)
if __name__ == '__main__':