ФЪЅІКцfileinputДЈїйЦ®З°Ј¬КЧПИЛµТ»ПВpythonДЪЦГµДОДјюAPIЎЄopen()єЇКэТФј°УлЖдПа№ШµДєЇКэЎЈ
ОТХвАпЦчТЄЅІЅІЖдЦРЛДёц±ИЅПЦШТЄєНіЈУГµД·Ѕ·ЁЈ¬ёь¶аµД·Ѕ·ЁЈ¬їЙТФІОїјЈєІЛДсЅМіМhttp://www.runoob.com/python/file-methods.html
ЈЁ1Ј©file = open(file_name [, access_mode][, buffering])
ІОКэЅвОцЈє
1. file_nameЈє
file_name±дБїКЗТ»ёцРиТЄ·ГОКµДОДјюГыіЖµДЧЦ·ыґ®ЦµЈ¬ФЪУ¦УГЦРРиТЄУГµҐТэєЕ»тХЯЛ«ТэєЕЅ«ОДјюГы°ь№ьЖрАґЎЈ
2. access_modeЈє
access_modeѕц¶ЁБЛґтїЄОДјюµДДЈКЅЈєЦ»¶БЈ¬РґИлЈ¬Ч·јУµИЎЈХвёцІОКэКЗ·ЗЗїЦЖµДЈ¬Д¬ИПОДјю·ГОКДЈКЅОЄЦ»¶Б(r)
ПкПёДЈКЅїЙТФІОїјЈєІЛДсЅМіМhttp://www.runoob.com/python/python-files-io.html
3. bufferingЈє
ХвёцІОКэУГУЪЙиЦГ»єґжЗшµДґуРЎЎЈИз№ыbufferingµДЦµ±»ЙиОЄ0Ј¬ѕНІ»»бУР»єґжЎЈИз№ыbufferingµДЦµИЎ1Ј¬·ГОКОДјюК±»бјДґжРРЎЈИз№ыЅ«bufferingµДЦµЙиОЄґуУЪ1µДХыКэЈ¬ХвёцХыКэѕНОЄ»єґжЗшµД»єґжґуРЎЎЈИз№ыИЎёєЦµЈ¬јДґжЗшµД»єіеґуРЎФтОЄПµНіД¬ИПЎЈ
ЈЁ2Ј©file.flush()·Ѕ·Ё
УГУЪЛўРВ»єіеЗшЈ¬Ј¬јґЅ«»єіеЗшЦРµДКэѕЭБўїМРґИлОДјюЈ¬Н¬К±ЗеїХ»єіеЗш
flush()·Ѕ·ЁФЪЕАіжЦРТІУГµГН¦¶аЈ¬ФЪЕАіж№эіМУЙУЪЦЦЦЦФТтЈ¬іМРтЦР¶ПЈ¬РґИл»єґжµДКэѕЭГ»УРРґИлґЕЕМєЬїЙП§Ј¬ЛщТФїЙТФКЦ¶ЇМнјУflush()·Ѕ·Ё
ЈЁ3Ј©file.close()·Ѕ·Ё
№Ш±ХОДјюЈ¬ІўЅ«»єіеЗшµДКэѕЭРґИлОДјюЦРЎЈ
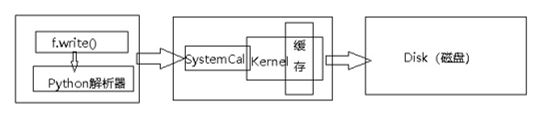
ОДјюµД»єґж»ъЦЖ
ФЪРґИлОДјюДЪИЭµДК±єтЈ¬ФЪОТГЗµчУГpythonµДwrite()єЇКэ¶ФОДјюЅшРРРґИлµДК±єтЈ¬pythonЅвОцЖч»бµчУГІЩЧчПµНіµДwrite·Ѕ·ЁЈ¬µ«ЦµµГЧўТвµДКЗЈ¬І»КЗВнЙП±ЈґжµЅґЕЕМЦРµДЈ¬КЗПИРґµЅДЪєЛµД»єіеЗшАпГжЈ¬Ц»УРµ±ОТГЗЦч¶ЇµчУГflush()єЇКэ»тХЯclose()єЇКэµДК±єтЈ¬ІЕ»бЅ«»єіеЗшµДДЪИЭРґИлґЕЕМЦРЎЈБнНвµ±РґИлµДКэѕЭБїґуУЪ»тХЯµИУЪ»єіеЗшµДґуРЎµДК±єтЈ¬Рґ»єіе»бЧФ¶ЇН¬ІЅµЅґЕЕМЎЈ
АэИзЈє
Рґ20НтРРКэѕЭЅб№ы
file = open('file1.txt','a+') for i in range(200000): file.write('this line is line%s'%i) file.write('\r\n')
pycharm±ЁіцИзПВµДМбКѕ
![]()

ТтОЄОТЙиЦГµДbufferingКЗД¬ИПµДПµНіµД»єґжґуРЎЈ¬ЛщТФµ±РґµЅ1999856РРК±Ј¬ѕНёХєГµЅПµНіµД»єґжЗшґуРЎЈ¬ТтОЄЛщРиТЄРґµДКэѕЭґуУЪ»єґжЗшµДґуРЎЈ¬ЛщТФХвР©ДЪИЭЦ±ЅУѕНРґИлБЛґЕЕМЈ¬¶ш1998856єуГжµДКэѕЭФЪРґИлµДК±єт»№КЗПИРґµЅБЛ»єґжЗшЦРЈ¬¶шХвР©КэѕЭµДґуРЎПФИ»КЗРЎУЪ»єґжЗшґуРЎµДЈ¬ЛщТФ±»±ЈґжФЪ»єґжЗшЦРЈ¬ІўГ»УРРґµЅґЕЕМЎЈ
К№УГflush()·Ѕ·ЁєуЈ¬ЛщУРФЪ»єґжЗшµДКэѕЭ¶ј»бРґИлµЅґЕЕМЦР

Из№ыОТЦ±ЅУФЪµчУГopen()·Ѕ·ЁµДК±єтПсПВГжХвСщЙиЦГbufferingОЄ1Ј¬ѕНОЮРиµЈРД»єґжµДОКМвБЛ
ЈЁ4Ј©file.seek(offset [,whence]) ОДјюЦёХл
µ±ОДјюЅшРРРґИл»тХЯ¶БИЎµДК±єтЈ¬ОДјюЦёХл»бёщѕЭѕЯМеµДДЪИЭЅшРРТЖ¶ЇЎЈ
ІОКэЅвОцЈє
offsetЈєЖ«ТЖБїЈ¬ґъ±нРиТЄТЖ¶ЇЖ«ТЖµДЧЦЅЪКэ
whenceЈєїЙСЎІОКэЈ¬Д¬ИПЦµОЄ 0ЎЈЧчУГКЗёшoffsetІОКэЙи¶ЁЖрКјЦµЈ¬±нКѕТЄґУДДёцО»ЦГїЄКјЖ«ТЖЎЈ0ґъ±нґУОДјюїЄН·їЄКјЛгЖрЈ¬1ґъ±нґУµ±З°О»ЦГїЄКјЛгЖрЈ¬2ґъ±нґУОДјюД©ОІЛгЖрЎЈ
АэИзТФПВ°ёАэЈє
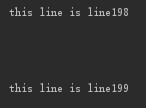
file = open('file.txt','a+',1) for i in range(200): file.write('this line is line%s'%i) file.write('\r\n') for line in file: print(line) file.close()
ЦХ¶ЛГ»УРґтУЎИОєОКэѕЭ
Из№ыЅ«ґъВлЛіРтРЮёДТ»ПВ
file = open('file.txt','a+',1) for i in range(200): file.write('this line is line%s'%i) file.write('\r\n') file.close() f = open('file.txt','r+') for line in f: print(line) f.close()
ЦХ¶ЛґтУЎіцКэѕЭ
ДЗГґФхГґУГseek()·Ѕ·ЁДШЈї
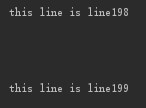
import os file = open('file.txt','a+',1) for i in range(200): file.write('this line is line%s'%i) file.write('\r\n') file.seek(0,os.SEEK_SET) for line in file: print(line) file.close()
Н¬СщТІДЬґтУЎіцКэѕЭ
ЙПГжЈ¬ОТУГБЛosДЈїйµДSEEK_SET
osДЈїйУРХвР©ДЪИЭЈє
ЎЎos.SEEK_SETЈє±нКѕОДјюµДПа¶ФЖрКјО»ЦГ
os.SEEK_CURЈє±нКѕОДјюµДПа¶Фµ±З°О»ЦГ
ЎЎos.SEEK_ENDЈє±нКѕОДјюµДПа¶ФЅбКшО»ЦГ
№ШУЪfileinputДЈїй
fileinputїЙТФ¶ФОДјюЅшРРПёЦВ»ЇµДґ¦АнЈ¬±ИЦ±ЅУµДopen·Ѕ·ЁУРёь¶аОДјюІЩА©Х№ЎЈїЙТФТ»ґОРФµьґъТ»ёц»тХЯ¶аёцОДјюЈ¬Іў¶ФОДјюЅшРРРЮёДЎЈ
ЦчТЄµДєЇКэУРЈє
1. inputЈЁ[files[,inplace[,backup]]]Ј© °пЦъµьґъ¶аёцКдИлБчЦРµДРР
2. filename() ·µ»Шµ±З°ОДјюµДГыіЖ
3.nestfile() №Ш±Хµ±З°ОДјюІўТЖ¶ЇµЅПВТ»ёцОДјю
4. close() №Ш±ХРтБРЈЁ¶аёцОДјю
5. lineno() ·µ»ШЈЁ¶аёцОДјюАЫјЖµДЈ©µ±З°РРєЕ
6. filelineno() ·µ»ШФЪµ±З°ОДјюµДРРєГ
7. isfirstline() јмІйµ±З°КЗ·сКЗµ±З°ОДјюЦРµДµЪТ»РР
8. isstdin() јмІйЧоєуТ»РРКЗ·сАґЧФsys.stdin
їЙТФАнЅвЈ¬fileinputДЈїйЦШµгКЗ¶Ф¶аОДјюµД¶БИЎєНККµ±К±єтµДРЮёДЎЈ¶шГ»УРЦ±ЅУµДРґІЩЧч
1. input()·Ѕ·Ё
ХвёцєЇКэКЗfileinputДЈїйЦРЧоЦШТЄµДТ»ёцєЇКэЈ¬ІОКэПа¶ФёґФУТ»µгЎЈ
№Щ·ЅµД¶ЁТеЈє
fileinput.input([files[, inplace[, backup[, bufsize[, mode[, openhook]]]]]])

input(files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
1Ј©filesБР±нЈ¬їЙТФКЗТ»ёцОДјюЈ¬ТІїЙТФКЗ¶аёцОДјюµДБР±нРОКЅ
2Ј©inplace КЗ·с¶ФОДјюЅшРРѕНµШ